
使用 Azure 认知服务文本转语音服务教 Azure 说话
介绍
现代用户界面不仅限于键盘和鼠标。如今,我们可以使用视觉、手势甚至语音与应用交互。除非计算机可以回复,否则与计算机交谈毫无意义。这被称为文本转语音。如果这听起来像是一个难以解决的问题,那确实如此。但是,Microsoft Azure 提供了语音服务来帮助教会计算机说话。本指南将讨论如何使用 C# 编程语言开始使用 Microsoft Azure 语音服务。请记住,Azure 认知服务支持多种语言的 SDK,包括 C#、Java、Python 和 JavaScript,甚至还有一个可以从任何语言调用的 REST API。
设置
与所有 Azure 认知服务一样,在开始之前,请在 Azure 门户中配置语音服务实例。语音服务的功能远不止文本转语音。它还可以反转概念并转录音频文件。两者使用相同的语音服务。
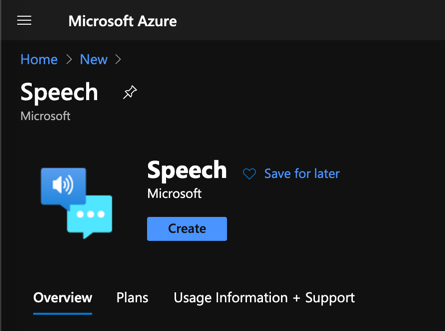
创建新的语音服务实例,选择 Azure 订阅和数据中心位置,然后选择或创建新的资源组。对于定价层,免费的 F0 选项足以进行实验。
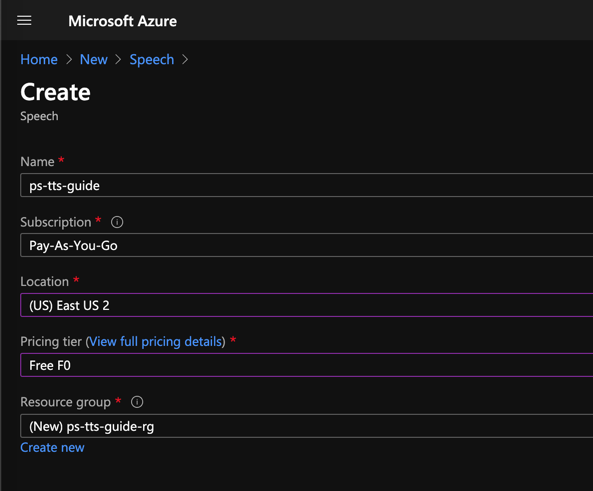
免费套餐允许您每月处理 500 万个字符。您还可以选择使用听起来更像人声但计算量更大的神经语音来生成语音。因此,神经语音的免费配额较低,每月仅为 50 万个字符。我们将在本指南的后面部分看到标准语音和神经语音之间的区别。有关免费和付费套餐的配额和定价的更多详细信息,请参阅Azure 语音服务文档。
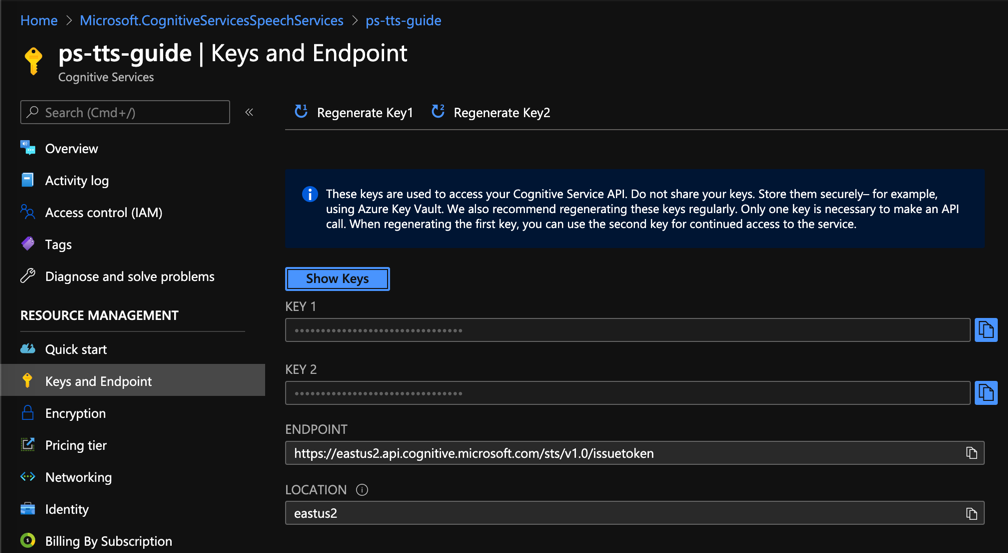
实例配置完成后,您将在左侧的密钥和端点菜单中看到用于访问服务的 API 密钥和端点。
准备 SDK
SDK 以 NuGet 包的形式分发。将Microsoft.CognitiveServices.Speech添加到 C# 项目,以在命令行中使用dotnet工具安装 SDK :
dotnet add package Microsoft.CognitiveServices.Speech --version 1.14.0
创建本指南时,最新版本是 1.14.0。
要使用 SDK 进行身份验证,您需要创建在Microsoft.CognitiveServices.Speech命名空间中找到的SpeechConfig实例。
using Microsoft.CognitiveServices.Speech;
使用终结点和 Azure 门户中的某个 API 密钥通过静态FromEndpoint方法创建新实例:
var speechConfig = SpeechConfig.FromEndpoint("{endpoint}", "{apikey}");
您还需要来自Microsoft.CognitiveServices.Speech.Audio命名空间的AudioConfig实例。
using Microsoft.CognitiveServices.Speech.Audio;
// ...
var audioConfig = AudioConfig.FromWavFileOutput("demo.wav");
有多种方法可以创建AudioConfig,包括流或直接到扬声器。对于此演示,最简单的方法是创建一个 .wav 文件。FromWavFileOutput方法接受生成的 .wav 文件的路径。
要生成语音文件,请从SpeechConfig和AudioConfig创建SpeechSynthesizer:
var speechSynthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
最后,调用SpeechSynthesizer上的SpeakTextAsync方法并提供将用于生成 .wav 文件的字符串。需要等待此方法。
await speechSynthesizer.SpeakTextAsync("Peter Piper picked a peck of pickled peppers.");
您可以在GitHub上收听生成的 .wav 文件。
自定义声音
默认情况下,SpeechConfig使用名为en-US-JessaRUS 的声音。这是女性声音。要获取男性声音,请将SpeechConfig的SpeechSynthesisVoiceName属性设置为en-US-GuyRUS。
speechConfig.SpeechSynthesisVoiceName = "en-US-GuyRUS";
您可以在GitHub上收听这个声音。
有超过 45 种语言的 75 多种语音可供选择。完整列表可在Azure 文档中找到。
使用 SSML
您可以使用 SSML(语音合成标记语言)生成更逼真的声音。这是一种不特定于语音服务的 XML 语法。它是 Azure、AWS、Google Cloud 等使用的标准。以下是示例 SSML 文档:
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I live in the zip code 10203.
</voice>
</speak>
<speak>和<voice>元素是所有 SSML 的样板。name属性是上一节中支持的语音之一。然后由SpeakSsmlAsync方法解析 SSML 。
SpeechSynthesizer ssmlSynthesizer = new SpeechSynthesizer(speechConfig, null);
var ssmlResult = await ssmlSynthesizer.SpeakSsmlAsync(ssml);
var audioDataStream = AudioDataStream.FromResult(ssmlResult);
await audioDataStream.SaveToWaveFileAsync("ssmldemo.wav");
请注意,ssmlSynthesizer不需要AudioConfig。此外,结果是从AudioDataStream检索的。您可以在GitHub上收听该文件。
它还正确地将邮政编码发音为“一零二零三”,而不是“一万二百零三”。如果我们在不同的上下文中使用相同的数字,会发生什么?
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I won 10203 dollars in the sweepstakes!
</voice>
</speak>
在GitHub上收听该文件。这次,我们期望相同的值发音为“ten million two hundred three”。但默认情况下并非如此。要获得正确的发音,请使用<say-as>元素并将explain-as属性设置为cardinal。
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I won <say-as interpret-as="cardinal">10203</say-as> dollars in the sweepstakes!
</voice>
</speak>
现在数字的发音与我们期望的一样。这是GitHub上正确的 .wav 文件。
有时你可能想停顿一下。在本示例中,你可能想在说完第一个句子后停顿很长时间,然后再说出“妙语”。
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I got the new XBox Series X for 1/2 off! <break time="2500ms" /> Just kidding.
</voice>
</speak>
这是GitHub上生成的 .wav 文件。<break>元素的时间属性包括 2,500 毫秒的静默时间。您也可以使用秒,例如4s。另外,请注意 .wav 文件中的“1/2”正确发音为“一半”。
神经声音
听起来还行,但不太真实。这就是神经语音的作用所在。神经语音是使用神经网络生成的,很难分辨出它们不是真人。由于它们是使用神经网络生成的,因此计算量更大,因此成本也更高。但结果是值得的。目前有大约 65 种神经语音,更多预览即将推出。
要使用神经语音,只需将SSML 中<voice>元素的名称属性设置为神经语音。
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-AriaNeural">
Peter Piper picked a peck of pickled peppers.
</voice>
</speak>
注意:如果您生成的 .wav 文件只有几个字节,请检查您创建语音服务实例的位置。神经语音仅在美国东部、东南亚和西欧可用。
这是在GitHub上生成的 .wav 文件。
还有更多选项可用于自定义神经语音的说话风格。例如,使用<mstts:express-as>元素,您可以将<fo
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~