
文本预处理的重要性
介绍
如果正如人们所说“顾客就是上帝”,那么顾客反馈对任何组织,甚至对任何国家的政府都至关重要。反馈可以成就或毁灭一个政府或组织。通过公众评论分析获得的见解可以影响策略,从而提高绩效。
从客户反馈中获得的数据通常是非结构化的。它包含需要清理的异常文本和符号,以便机器学习模型能够掌握它。数据清理和预处理与构建任何复杂的机器学习模型一样重要。模型的可靠性在很大程度上取决于数据的质量。
入门
预处理步骤取决于给定的任务和数据量。本指南将介绍主要的预处理技术,如学习、规范化、标记化和注释。
在进一步了解这些技术之前,请导入重要的库。
import numpy as np
import pandas as pd
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.porter import *
from nltk.stem.wordnet import WordNetLemmatizer
清洁和消除噪音
通过将所有字符转换为小写、删除标点符号以及删除停用词和拼写错误,它有助于摆脱数据中无用的部分或噪音。
当您想对评论或推文等数据进行文本分析时,去除噪音非常有用。以下部分中的代码将有助于去除干扰文本分析的文本。
此示例使用简单文本,便于您轻松演练。您也可以添加带有段落的.txt文件,或直接粘贴/编写它们。请参阅下面的替代代码。
小写
您可能会想,“当大写字母位于句子开头或专有名词中时,我应该怎么做?” 为了简单起见,有一种常见的方法是将所有内容都小写。 它有助于在 NLP 任务和文本挖掘期间保持一致性。 lower ()函数使整个过程变得非常简单。
def lowercase(intext):
return intext.lower()
#Alternatively:
#orig =data.raw(r'file.text') # read raw text form orignal file
#sent = data.sents(r'file.txt') #brake parah into sentance
#bwords = data.words(r'file.text')#break parah into words
intext = input('Your-Text:')
clean_text = lowercase(intext)
print('\nlowercased:',lowercase(clean_text))

句子中的标点符号会增加噪音,从而给模型训练带来歧义。
标点符号
让我们检查一下string.punctuation()函数过滤掉的标点符号类型。为了实现标点符号删除,使用了maketrans() 。它可以替换特定字符的标点符号,在本例中是替换为其他字符。代码用空格 ( '' )替换标点符号。translate ()是一个用于进行这些替换的函数。
output= string.punctuation
print('list of punctuations:', output)
def punctuation_cleaning(intext):
return text.translate(str.maketrans('', '', output))
print('\nNo-punctuation:',punctuation_cleaning(clean_text))

HTML 代码和 URL 链接
下面的代码使用了正则表达式 ( re)。要使用正则表达式进行匹配,请使用re.complie将其转换为对象,这样搜索模式就变得更容易,并且可以执行字符串替换。为此使用了.sub()函数。
def url_remove(text):
url_pattern = re.compile(r'https?://\S+|www\.\S+')
return url_pattern.sub(r'', text)
def html_remove(text):
html_pattern = re.compile('<.*?>')
return html_pattern.sub(r'', text)
text1 = input('Your-Text:')
print('\nNo-url-links:', url_remove(text1))
text2 = input('Your Text:')
print('\nNo-html-codes:', html_remove(text2))

拼写检查
本指南使用pyspellchecker包进行拼写纠正。
from spellchecker import SpellChecker
spelling = SpellChecker()
def spelling_checks(text):
correct_result = []
typo_words = spelling.unknown(text.split())
for word in text.split():
if word in typo_words:
correct_result.append(spelling.correction(word))
else:
correct_result.append(word)
return " ".join(correct_result)
text = input('Your-Text: ')
print('Error free text:',spelling_checks(text))

请参阅此代码来了解如何从文本中删除表情符号。
神经科学知识库
标记化
标记化就像将整个句子拆分成单词。您可以考虑使用简单的分隔符来实现此目的。但是分隔符无法拆分用“。”分隔的缩写或特殊字符(例如 UART)。当包含更多语言时,挑战会增加。如何处理德语或法语等语言中的复合词?
大多数这些问题都可以通过使用nltk库来解决。word_tokenize模块将单词分解为标记,这些单词作为规范化和清理过程的输入。它还可以用于将字符串(文本)转换为数字数据,以便机器学习模型可以消化它。
删除停用词
英语是最常用的语言之一,尤其是在社交媒体世界中。例如,“a”、“our”、“for”、“in”等属于最常用的单词集。删除这些词有助于模型仅考虑关键特征。这些词也不包含太多信息。通过删除它们,数据科学家可以专注于重要的单词。
查看nltk提供的停用词列表。
stopwordslist = stopwords.words('english')
print(stopwordslist)
print('Total:',len(stopwordslist))

text = "A smart kid ran towards the police station when he saw the thieves approaching."
stop_words = set(stopwords.words('english'))
tokenwords = word_tokenize(text)
result = [w for w in tokenwords if not w in stop_words]
result = []
for w in tokenwords:
if w not in stop_words:
result.append(w)
print('Tokenized words: ',tokenwords)
print('No-Stopwords: ',result)

突出显示的单词已从序列中删除。添加一些虚拟文本并观察变化。
正常化
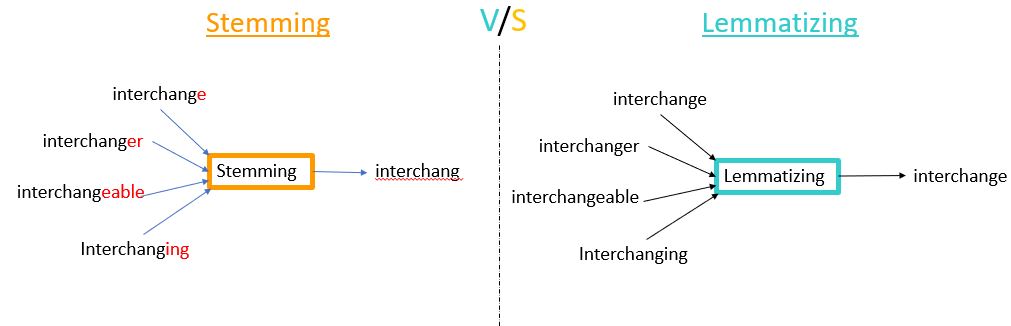
词干提取
单词的许多变体不会带来任何新信息,而且会产生冗余,最终在训练机器学习模型进行预测时带来歧义。以“他喜欢走路”和“他喜欢走路”为例。两者含义相同,因此词干提取函数将删除后缀并将“走路”转换为“走路”。本指南中的示例使用PorterStemmer模块进行该过程。您可以将snowball模块用于不同的语言。
ps = PorterStemmer()
stemwords = [ps.stem(w) for w in tokenwords]
print ('Stemming-Form:', stemwords)

在这个例子中,单词“polic”和“thiev”没有意义。由于词干提取的后缀剥离规则,它们的e和es被截断了。词形还原技术可以解决这个问题。
词形还原
与词干提取不同,词形还原使用词汇和词的形态分析来执行规范化。词形还原旨在仅删除词尾屈折并返回单词的基本形式或词典形式,这称为词根。词形还原使用词典,这使得它比词干提取慢,但是结果比词干提取的结果更有意义。词形还原建立在 WordNet 的内置形态函数之上,使其成为一种智能的文本分析操作。WordNet模块是一个大型的公共英语词汇数据库。其目的是维护单词之间的结构化关系。WordNetLemmitizer ()是最早和最广泛使用的函数。
lemmatizer = WordNetLemmatizer()
lemmawords = [lemmatizer.lemmatize(w) for w in tokenwords]
print ('Lemmtization-form',lemmawords)

用例
NLTK 语料库阅读器使用词汇数据库来查找单词的同义词、反义词、上义词等。在本用例中,您将使用synset()函数查找单词的同义词(具有相同含义的词)和上义词(具有更广泛含义的词)。
from nltk.corpus import wordnet as wn
for ssn in wn.synsets('aid'):
print('\nName:',ssn.name(),'\n-Abstract term: ',ssn.hypernyms(),'\n-Specific term:',ssn.hyponyms())#Try:ssn.root_hypernyms()
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~