
使用 R 探索网页抓取
介绍
我们生活在一个数字世界,个人和组织都受到互联网的重大影响。数据科学家经常需要提取、处理和分析网络数据。这就是网络抓取发挥作用的地方,它是从互联网获取网络数据并从中提取信息的最流行和最有效的方法之一。
在本指南中,您将学习使用强大的编程语言 R 进行网络抓取的技术。
入门
第一步是导入所需的库。您将使用由 Hadley Wickham 编写和管理的rvest网页抓取包。rvest库有几个有用的函数可用于从网页中提取数据。
首先导入所需的库。
library(rvest)
library(stringr)
library(xml2)
下一步是创建一个包含要解析的网页数据的对象。在本指南中,您将在销售产品Samsung Galaxy S20 Ultra的亚马逊网页上执行网页抓取。
下面的第一行代码指定要抓取的网站的网址,而第二行从网站读取内容并将其存储在对象webdata中。read_html()函数用于从给定的 URL 抓取 HTML 内容。
url = https://www.amazon.in/dp/B08444S68Q/ref=pc_mcnc_merchandised-search-12_?pf_rd_s=merchandised-search-12&pf_rd_t=Gateway&pf_rd_i=mobile&pf_rd_m=A1VBAL9TL5WCBF&pf_rd_r=SPDFGAW43YWZW1YZYE1S&pf_rd_p=531f8832-1485-47d3-9dbc-5a9219e94407
webdata = read_html(url)
您已创建包含网站信息的对象,此对象将用于提取更多信息。首先检查网站登录页面的文本。这可以通过以下代码完成,其中包括两个函数:html_nodes()和html_text()。
html_nodes ()函数识别 HTML 包装器,而html_text()函数删除 HTML 标签并仅提取文本。
webdata %>%
html_nodes("p") %>%
html_text()
输出:
'Delivery Associate will place the order on your doorstep and step back to maintain a 2-meter distance.' 'No customer signatures are required at the time of delivery.' 'For Pay-on-Delivery orders, we recommend paying using Credit card/Debit card/Netbanking via the pay-link sent via SMS at the time of delivery. To pay by cash, place cash on top of the delivery box and step back.' 'Fulfilled by Amazon indicates that this item is stored, packed and dispatched from Amazon fulfilment centres. Amazon directly handles delivery, customer service and returns. Fulfilled by Amazon items can be identified with an badge. Orders containing items Fulfilled by Amazon worth Rs.499 or more are eligible for FREE delivery. FBA items may also be eligible for faster delivery (Same-Day, One-Day and Two-Day).' 'If you are a seller, Fulfilment by Amazon can help you grow your business. Learn more about the programme.' 'Sign in/Create a free business account ' '\n Find answers in product info, Q&As, reviews\n ' '\n Your question may be answered by sellers, manufacturers, or customers who purchased this item, who are all part of the Amazon community.\n ' '\n Please make sure that you\'ve entered a valid question. You can edit your question or post anyway.\n ' '\n Please enter a question.\n ' 'Galaxy S20 series introduce the next generation of mobile innovation. Completely redesigned to remove interruptions from your view. No notch, no distractions. Precise laser cutting, on-screen security, and a Dynamic AMOLED that\'s easy on the eyes make the Infinity-O Display the most innovative Galaxy screen yet. Use the Ultra Wide Camera to take stunning, cinematic photos with a 123 degree field of vision.\n\n' '\n With Space Zoom bolstered by AI, now you can get close up to the action like never before.\n ' '\n 8K Video Snap revolutionizes how you capture photos and videos\n ' '\n Single Take is essentially burst mode turned beast mode. With revolutionary AI, it lets you shoot for up to 10 seconds and get back a variety of formats — meaning you can choose the best style for the moment without having to reshoot.\n ' '\n In low light, the pro-grade camera system captures multiple photos at once, merging them into one stunning shot with less blur and noise. With larger image sensors and AI, switching to Night Mode means you can shoot night-time scenes clearer.\n ' '\n The HDR10+ certified Infinity-O Display offers an immersive viewing experience.\n ' '\n More playing, less waiting, thanks to powerful RAM and an enhanced processor with advanced AI.\n ' '\n Battery that is powerful as well as intelligent, adjusting to your mobile habits to last longer.\n ' '' ''
上面的输出显示了所有文本。接下来,您将提取网站的特定部分。
提取关键元素
使用相应的 HTML 标签可以轻松提取元素,例如产品标题。要查找特定标签的类,请右键单击元素并选择“检查”。下面显示了一个示例。
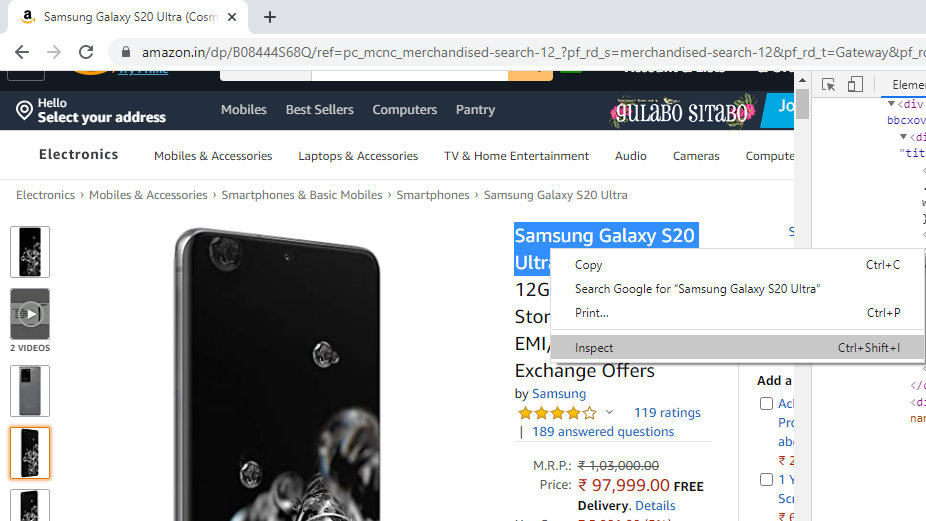
上述步骤将生成以下显示,其中提供了要提取的元素的ID。
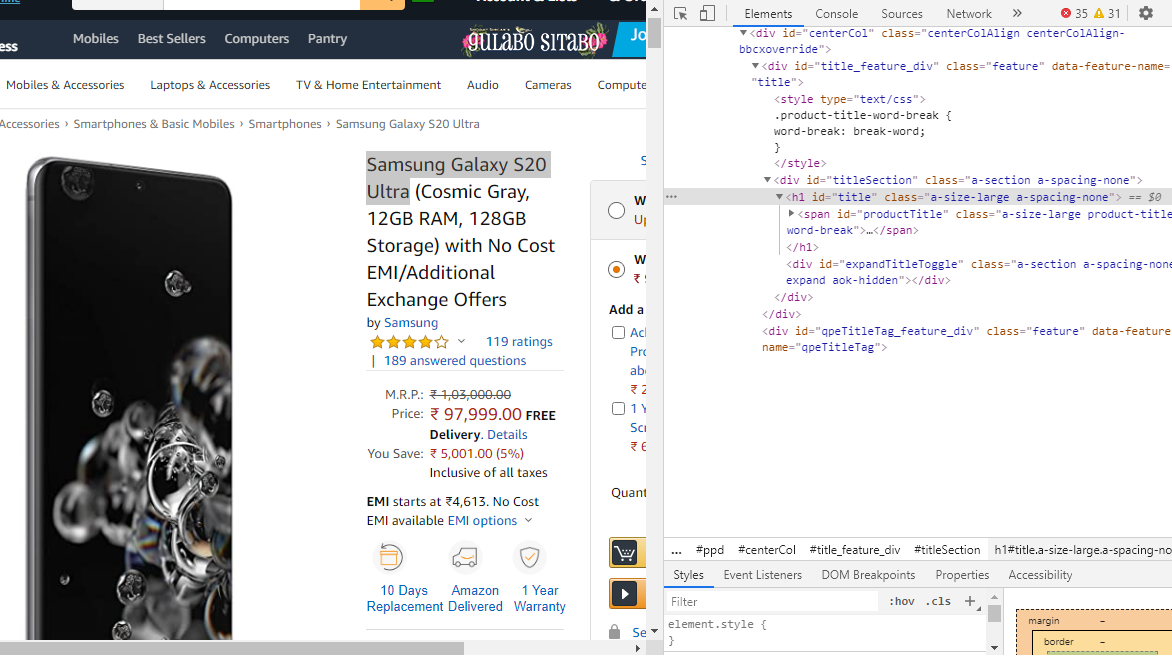
在下面的代码中,将标题的 ID 'h1#title'作为代码中的参数传递以提取产品的标题。
title_html <- html_nodes(webdata, 'h1#title')
title <- html_text(title_html)
head(title)
输出:
'\n\n\n\n\n\n\n\n\nSamsung Galaxy S20 Ultra (Cosmic Gray, 12GB RAM, 128GB Storage) with No Cost EMI/Additional Exchange Offers\n\n\n\n\n\n\n\n\n\n\n\n\n'
上面的输出提供了标题,但也打印了空格和不必要的字符。您可以使用str_replace_all()函数删除这些。
str_replace_all(title, "[\r\n]" , "")
输出:
Samsung Galaxy S20 Ultra (Cosmic Gray, 12GB RAM, 128GB Storage) with No Cost EMI/Additional Exchange Offers
接下来,提取产品的价格。价格的 HTML 类是span#priceblock_ourprice,下面的代码中使用它来提取产品价格。
price_html <- html_nodes(webdata, 'span#priceblock_ourprice')
price <- html_text(price_html)
str_replace_all(price, "[\r\n]" , "")
输出:
'₹ 97,999.00'
上面的输出显示了产品以印度货币表示的价格。接下来,提取产品描述。
desc_html <- html_nodes(webdata, 'div#productDescription')
prod_desc <- html_text(desc_html)
prod_desc <- str_replace_all(prod_desc, "[\r\n\t]" , "")
prod_desc <- str_trim(prod_desc)
head(prod_desc)
输出:
'Style name:with No Cost EMI/Additional Exchange Offers | Colour:Cosmic GrayGalaxy S20 series introduce the next generation of mobile innovation. Completely redesigned to remove interruptions from your view. No notch, no distractions. Precise laser cutting, on-screen security, and a Dynamic AMOLED that\'s easy on the eyes make the Infinity-O Display the most innovative Galaxy screen yet. Use the Ultra Wide Camera to take stunning, cinematic photos with a 123 degree field of vision.'
下一步是刮取产品的颜色,使用下面的代码完成。
color_html <- html_nodes(webdata, 'div#variation_color_name')
color_html <- html_nodes(color_html, 'span.selection')
color <- html_text(color_html)
color <- str_trim(color)
head(color)
输出:
'Cosmic Gray'
客户在网站上浏览产品时会关注的一个重要内容是产品评级。本例中评级的 HTML 类是span#acrPopover,在下面的代码中用作参数。
rate_html <- html_nodes(webdata, 'span#acrPopover')
rate <- html_text(rate_html)
rate <- str_replace_all(rate, "[\r\n\t]" , "")
rate <- str_trim(rate)
head(rate)
输出:
'4.0 out of 5 stars'
该产品的评分为五分之四,还算不错。但是,仅凭评分是不够的,还需要结合给出评分的客户数量来理解。这可以通过以下代码实现,其中 HTML 类为span#acrCustomerReviewText。
number_ratings <- html_nodes(webdata, 'span#acrCustomerReviewText')
number_ratings <- html_text(number_ratings)
number_ratings <- str_replace_all(number_ratings, "[\r\n\t]" , "")
number_ratings <- str_trim(number_ratings)
head(number_ratings)
输出:
'106 ratings'
结论
在本指南中,您学习了使用 R 进行网页抓取的方法。您还学习了如何提取、预处理和打印感兴趣的关键项目。
要了解有关使用“R”进行数据科学的更多信息,请参阅以下指南:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~