

使用 Tidyverse 在 R 中进行探索性数据分析
介绍
探索性数据分析 (EDA) 并非基于一套规则或公式。它更像是对数据集的一种好奇状态。一开始,您可以自由地探索任何您认为有效的方向;之后,您的探索将取决于您可以应用于数据集的想法。
简而言之,探索性数据分析是一个迭代过程,可分为三个步骤:
- 生成有关数据的问题
- 对数据进行可视化、转换和建模以获取答案
- 利用你的学习提出更多问题
本指南将演示如何使用 Tidyverse 库,其中包含执行 EDA 所需的所有工具。
# installing and loading tidyverse
install.packages("tidyverse")
library(tidyverse)
提出问题
要了解数据,您必须提出问题。这些问题需要将您的注意力集中在数据集的特定部分。探索性数据分析是一个创造性的过程,它注重问题的质量而不是数量。但是,在刚开始时,提出高质量的问题是困难的。
然而,有几个问题对于开始分析迭代总是有帮助的:
- 变量内发生了哪些类型的变化?
- 变量之间发生什么类型的协变?
以下部分将在数据集中解决这两个问题。
变化
变量值的变化称为变异。在现实生活中,总会存在一些变异,因为在测量数量时总会存在一定量的误差。即使是分类变量也会出现变异。
观察变化的最有效方法是通过可视化变量的分布。这也可以称为单变量分析。如何可视化变量的分布取决于它是分类变量还是连续变量。
本指南将对以下数据集进行 EDA。
# Loading data
data("diamonds")
# Getting the column names from the dataset
colnames(diamonds)
"carat" "cut" "color" "clarity" "depth" "table" "price" "x" "y" "z"
# lets look at the sample data
head(diamonds)
# A tibble: 6 x 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
查看数据时,您可以确定变量是分类变量还是连续变量。通过绘制条形图查看变量的分布情况。
# Plotting a bar plot
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut))

在图中,您可以看到变量的分布。
现在,选择一个连续变量并绘制其分布。
ggplot(data = diamonds) +
geom_histogram(mapping = aes(x = carat), binwidth = 0.5)
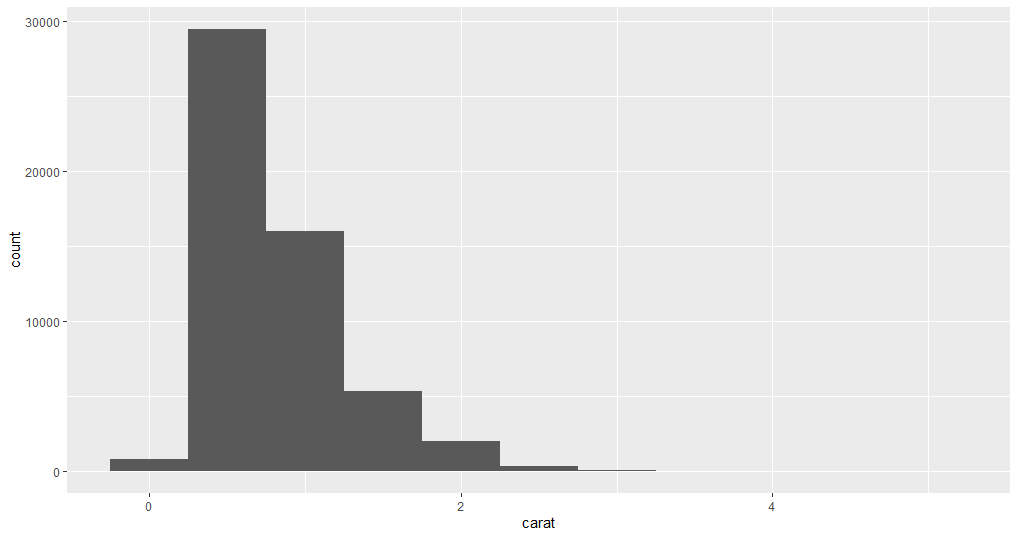
这里,binwidth参数用于设置直方图每条柱状图的数值范围,binwidth 越低,直方图显示的详细信息就越多。
ggplot(data = diamonds) +
geom_histogram(mapping = aes(x = carat), binwidth = 0.1)
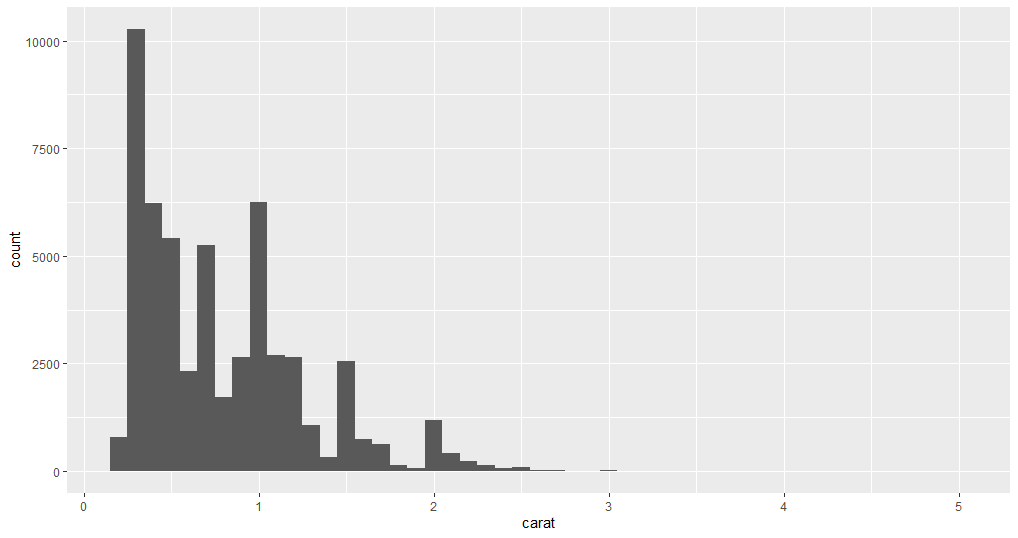
现在您已经分别分析了两个变量,假设您想知道每种切工的克拉值分布。您可以通过绘制这两个变量再次找到答案。下面的示例以两种不同的方式绘制数据点。
# Creating facets
ggplot(data = diamonds) +
geom_histogram(mapping = aes(x = carat), binwidth = 0.1)+
facet_wrap(~cut)
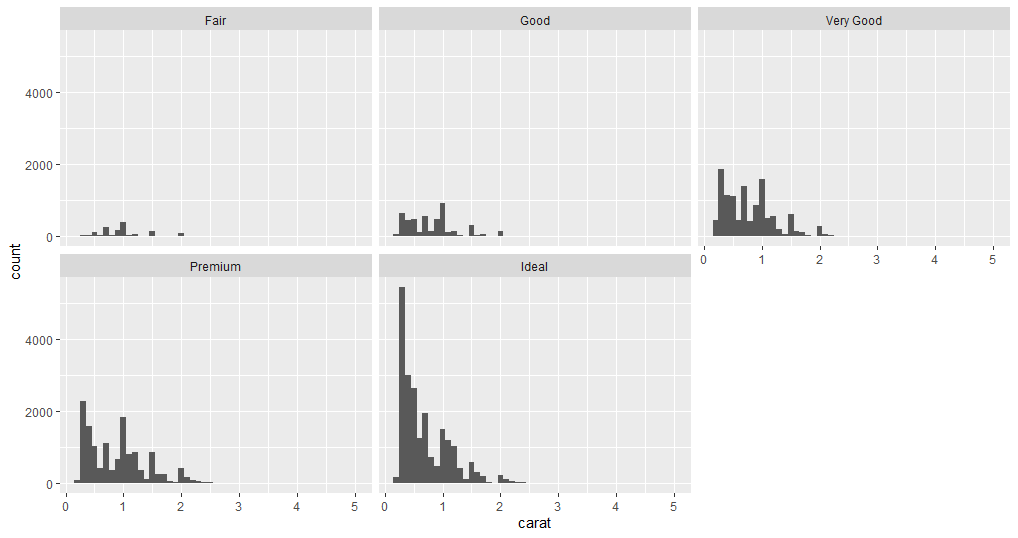
# Creating frequency polygon
ggplot(data = diamonds, mapping = aes(x = carat, colour = cut)) +
geom_freqpoly(binwidth = 0.1)
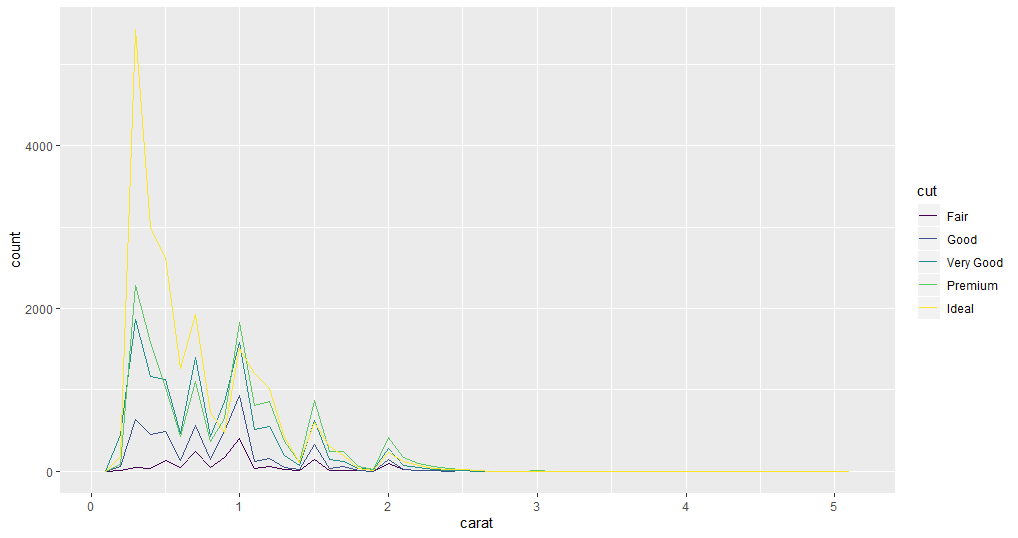
您可以决定哪种图更适合分析用例中的变量。
这些变化可能会引发一些问题,例如为什么某些变量会出现不寻常的值、分布中是否存在任何模式等。如何调查取决于您的数据和思维过程。
共变
共变是指两个或多个变量的值以相关方式变化。发现共变的最佳方法是将关系可视化。
此示例绘制了两个连续变量之间的关系:价格和克拉。
# plotting a scatter plot
ggplot(data = diamonds) +
geom_point(mapping = aes(x = carat, y = price))
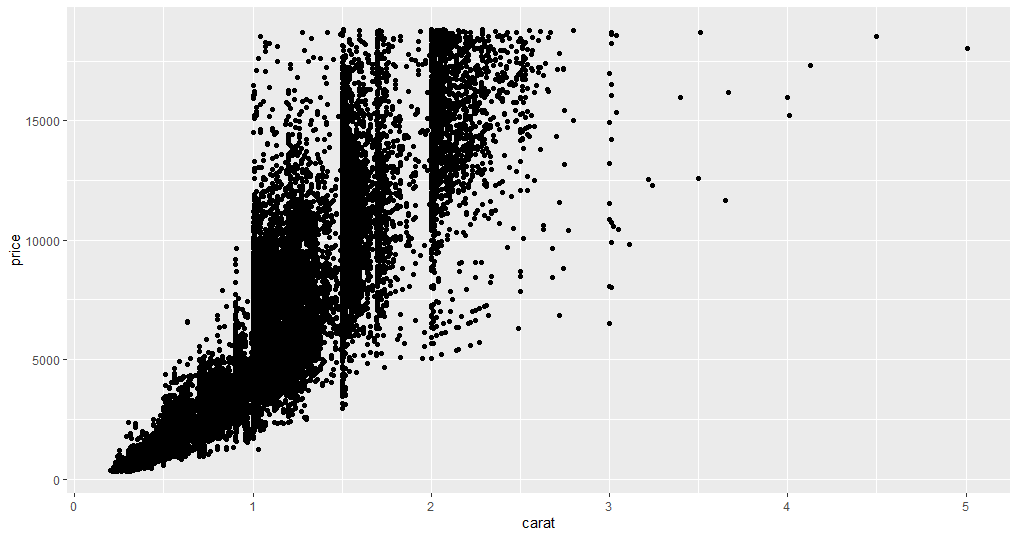
从图中可以看出,很明显,随着克拉数的增加,价格也会上涨,但由于数据点数量太多,因此产生了过度绘图的问题。过度绘图是指图中的数据点太多,很难从图中总结出结果。
相反,尝试使用箱线图将连续数据点划分为四分位数。在此示例中,您将以克拉作为分类变量并创建一个 0.1 的箱。
# creating boxplot
ggplot(data = diamonds, mapping = aes(x = carat, y = price)) +
geom_boxplot(mapping = aes(group = cut_width(carat, 0.1)))
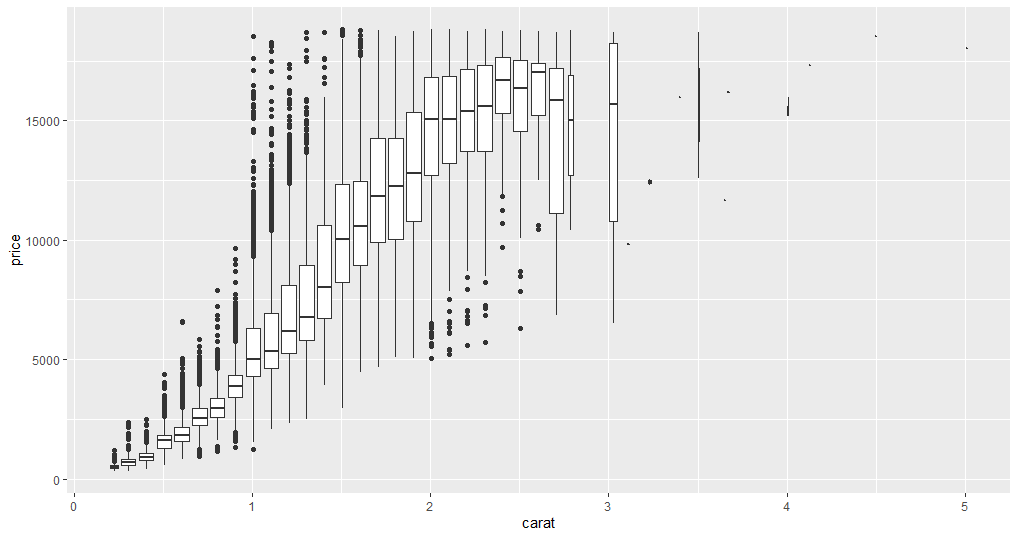
现在你可以看到一些不寻常的数据点。例如,一些一克拉钻石的价格异常高,而三克拉钻石的平均价格相对较低。三克拉以上的数据点可以忽略,因为它们对分析贡献不大。使用此图,你可以找到两个分类变量或一个分类变量和一个连续变量之间的关系。
相关图
查找数据集所有连续列之间的协变的另一种方法是创建相关图。此方法非常有效,并且可以筛选出需要进行更详细分析的列。
#install package
install.packages("corrplot")
# loading corrplot
library(corrplot)
# Creating correlation matrix for diamonds dataset
D <- cor(diamonds[,c(1, 5,6,7,8,9)])
coorplot(D, method = "circle")
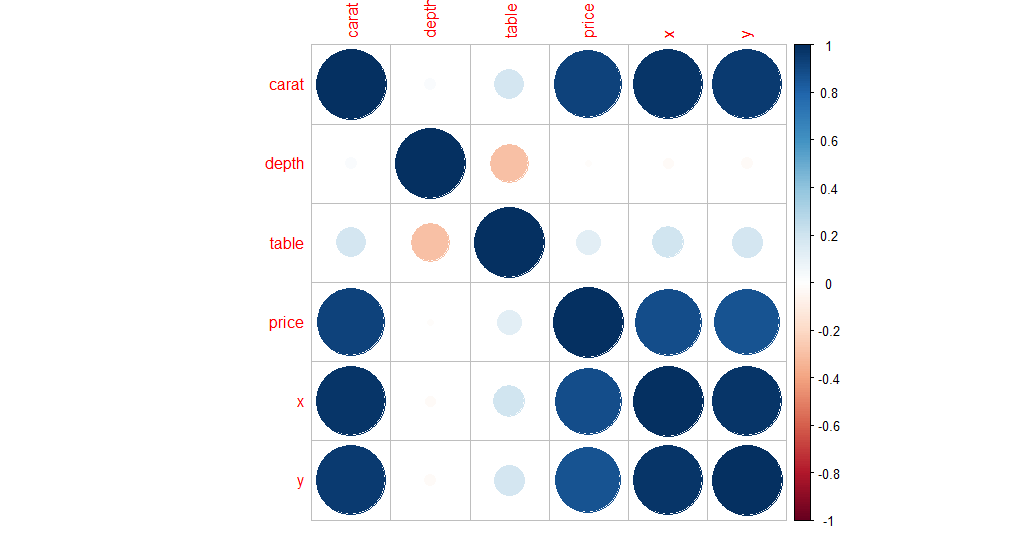
结论
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!




































请先 登录后发表评论 ~