
使用 Azure 机器学习工作室进行命名实体识别
介绍
命名实体识别 (NER) 是一种自然语言处理任务,用于识别文本中的重要命名实体,例如人物、地点、组织、日期或任何其他类别。它可以单独使用,也可以与主题识别一起使用,并为内容添加大量语义知识,使我们能够理解任何给定文本的主题。
命名实体识别是研究和文本挖掘中的一个重要领域。一些用例是识别推文中提到的地点或人物、从客户反馈中提取关键部分以及补充或协助情绪分析。在本指南中,您将了解如何在 Azure 机器学习工作室中执行命名实体识别。
数据
在本指南中,您将使用一个包含两组文本的列的数据集。第一组文本是关于电影《复仇者联盟》,第二组文本是关于 Pluralsight 的。
第一篇文字:《复仇者联盟:终局之战》是一部 2019 年美国超级英雄电影,改编自漫威漫画超级英雄团队复仇者联盟,由漫威影业制作,华特迪士尼影业发行。这部电影的演员阵容包括小罗伯特·唐尼、克里斯·埃文斯、马克鲁弗洛、克里斯·海姆斯沃斯等。(来源:维基百科)。
第二段文字:Pluralsight, Inc. 是一家美国上市在线教育公司,通过其网站为软件开发人员、IT 管理员和创意专业人士提供各种视频培训课程。该公司由 Aaron Skonnard、Keith Brown、Fritz Onion 和 Bill Williams 于 2004 年创立,总部位于犹他州法明顿。截至 2018 年 7 月,该公司聘请了 1,400 多名主题专家作为作者,并在其目录中提供 7,000 多门课程。自 2007 年首次将课程转移到网上以来,该公司不断扩展,开发了一个完整的企业平台,并增加了技能评估模块。(来源:维基百科)。
首先将数据加载到工作区。
加载数据
登录 Azure 机器学习工作室帐户后,单击左侧栏上列出的“实验”选项,然后单击“新建”按钮。

接下来,点击空白实验,将打开一个新的工作区。将工作区命名为命名实体识别。

接下来,您将数据加载到工作区中。单击NEW,然后选择下面显示的DATASET选项。

上面的选择将打开如下所示的窗口,可用于从本地系统上传数据集。

加载数据后,您可以在“已保存的数据集”选项中看到它。文件名为ner.csv。下一步是将其从“已保存的数据集”列表拖到工作区中。要浏览此数据,请右键单击并选择“可视化”选项,如下所示。

您可以看到有一列,其中的行包含上面突出显示的两段文本。
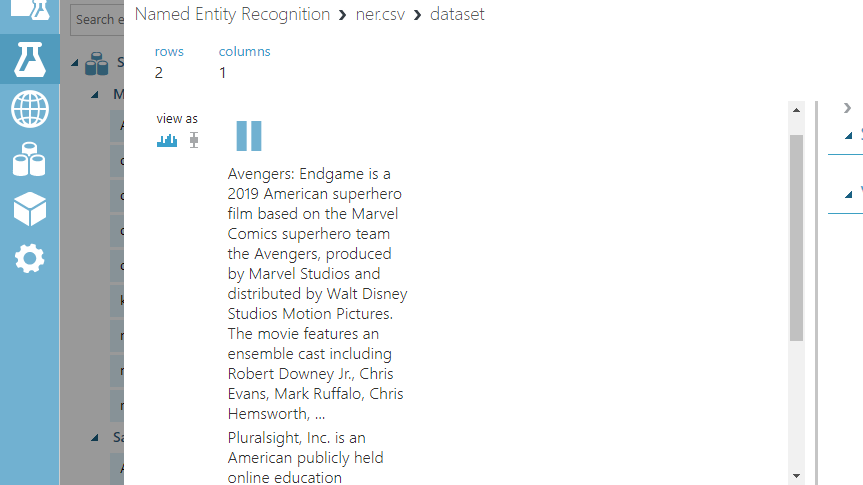
命名实体识别
命名实体识别模块用于识别名称、组织实体、地点等。首先在搜索栏中输入“命名实体”来找到该模块,然后将其拖到工作区中。

在上面的输出中,您可以看到Story端口。这是您需要连接文本数据并从中提取实体的端口。将数据连接到此端口,如下所示。运行实验。
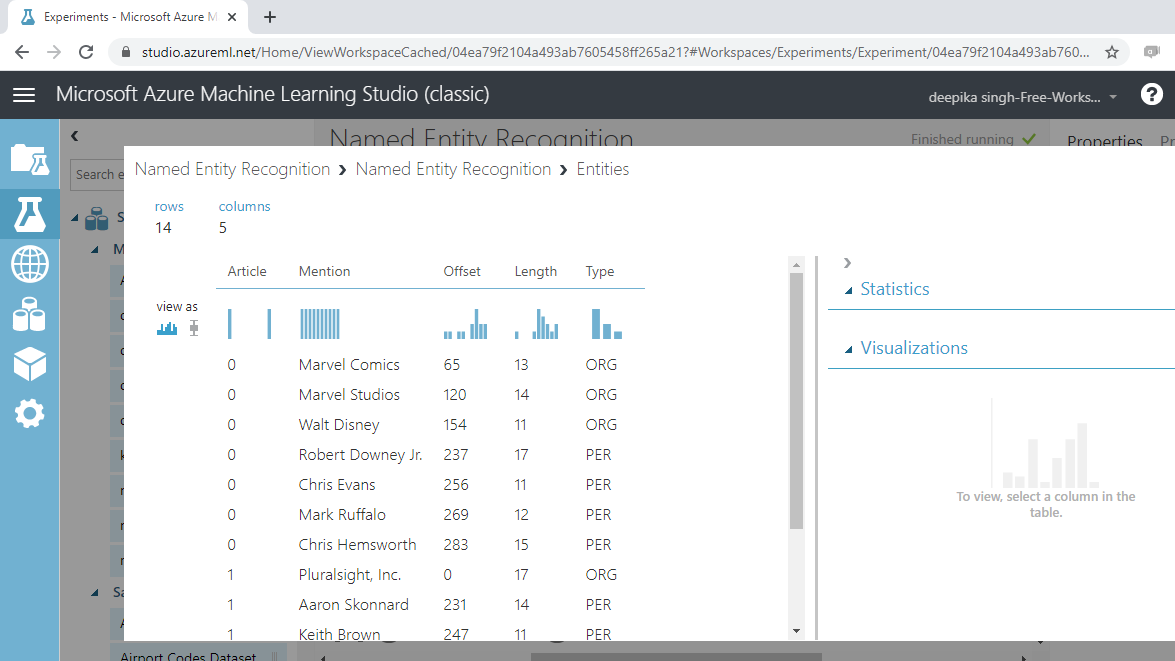
理解输出
模块运行完成后,您可以右键单击并选择“可视化”选项来查看结果。

下面的输出显示了命名实体识别模块处理的结果。输出包含 14 行和 5 列。Article变量表示文本行,Avengers 和 Pluralsight 文本各一行。Mention变量表示已识别的句子部分。
最后,Type变量包含实体的结果。例如,Marvel Studios被识别为ORG,代表组织。同样,Chris Evans被识别为一个人,捐赠为PER。
向下滚动查看 Pluralsight 上第二个文本语料库的输出。Pluralsight , Inc被识别为ORG,而Aaron Skonnard被正确识别为PER。此外,您会注意到该模块已正确识别Farmington和Utah为地点,表示为LOC。
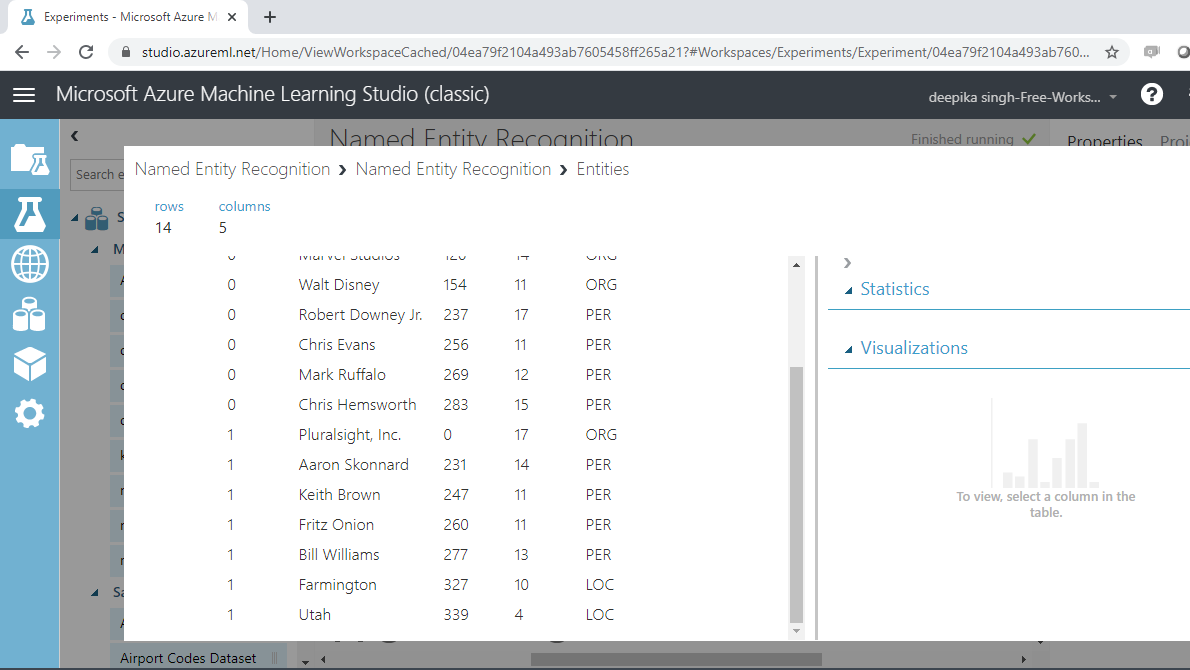
这些简单的数据让我们了解了命名实体识别模块识别名称、位置和实体的强大功能。
结论
命名实体识别是自然语言处理的一个高级领域,企业正在使用它从文本数据中提取有关命名实体的信息。内容推荐、网站交互性改进、概念提取和文本分类是命名实体识别的一些常见应用。您可以通过此 Python 指南了解更多信息。
要了解有关使用 Azure 机器学习工作室进行数据科学和机器学习的更多信息,请参阅以下指南:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~