
在 Azure 机器学习工作室中使用词云可视化文本数据
介绍
近年来,文本数据量呈指数级增长,因此对大量此类数据的分析需求也日益增加。词云是一种通过标签或单词形式的可视化来分析文本数据的绝佳选择,其中单词的重要性由其频率来解释。在本指南中,您将学习如何使用 Azure 机器学习工作室中的词云功能可视化文本数据。
数据
在本指南中,您将使用宝莱坞电影《仰光》的 Twitter 数据。这部电影于 2017 年 2 月 24 日上映,推文于 2 月 25 日提取。这些推文已存储在名为movietweets的文件中。数据包含行中的推文,您将考虑的列是包含推文的文本变量。首先将数据加载到工作区中。
加载数据
登录 Azure 机器学习工作室帐户后,单击左侧栏列出的“实验”选项,然后单击“新建”按钮。
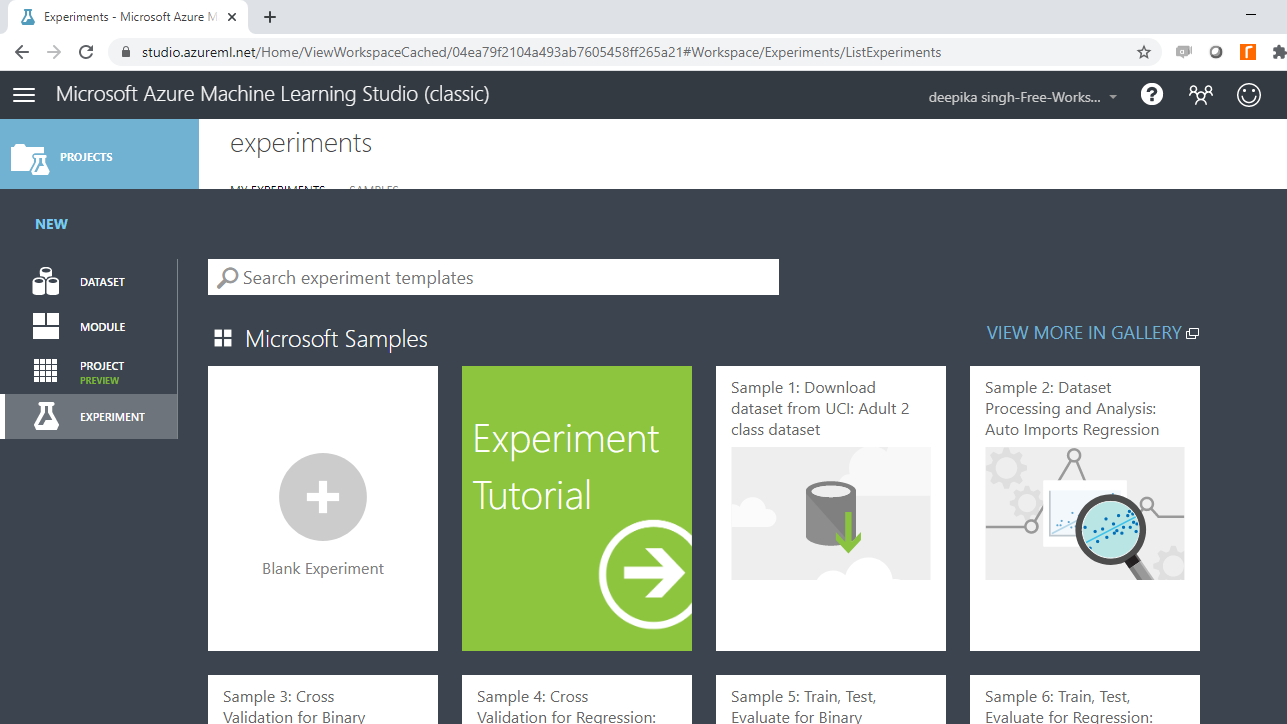
接下来,点击空白实验,将打开一个新的工作区。将工作区命名为WordCloud 。
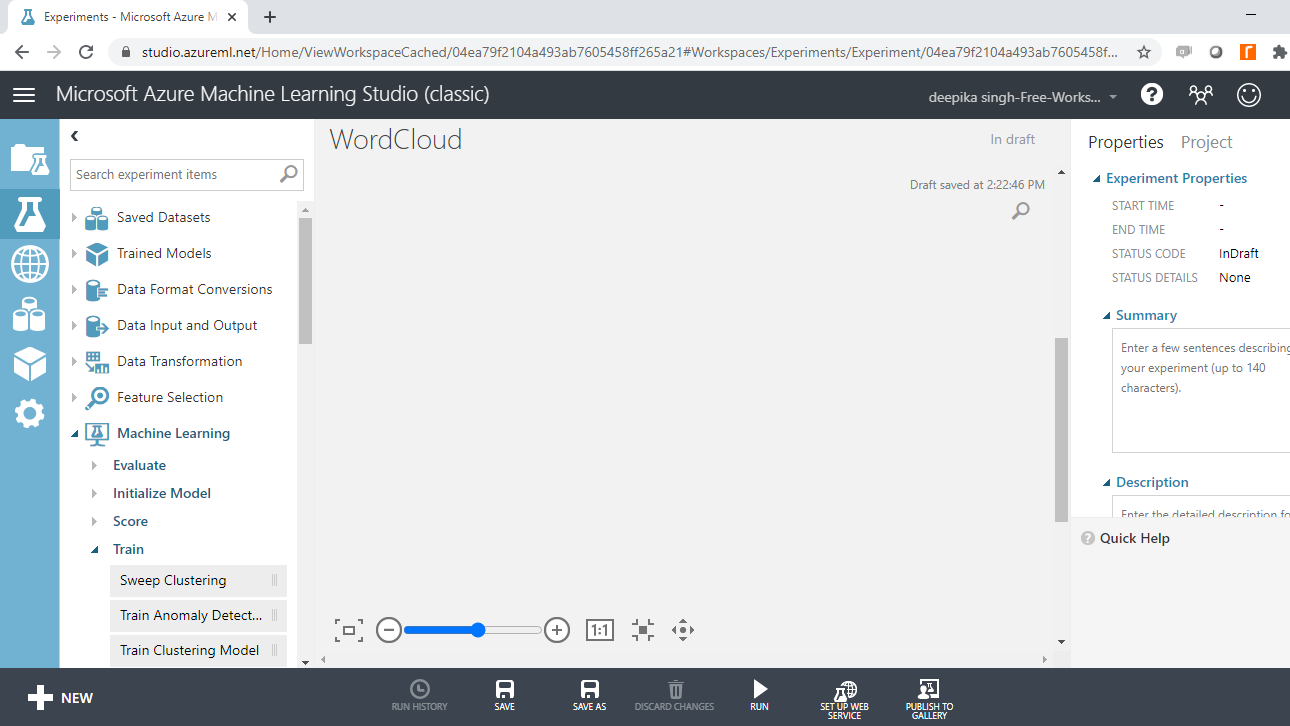
接下来,将数据加载到工作区中。单击NEW,然后选择如下所示的DATASET选项。
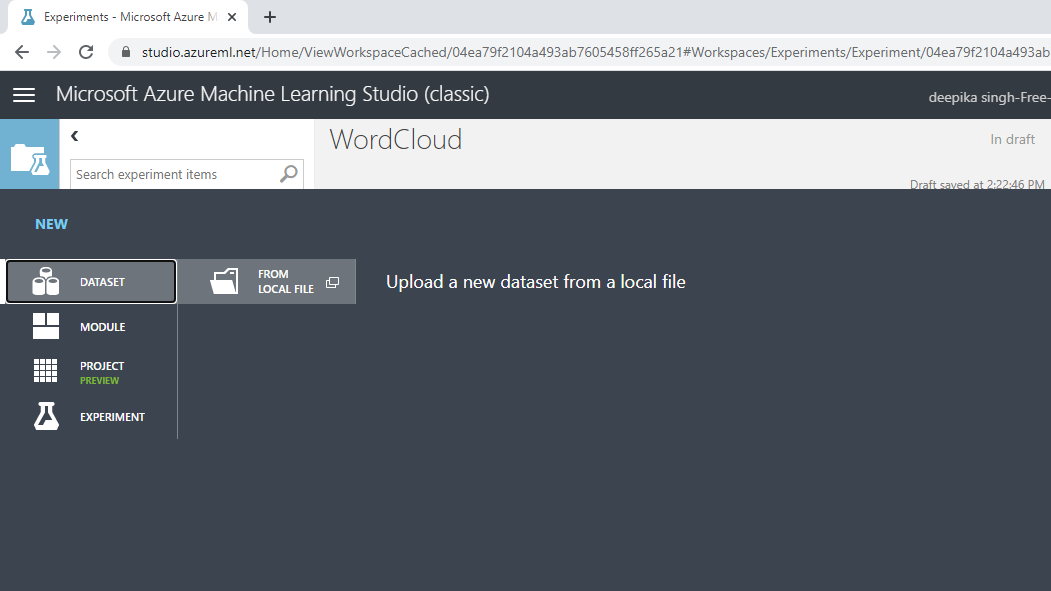
上面的选择将打开一个窗口,如下所示,可用于从本地系统上传数据集。
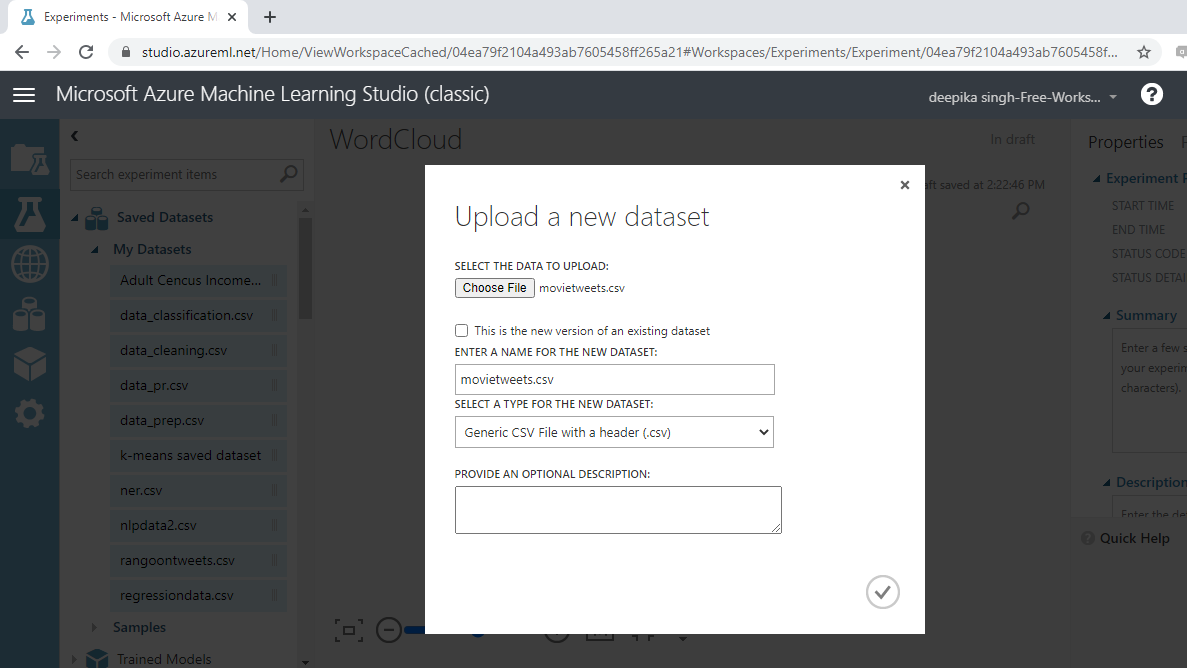
加载数据后,您可以在“已保存的数据集”选项中看到它。文件名为movietweets.csv。下一步是将其从“已保存的数据集”列表拖到工作区中。要浏览此数据,请右键单击并选择“可视化”选项,如下所示。
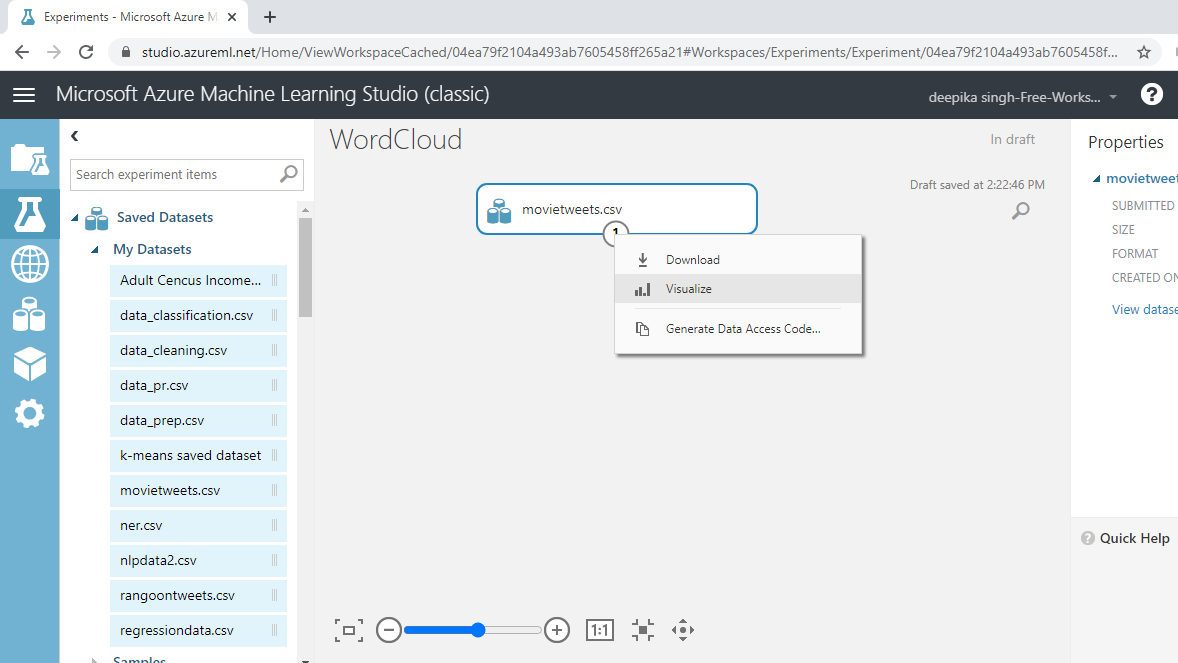
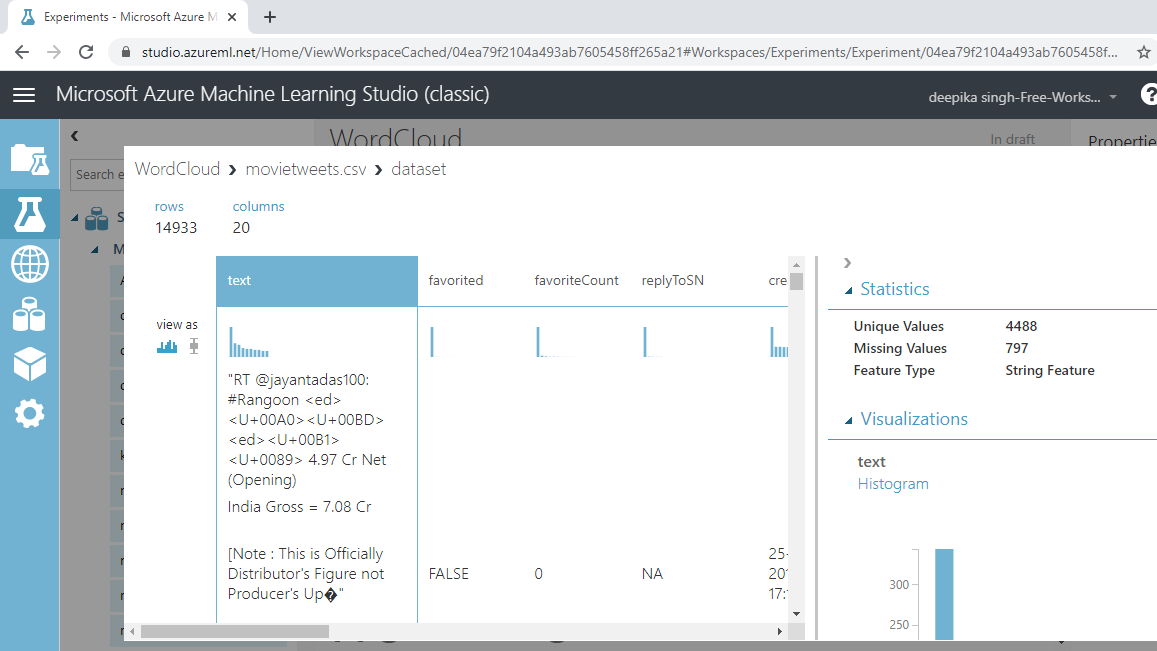
您可以看到有 14933 行和 20 列。
文本预处理
在使用词云可视化文本之前,对文本进行预处理非常重要。常见的预处理步骤包括:
删除标点符号:经验法则是删除所有不属于 x,y,z 形式的内容。
删除停用词:这些是无用的词,例如“the”、“is”或“at”。这些词没有帮助,因为此类停用词在语料库中出现的频率很高,但它们无助于区分目标类别。删除停用词也会减少数据量。
转换为小写:像“Clinical”和“clinical”这样的词需要被视为一个词。因此,这些词被转换为小写。
词干提取:词干提取的目的是减少文本中出现的单词的屈折形式数量。这使得诸如“argue”、“argued”、“arguing”和“argues”等单词被简化为它们的共同词干“argu”。这有助于减少词汇空间的大小。
预处理文本模块用于执行这些和其他文本清理步骤。搜索并将模块拖到工作区中。将其连接到数据,如下所示。
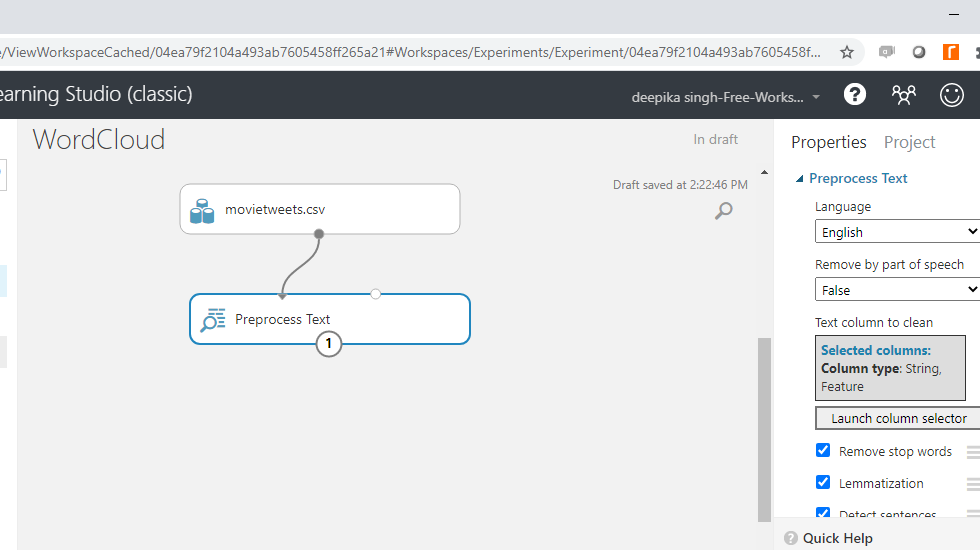
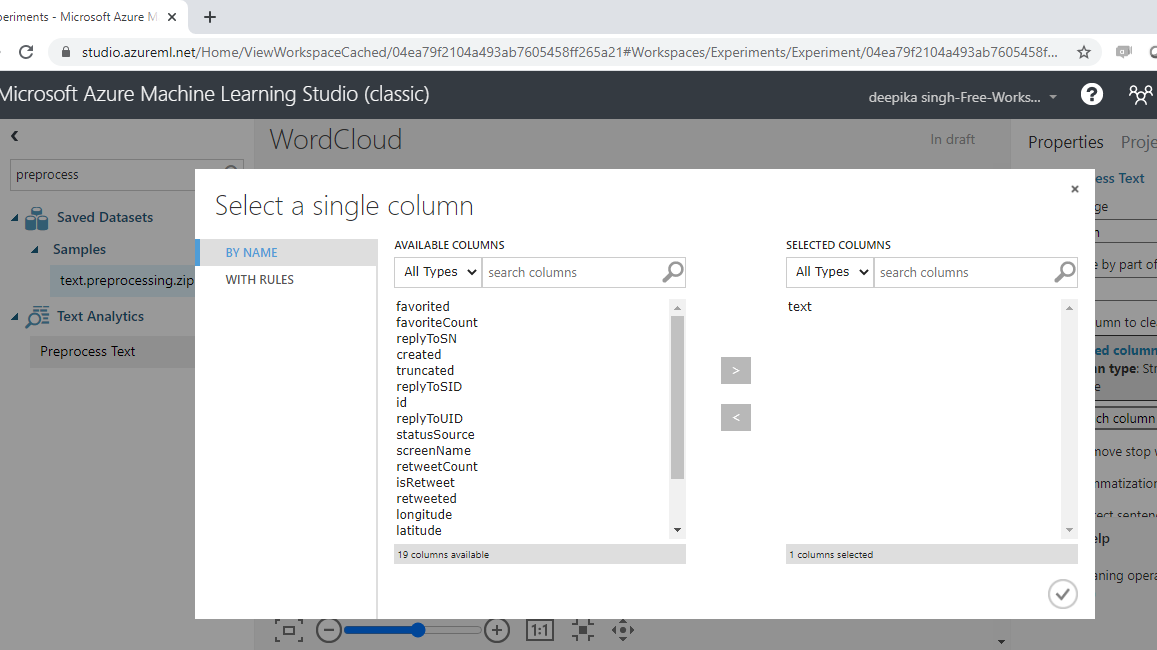
您必须指定要预处理的文本变量。单击启动列选择器选项,然后选择文本变量。
运行实验并单击“可视化”查看结果。预处理文本变量包含已处理的文本。
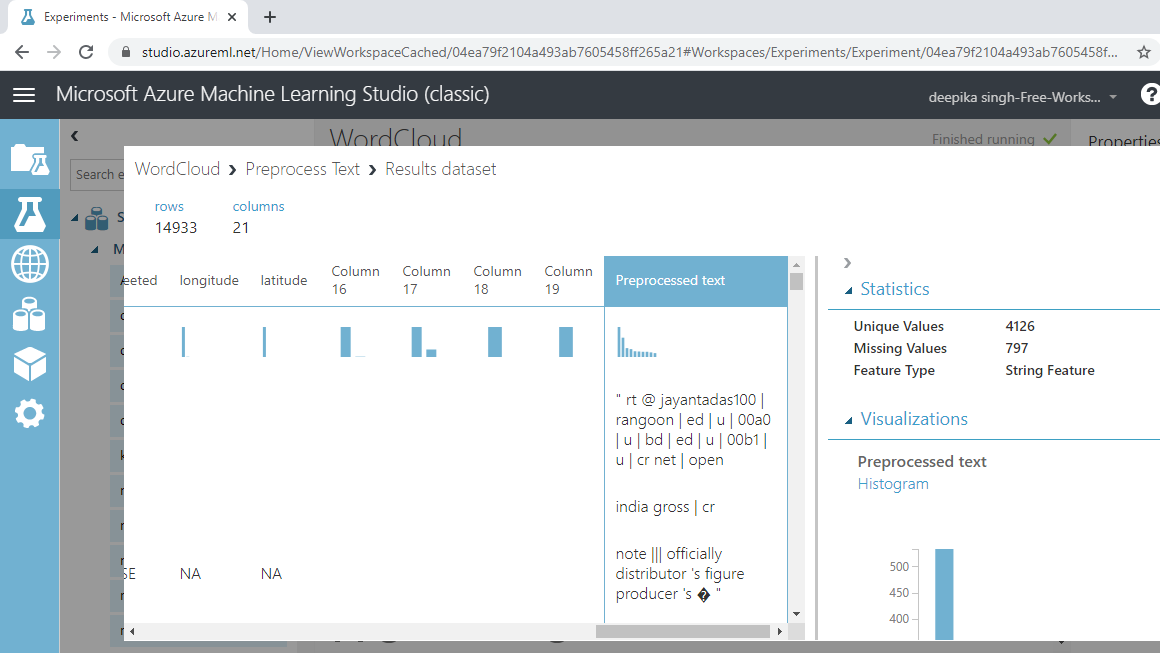
构建词云
您已完成预处理步骤,并且语料库已准备好用于构建词云。您将使用 R 编程语言生成词云。执行 R 脚本模块用于在机器学习实验中执行 R 代码。
首先,搜索并添加执行 R 脚本模块到实验中。接下来,将数据连接到模块的第一个输入端口(最左边)。
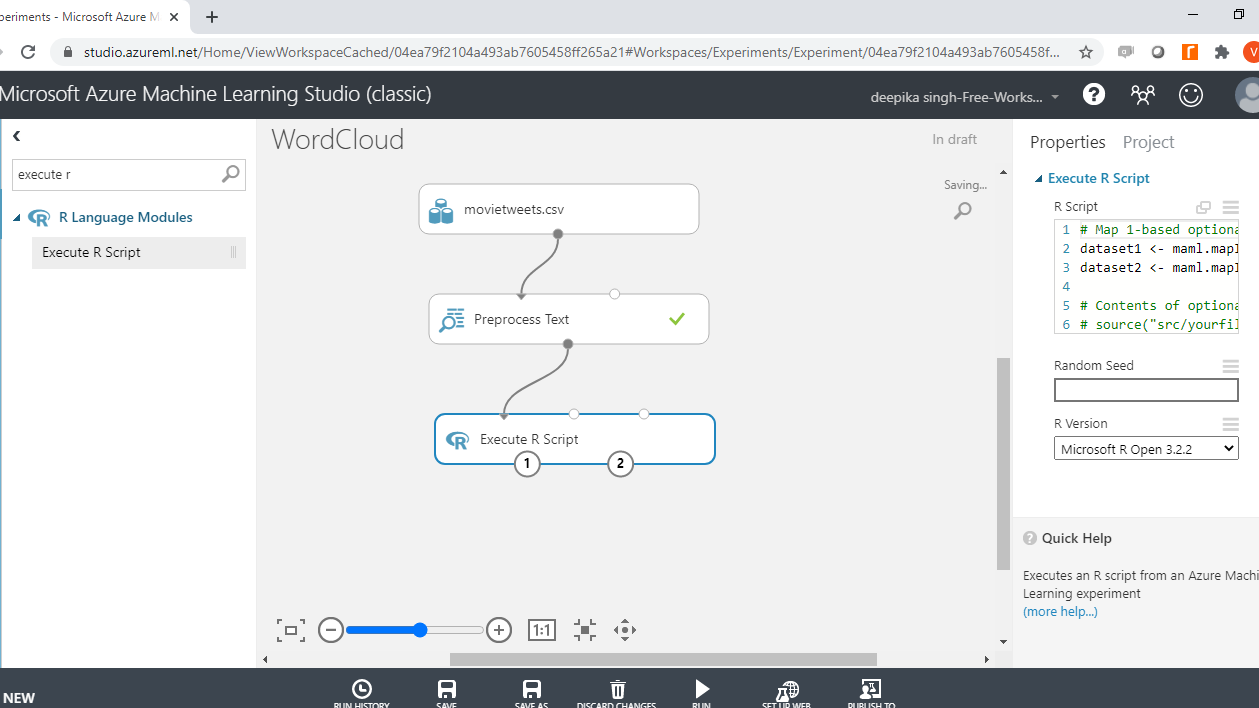
单击模块,然后在“属性”窗格下。您将看到编写 R 脚本的选项。输入如下所示的代码。
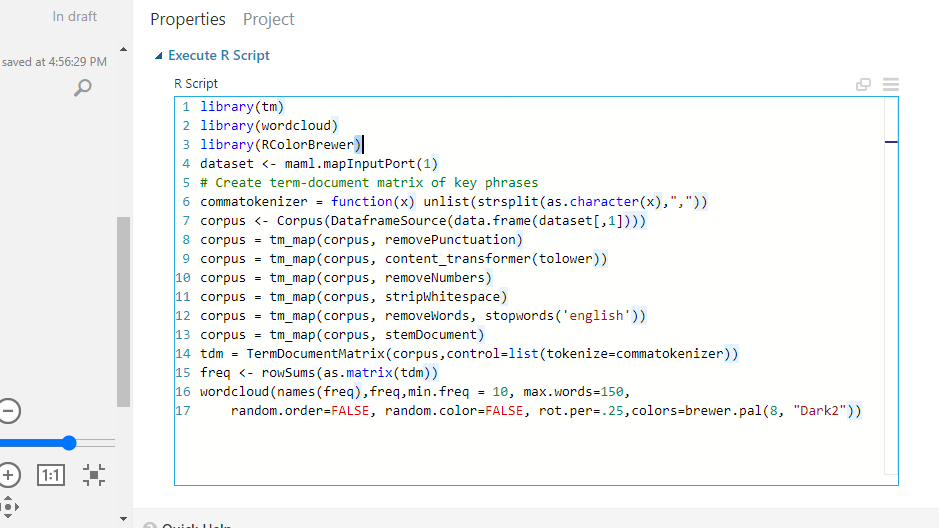
您也可以复制下面的代码。
#lines 1 to 4
library(tm)
library(wordcloud)
library(RColorBrewer)
dataset <- maml.mapInputPort(1)
# lines 5 to 12 – text preprocessing
commatokenizer = function(x) unlist(strsplit(as.character(x),","))
corpus <- Corpus(DataframeSource(data.frame(dataset[,1])))
corpus = tm_map(corpus, removePunctuation)
corpus = tm_map(corpus, content_transformer(tolower))
corpus = tm_map(corpus, removeNumbers)
corpus = tm_map(corpus, stripWhitespace)
corpus = tm_map(corpus, removeWords, stopwords('english'))
corpus = tm_map(corpus, stemDocument)
# lines 13 and 14 - Create term-document matrix, frequency
tdm = TermDocumentMatrix(corpus,control=list(tokenize=commatokenizer))
freq <- rowSums(as.matrix(tdm))
# line 15
wordcloud(names(freq),freq,min.freq = 10, max.words=150,
random.order=FALSE, random.color=FALSE, rot.per=.25,colors=brewer.pal(8, "Dark2"))
代码解释
在上面的代码中,前三行代码加载所需的库。第四行创建一个数据框dataset1,它使用函数mam1.mapInputPort()映射到第一个输入端口。
第五行到第十二行代码使用tm_map函数对先前预处理的文本数据进行进一步细化。接下来的两行创建文档术语矩阵并将单词的频率存储在freq对象中。最后,使用wordcloud()函数构建词云。此函数的主要参数如下。
min.freq:一个参数,确保频率低于min.freq的词不会绘制在词云中。
max.words:要绘制的最大单词数。
random.order:指定以随机顺序绘制单词的参数。如果为 false,则单词按频率递减的方式绘制。
rot.per:90度旋转(垂直文本)的单词比例。
colors:一个参数,指定单词的颜色,从出现频率最低到出现频率最高。
上述参数已在wordcloud()函数中提供。设置好实验后,下一步就是运行它。
成功完成后,您可以在模块中看到绿色勾号。
右键单击并选择“可视化”来查看输出。
输出结果如下。生成的词云显示单词按频率递减的顺序排列,这意味着最频繁的单词位于词云的中心,而频率较低的单词距离中心较远。
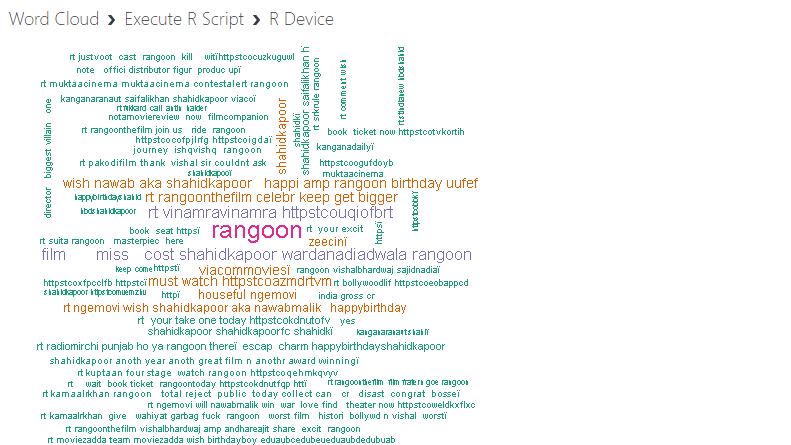
您可以看到单词“rangoon”位于词云的中心,这很有意义,因为它是电影的名称。另一个有趣的词是“miss”,因为电影中主角的名字是朱莉娅小姐。这样,您就可以使用词云分析文本语料库中的重要单词。
结论
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~