
从 Azure 机器学习工作室中的文本中提取关键短语
介绍
自然语言处理 (NLP) 的关键领域之一是从文本语料库中提取一个或多个有意义的短语。在多种情况下,主要在消费者领域,关键短语提取是必不可少的。在本指南中,您将了解如何使用 Azure 机器学习工作室中的模块从文本语料库中提取关键短语。
问题陈述和数据
在本指南中,您将承担医学领域自动化评审的任务。医学文献数量庞大且变化迅速,这增加了评审的需求。此类评审通常是手动完成的,既繁琐又耗时。您将尝试从输入变量abstract中提取关键短语。
您将使用的数据集来自PubMed搜索,包含 1,748 个观测值和 4 个变量,如下所述。
title:由检索到的论文标题组成的变量
abstract:包含检索到的论文摘要的变量
试验:变量表明该论文是否是测试癌症药物治疗的临床试验
class:目标变量,表明该论文是否为临床试验(是)或不是(否)
首先将数据加载到工作区。
加载数据
登录 Azure 机器学习工作室帐户后,单击左侧栏列出的“实验”选项,然后单击“新建”按钮。
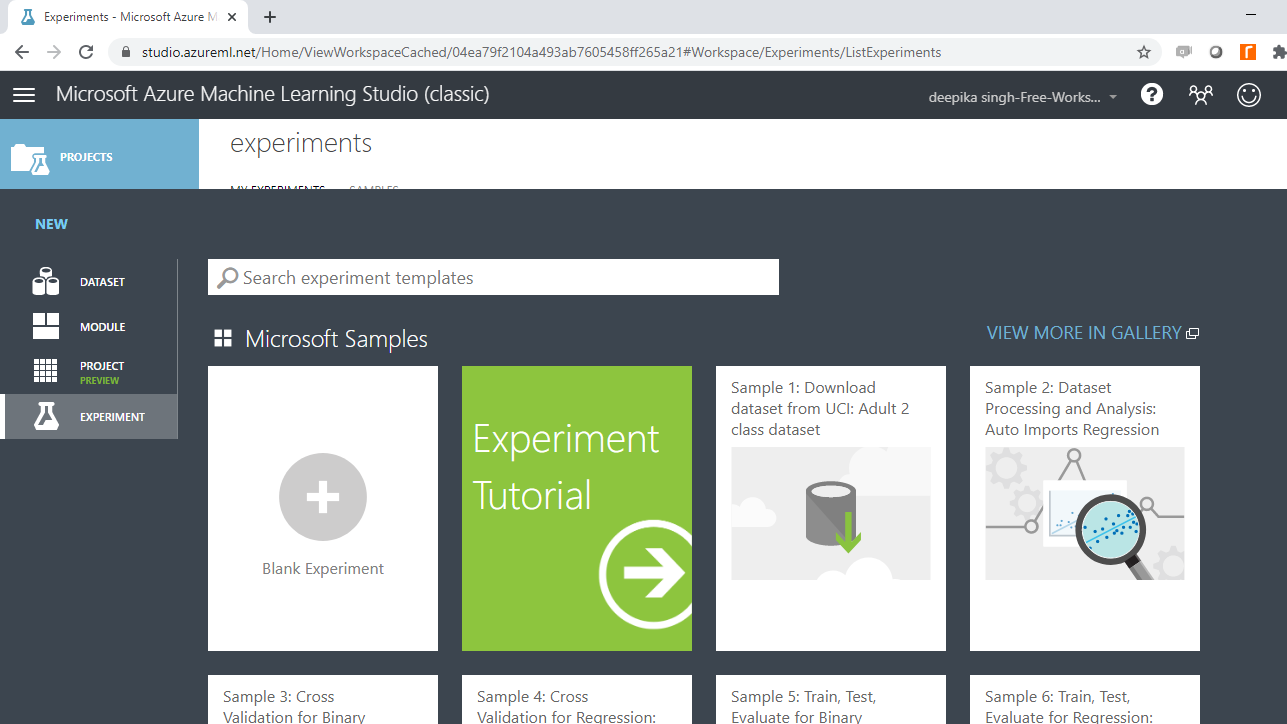
接下来,单击空白实验,将打开一个新的工作区。将工作区命名为Azure ML Experiment 。
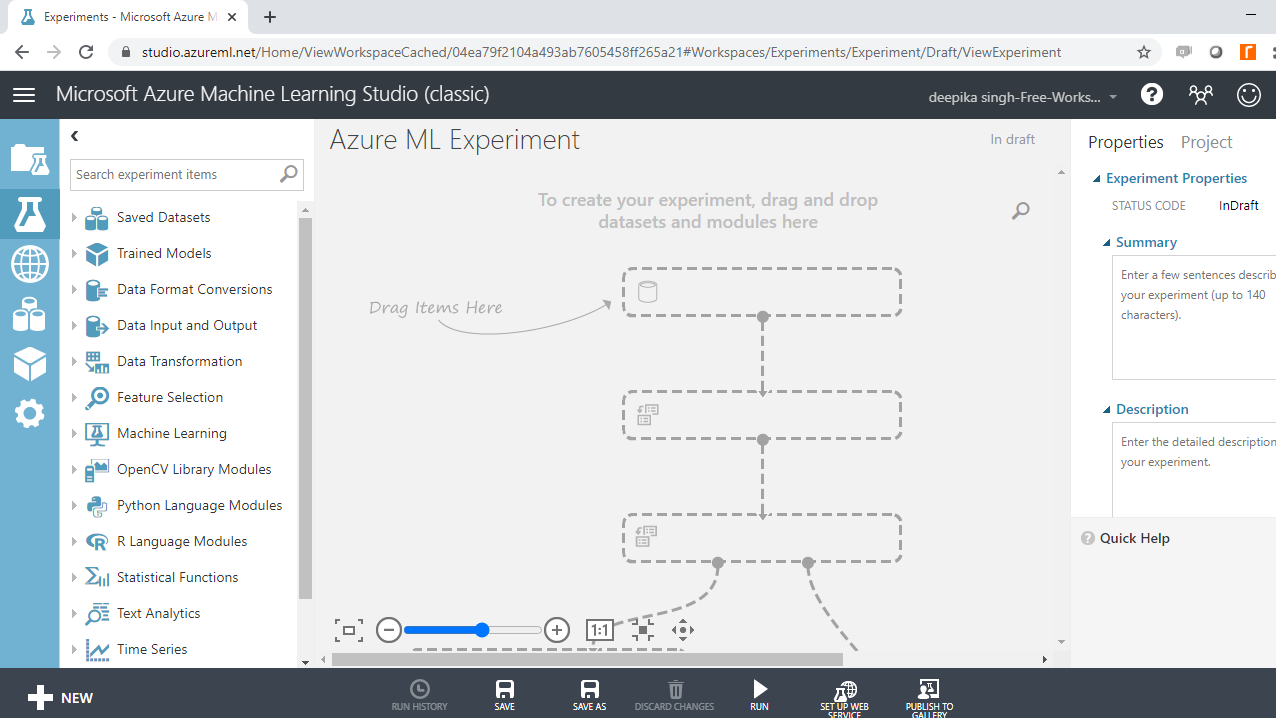
接下来,将数据加载到工作区中。单击NEW,然后选择如下所示的DATASET选项。
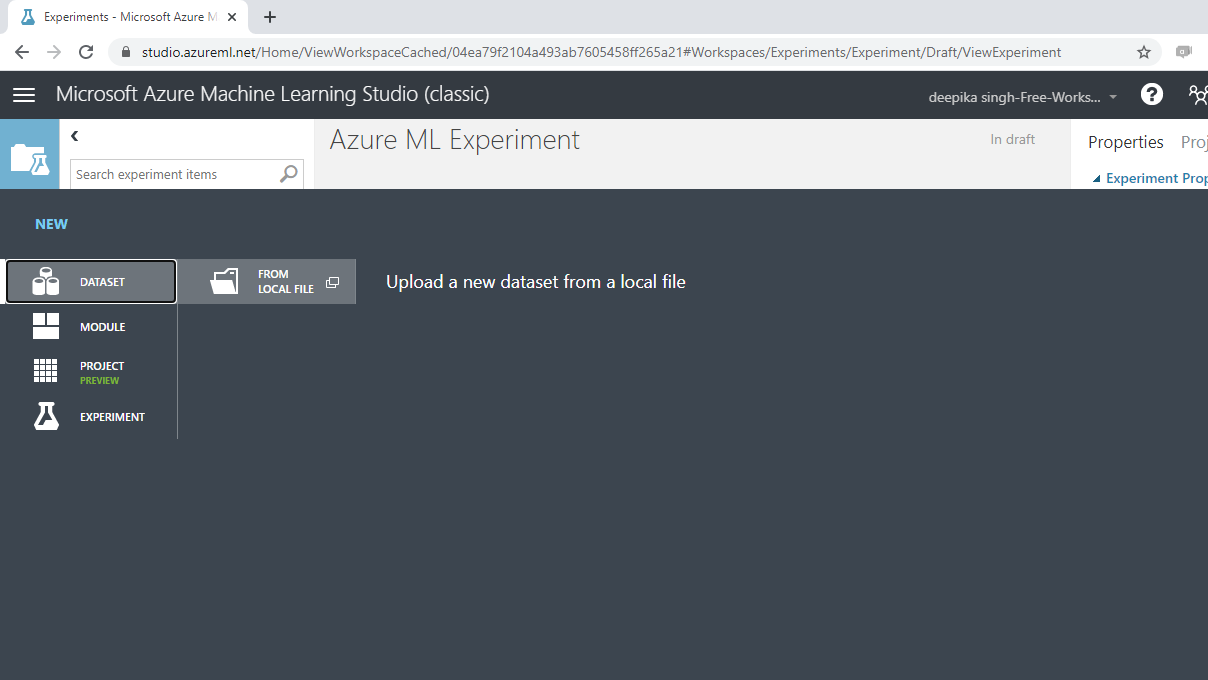
上面的选择将打开一个窗口,如下所示,可用于从本地系统上传数据集。
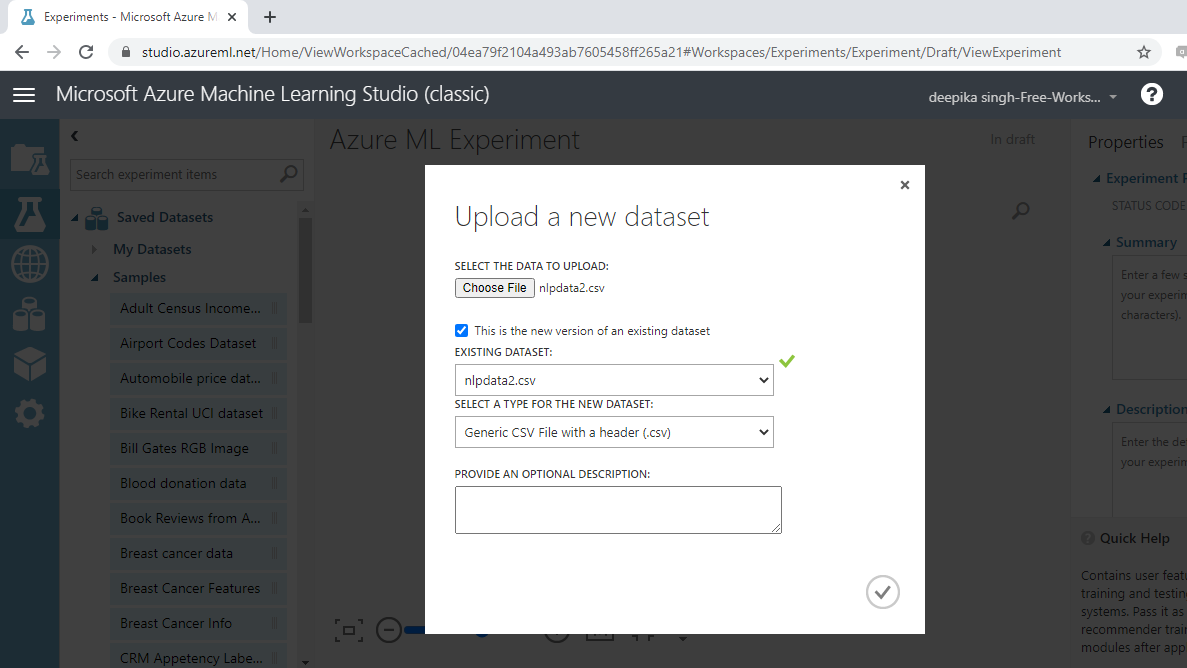
加载数据后,您可以在“已保存的数据集”选项中看到它。文件名为nlpdata2.csv。下一步是将其从“已保存的数据集”列表拖到工作区中。要浏览此数据,请右键单击并选择“可视化”选项,如下所示。
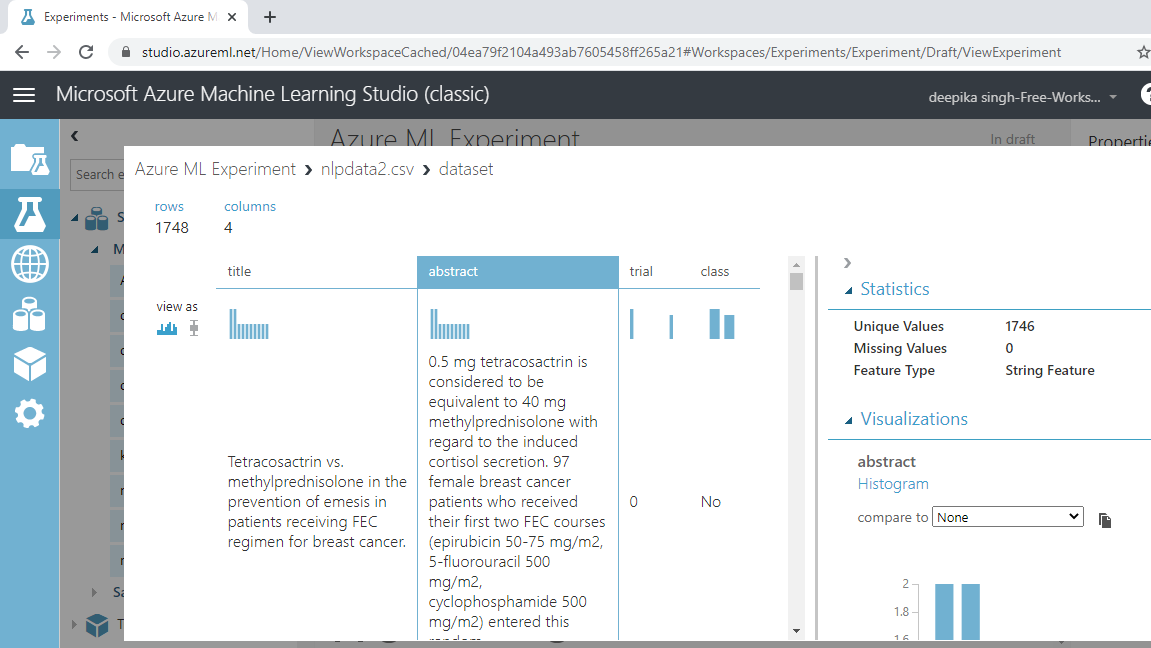
您可以看到有 1748 行和 4 列。
准备文本
在运行模块以从语料库中提取关键短语之前,对文本进行预处理非常重要。常见的预处理步骤包括:
删除标点符号:经验法则是删除所有不属于 x,y,z 形式的内容。
删除停用词:这些是无用的词,例如“the”、“is”或“at”。这些词没有用,因为此类停用词在语料库中出现的频率很高,但它们无助于区分目标类别。删除停用词也会减少数据量。
转换为小写:像“Clinical”和“clinical”这样的单词需要被视为一个单词。因此,大写字母的单词将转换为小写。
词干提取:词干提取的目的是减少文本中出现的单词的屈折形式数量。这使得诸如“argue”、“argued”、“arguing”和“argues”等单词被简化为它们的共同词干“argu”。这有助于减少词汇空间的大小。
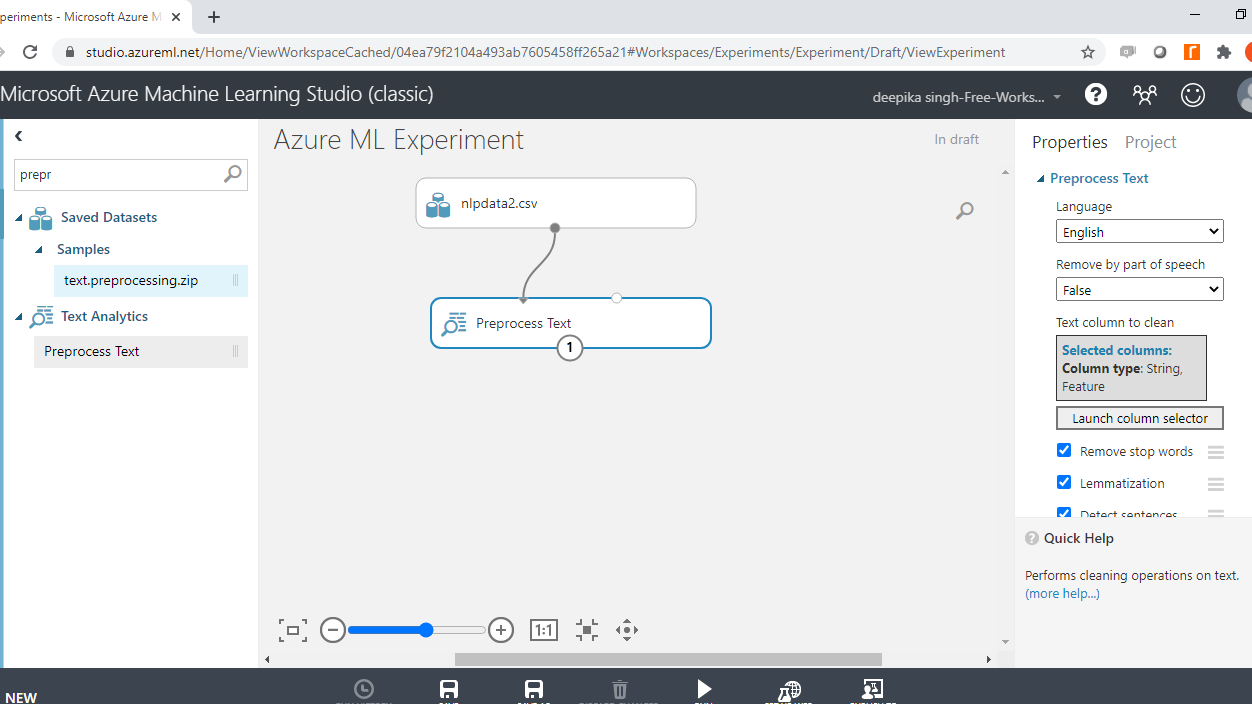
预处理文本模块用于执行这些步骤以及其他文本清理步骤。搜索并将模块拖到工作区中。将其连接到数据,如下所示。
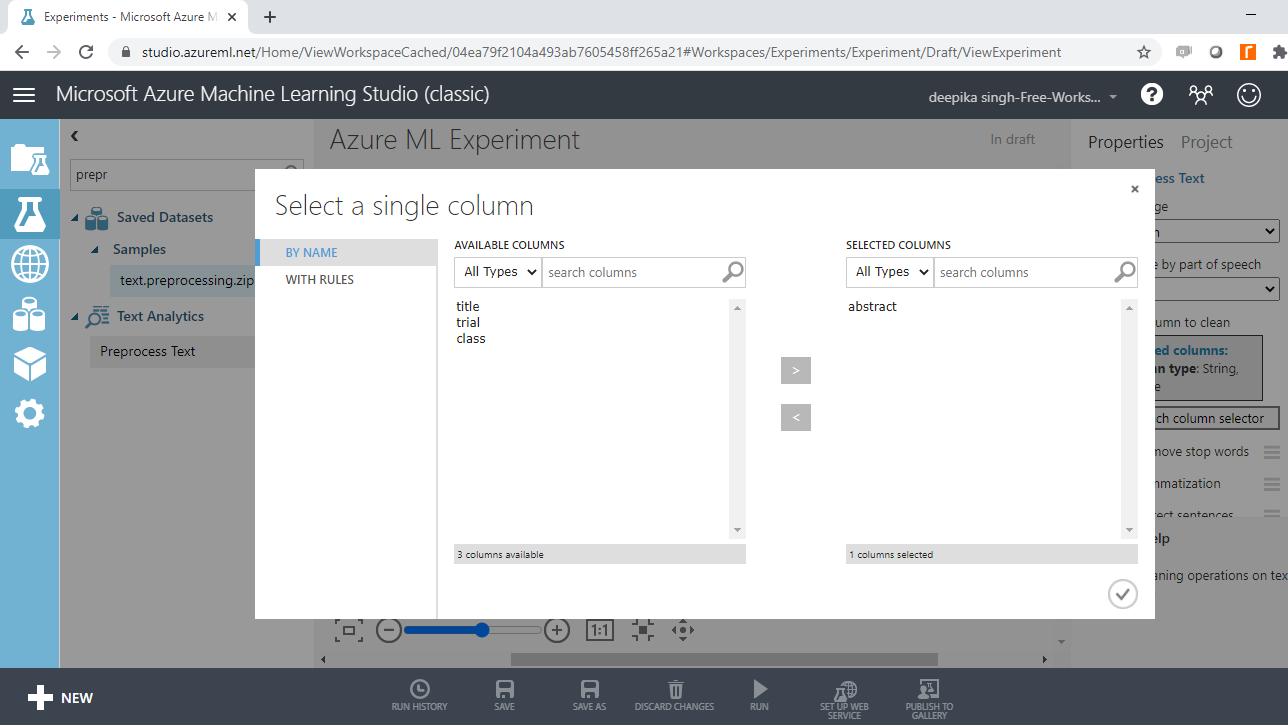
您必须指定要预处理的文本变量。为此,请单击启动列选择器选项,然后选择抽象变量。
运行实验并单击“可视化”查看结果。
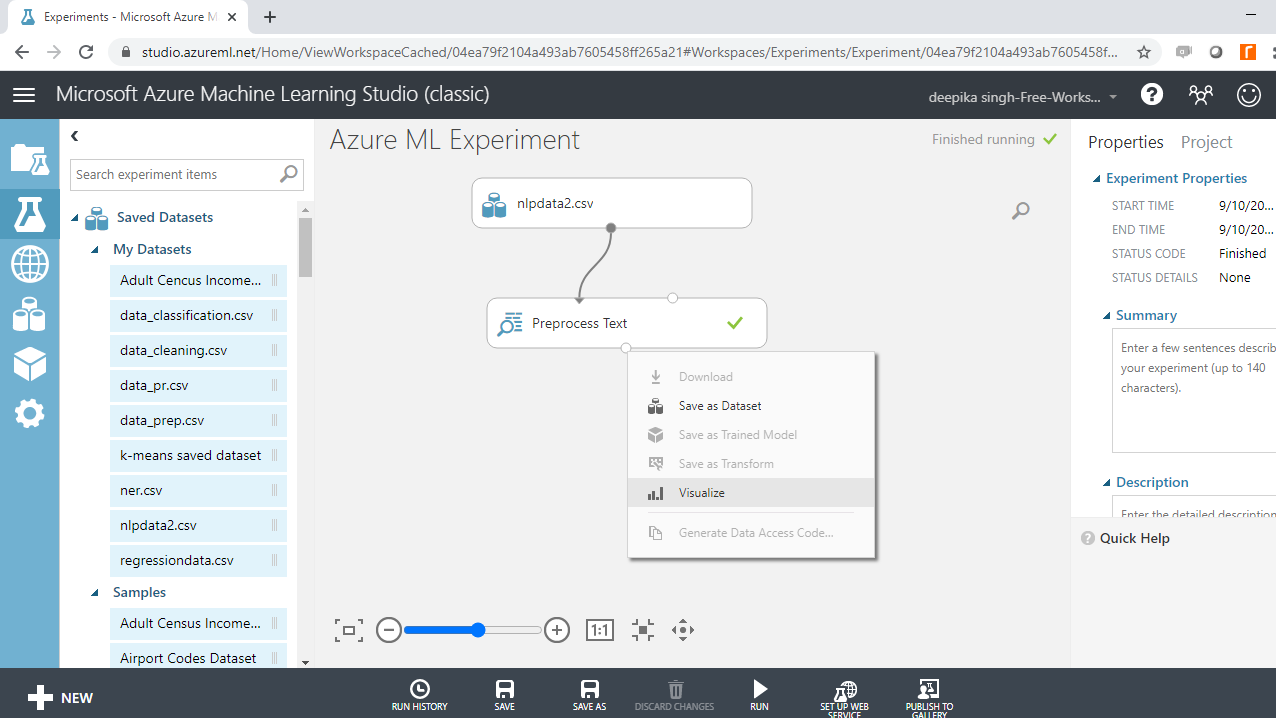
您可以在下面查看结果。Preprocessed抽象变量包含已处理的文本。如果将其与抽象变量进行比较,您可以看到文本预处理前后之间的差异。
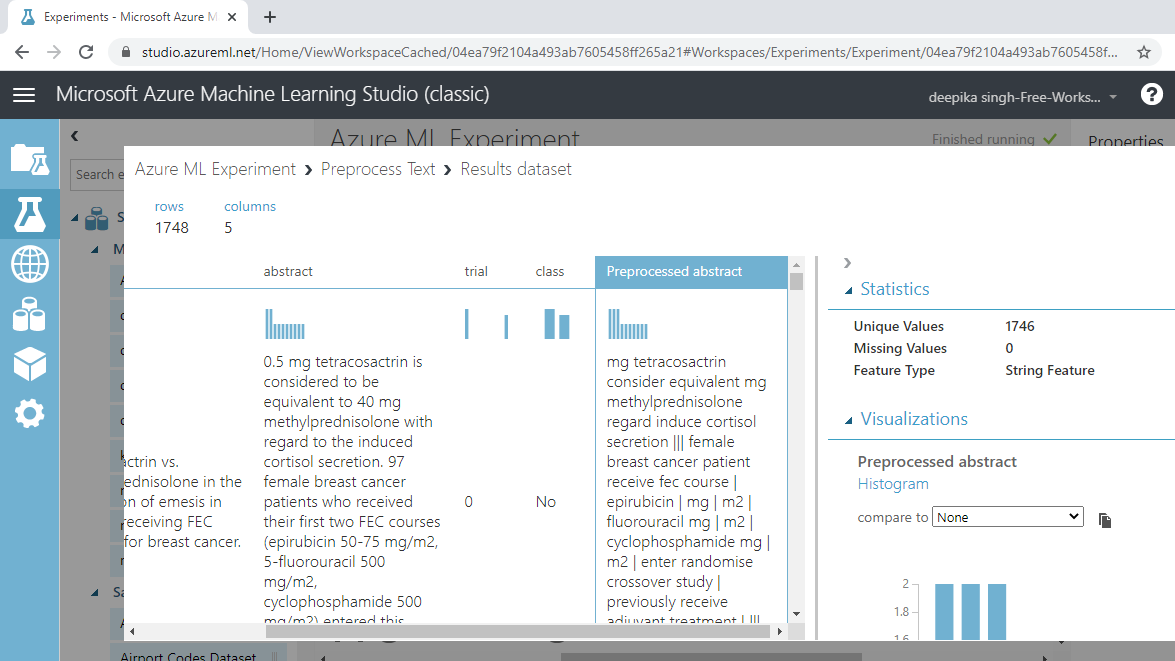
提取关键短语
您已执行预处理步骤,并且语料库已准备好提取关键短语。在 Azure 机器学习工作室中,从文本中提取关键短语模块执行此任务。搜索并将模块拖到工作区中。
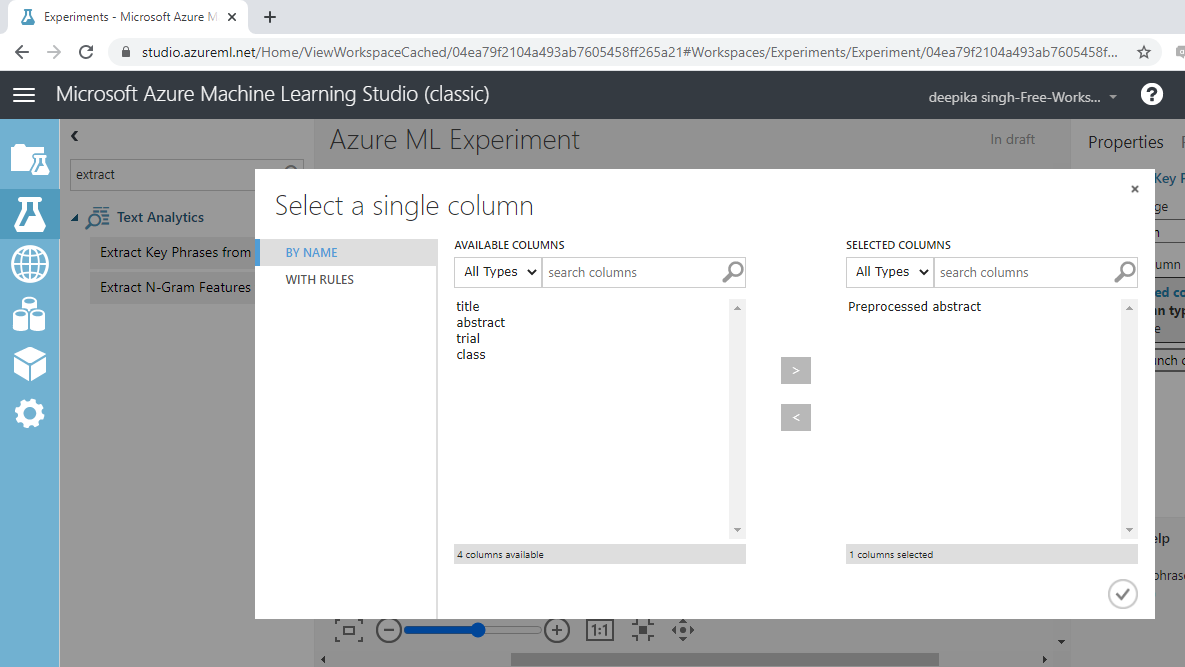
此模块基于用于关键短语提取的自然语言处理 API。该模块以短语的形式捕获句子的上下文。要指定文本变量,请单击模块。接下来,单击启动列选择器选项,然后选择预处理摘要变量。
运行模块,运行完成后,右键单击并选择可视化选项。
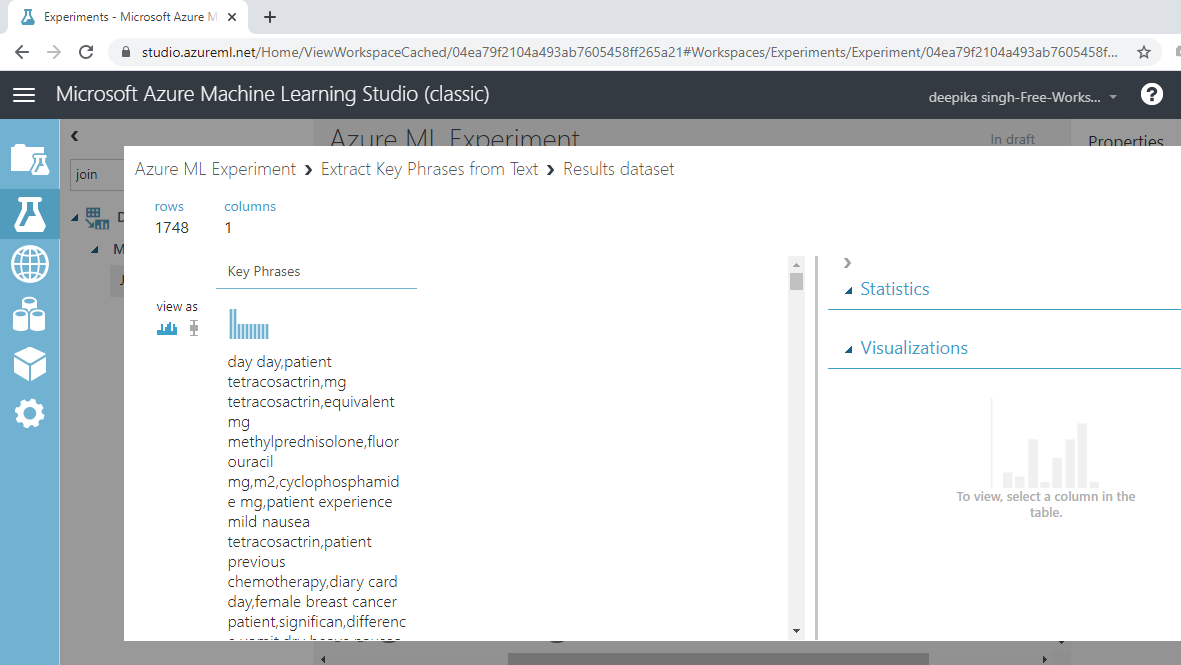
上述命令将产生以下输出。您可以看到长文本语料库如何转换为更有意义的关键短语或单词。第一条记录中的关键短语是day day、patient tetracosactrin和mg tetracosactrin等等。
结论
在本指南中,您学习了如何使用 Azure 机器学习工作室执行关键短语提取。它有多个应用领域,例如监控社交媒体和品牌情感分析。一些媒体公司使用关键字提取来了解热门话题,并将其用于内容制作。研究公司使用关键字提取来识别调查回复中最具代表性的单词。另一个突出的应用是搜索引擎优化 (SEO),其主要目标是提取有针对性的营销战略关键字。您可以在此处了解有关此概念的更多信息。
要了解有关使用 Azure 机器学习工作室进行数据科学和机器学习的更多信息,请参阅以下指南:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~