
使用 Hadoop Streaming 编写 MapReduce 应用程序
介绍
Hadoop Common(最初称为 Hadoop Core)是任何 Hadoop 生态系统的核心组件的集合。这些通用库和服务支持 Hadoop 生态系统的其他成员。有两个组件构成了 Hadoop 的基本功能:分布式存储(称为 HDFS)和分布式计算(称为 MapReduce)。
本指南将向您展示如何使用 Hadoop 流式传输工具来利用 Hadoop 的核心 MapReduce 功能。这样您就可以使用任何编程语言编写 MapReduce 应用程序,只要它具有映射器和缩减器功能即可。
MapReduce 回顾
MapReduce框架是当今大多数数据密集型框架的基础。下图说明了基本的 MapReduce 字数统计流程。
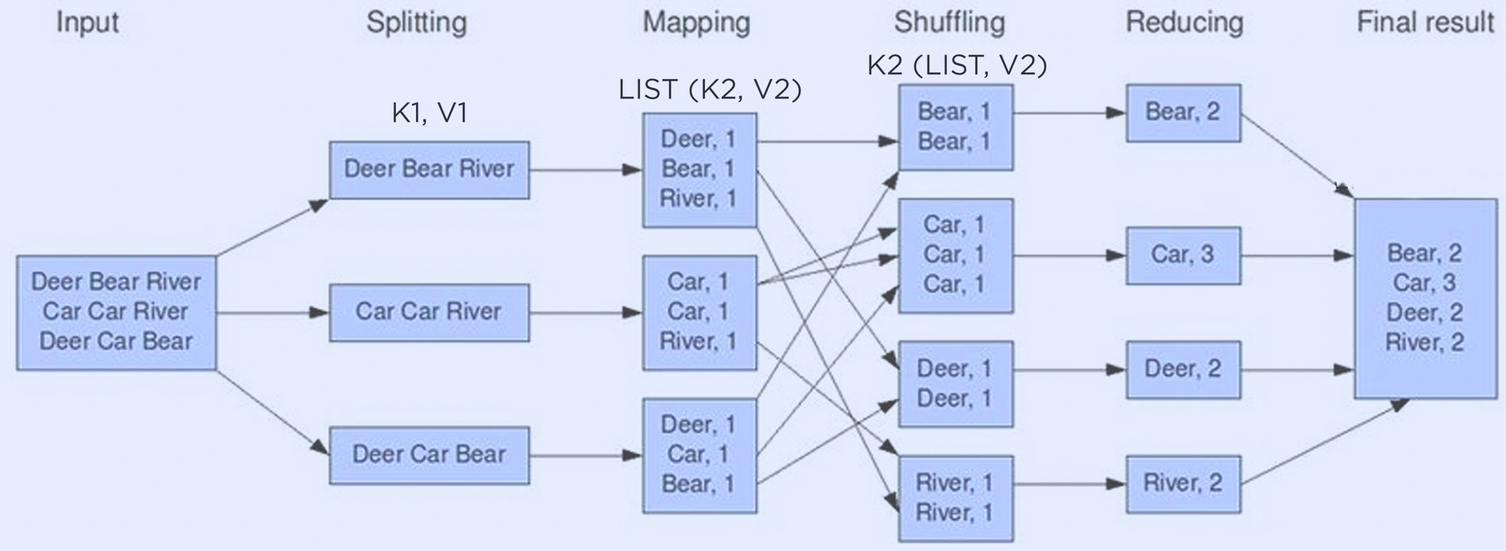
首先将文本语料库分成初始<key,value>对。以文本作为输入,初始<key,value>对是行和行的内容。之后,映射器函数将这些初始<key,value>对分成中间键值对。在这种情况下,单词的每个实例都映射到值 1。然后,shuffle 阶段按键对每个<key,value>对进行排序,以便Reducer可以负责聚合这些对以获得最终结果。
MapReduce 代码
Hadoop Streaming实用程序允许您以任何语言提交可执行文件,只要它遵循 MapReduce 标准即可。这将允许您编写原始 MapReduce 代码而无需抽象层。
以下是名为wordSplitter.py的映射器函数示例,它将一行中的每个单词分成一个<key,value>对。代码循环遍历给定行中的每个单词,并返回一个以制表符分隔的单词和数字对。关键字LongValueSum向 Hadoop 的内置聚合缩减器发出信号,表示需要对对中的值进行总计。
#!/usr/bin/python
import sys
import re
def main(argv):
pattern = re.compile("[a-zA-Z][a-zA-Z0-9]*")
for line in sys.stdin:
for word in pattern.findall(line):
print("LongValueSum:" + word.lower() + "\t" + "1" )
if __name__ == "__main__":
main(sys.argv)
下面是一个Reducer.py函数的示例。此函数的作用是维护每个键的运行总数。由于所有数据都按键排序,因此一旦函数到达特定键的最后一个实例,聚合即视为完成。到达最后一个键后,Hadoop Streaming 便可以对下一个键调用 Reducer 函数,依此类推。
#!/usr/bin/env python
import sys
last_key = None
running_total = 0
for input_line in sys.stdin:
input_line = input_line.strip()
this_key, value = input_line.split("\t", 1)
value = int(value)
if last_key == this_key:
running_total += value
else:
if last_key:
print( "%s\t%d" % (last_key, running_total) )
running_total = value
last_key = this_key
if last_key == this_key:
print( "%s\t%d" % (last_key, running_total) )
但是,对于简单的聚合(如字数统计)或简单的总计值,Hadoop 有一个名为aggregate的内置reducer 。以下是使用自定义映射器但内置聚合reducer运行Hadoop Streaming作业的脚本示例。
hadoop-streaming -mapper wordSplitter.py \
-reducer aggregate \
-input <input location> \
-output <output location> \
-file myPythonScript.py # Location of the script in HDFS, S3, or other storage
wordSplitter.py文件应存储在分布式存储中,通常是 HDFS 或 Amazon S3。然后应将文件的位置作为参数传递给hadoop-streamin 。如果您使用自定义 Reducer ,则还需要传入自定义 Reducer 脚本。
结论
Hadoop Streaming 是 Hadoop 开发人员最先学习的内容之一。它提供了一个简单的接口来编写 MapReduce 代码,但它通过强制开发人员编写原始 MapReduce 代码来消除 Hive 或 Pig 的抽象层。它是 Hadoop 的核心组件之一,应该存在于所有 Hadoop 部署和发行版中。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~