
使用 RapidMiner 进行机器学习
介绍
RapidMiner 是构建机器学习模型(包括深度学习模型)的最佳工具之一。根据KDnuggets 2018 年民意调查,RapidMiner 位居第二,在实际项目中的使用频率上击败了 R、Excel 和许多其他知名软件包。
在本指南中,您将学习如何使用 RapidMiner 构建您的第一个回归和分类模型。
设置数据
首先,从 Kaggle 下载房价:高级回归技术训练数据集。该数据集有 81 个属性和 1460 条记录。为了专注于机器学习而不是数据清理,创建一个仅包含五个属性的数据集:OverallQual、LotArea、Street、GarageArea和SalePrice。这五个属性将用于构建回归和分类模型。
在 RapidMiner 中加载数据
下载RapidMiner Studio,将其安装到您的设备上,然后注册。注册后,打开软件,您将看到以下对话框:
选择自动模型,它将带您进入以下屏幕:
单击导入新数据按钮,将打开一个新对话框。选择数据集的位置,然后单击下一步几次而不更改数据。最后一步,选择当前数据文件夹或创建一个新文件夹以将数据上传到 RapidMiner。这将带您进入构建机器学习模型的第一步:

建立你的第一个回归模型
要构建回归模型,首先单击“预测”按钮,它将通过显示以下弹出窗口要求您选择目标列:

选择SalePrice列作为目标列,然后单击下一步。这将带您进入下一页,准备目标:
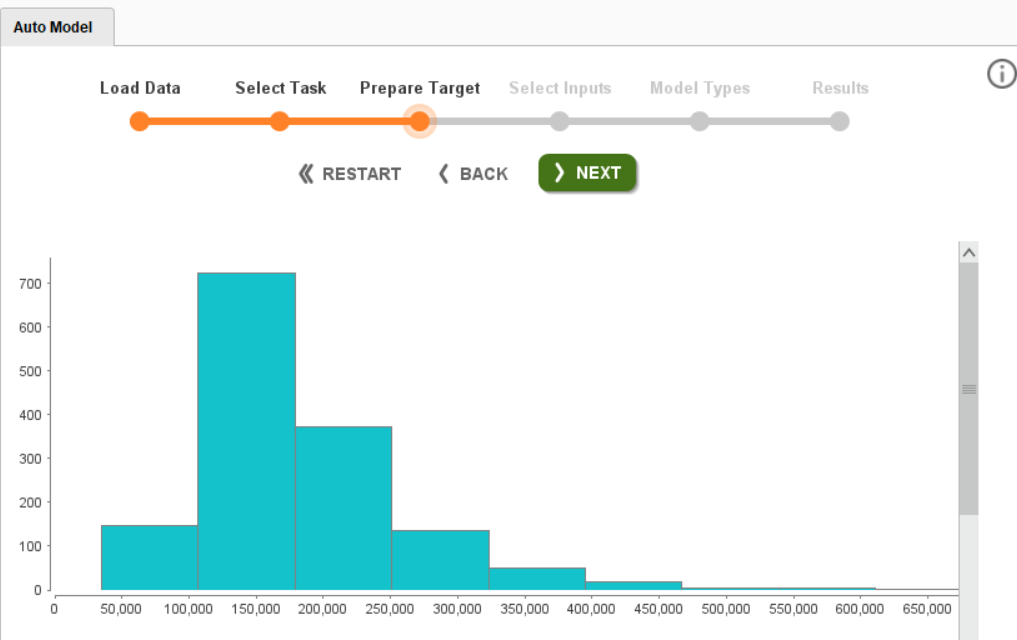
此页面为您提供目标列的直方图。单击下一步,您将进入选择输入页面。此页面提供有关数据集每个独立特征的重要信息。
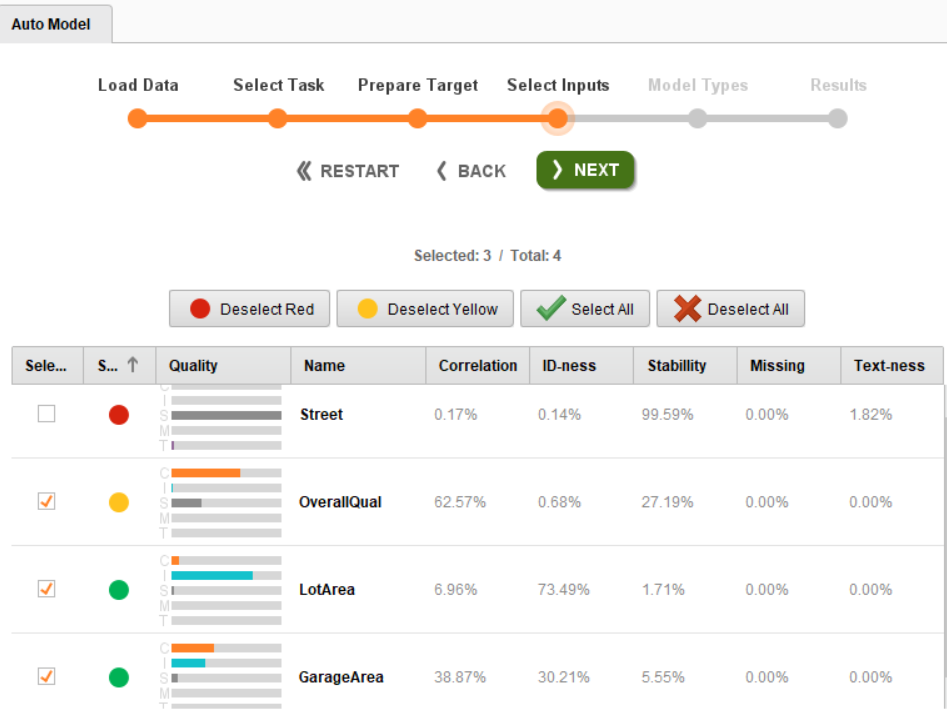
在上图中,请注意 RapidMiner 已经丢弃了Street属性,并对LotArea和GarageArea属性给出了肯定的响应,对OverQual属性给出了中立的响应。您也可以丢弃用黄点突出显示的属性。在这种情况下,所有三个属性(用绿点和黄点标记)都被视为输入。单击Next进入下一页,即Model Types。

如果您了解其他机器学习工具,您可能会在上图中注意到 RapidMiner 通过提供一次性构建所有模型的选项,使构建机器学习模型变得多么方便。您需要做的就是选择项目所需的模型。在这种情况下,所有模型都被选中。
此外,在同一页面上,您还有一些与数据准备相关的选项。您可以根据需要应用这些功能。设置好一切后,单击“运行”。构建完所有模型后,您将看到类似以下页面:

此页面概述了所选指标(可用指标包括均方根误差、绝对误差、相对误差、平方误差和相关性)、运行时间(以毫秒为单位),并指出了哪种模型具有最佳性能(橙色徽章)、最快总时间(蓝色运行火柴人)和最快得分时间(紫色运行火柴人)。
对于此数据集,深度学习模型提供了最佳性能。您可以在概览页面左侧的深度学习下拉菜单下查看完整的模型详细信息、数据预测等。这两个图显示了属性的重要性和此数据集的预测图:
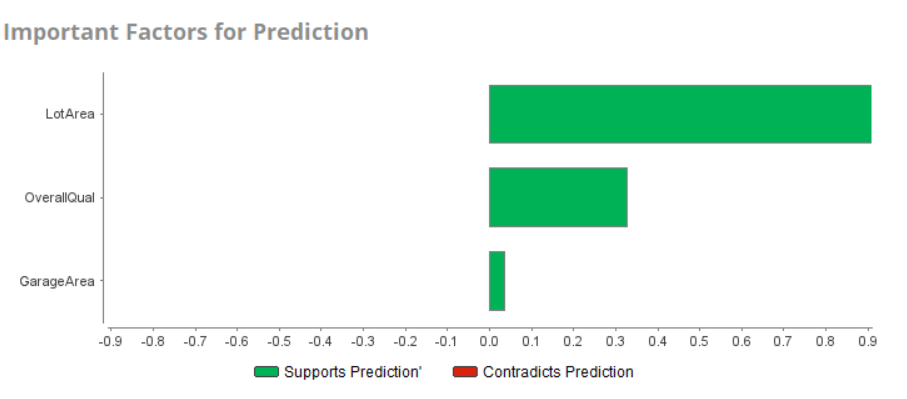
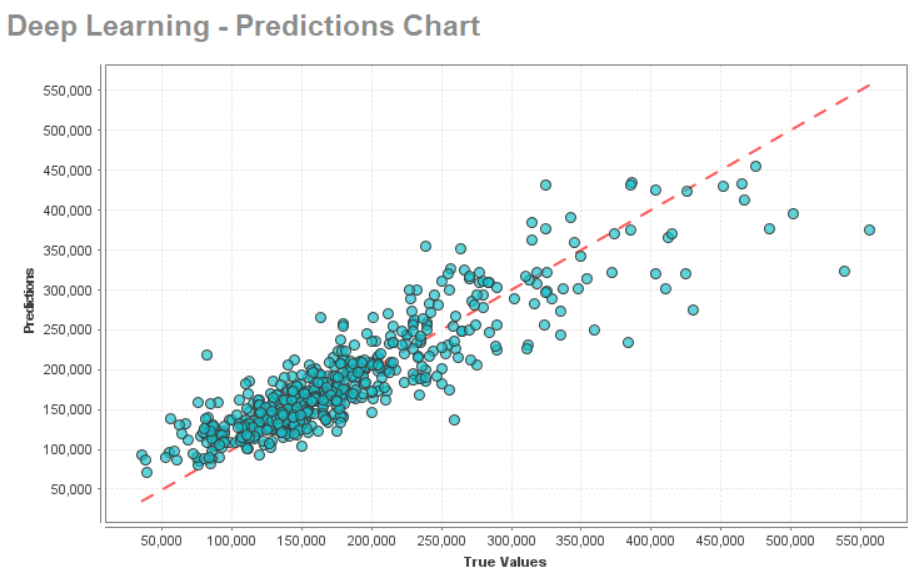
最后,您可以部署深度学习模型并将其导出以供将来使用。
建立你的第一个分类模型
要建立分类模型,大多数步骤与建立回归模型类似。首先,选择具有五个属性的相同数据集,然后单击下一步。单击预测并选择OverallQual属性作为目标属性。
在“准备目标”页面上,您会注意到OverQual属性只有 10 个类,分布在 1 到 10 的整数中。默认情况下,RapidMiner 会构建回归模型。要切换到分类方面,请切换直方图下方的按钮“转换为分类”,并将类数从 2 更改为 10。
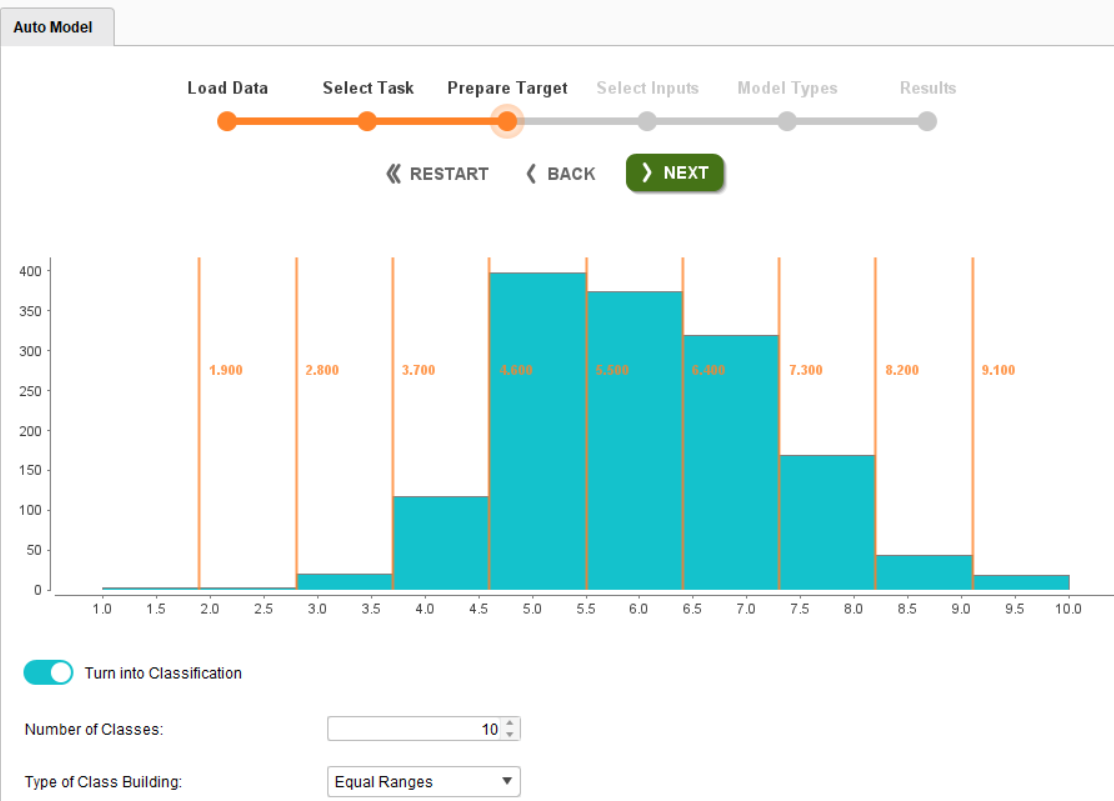
完成上述所有更改后,单击“下一步”。在“选择输入”页面上,您有三个支持属性和只有一个不支持属性。
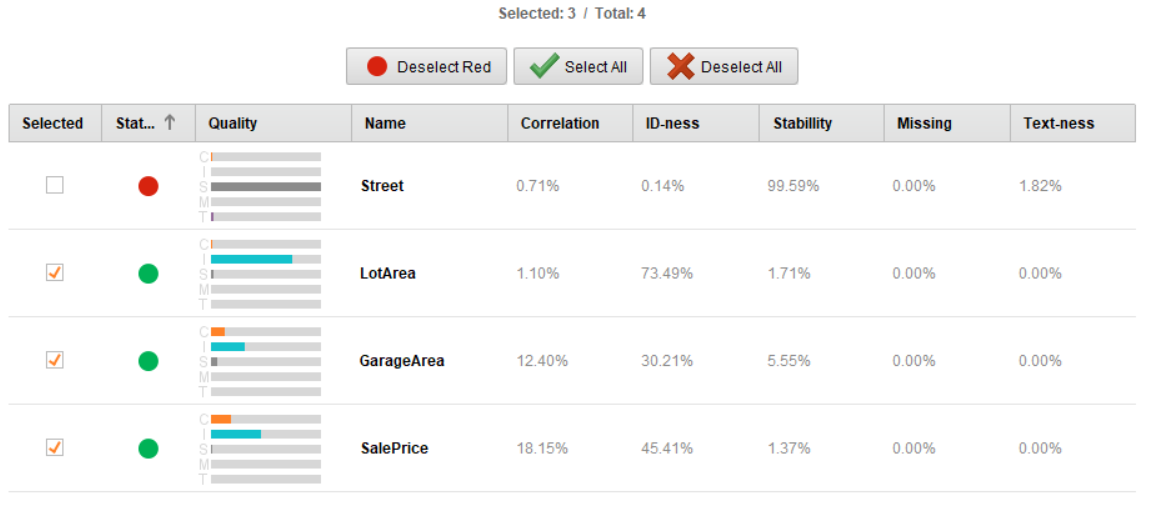
单击下一步进入模型类型页面。由于您正在构建分类模型,您将收到一个新的模型列表,如下所示:
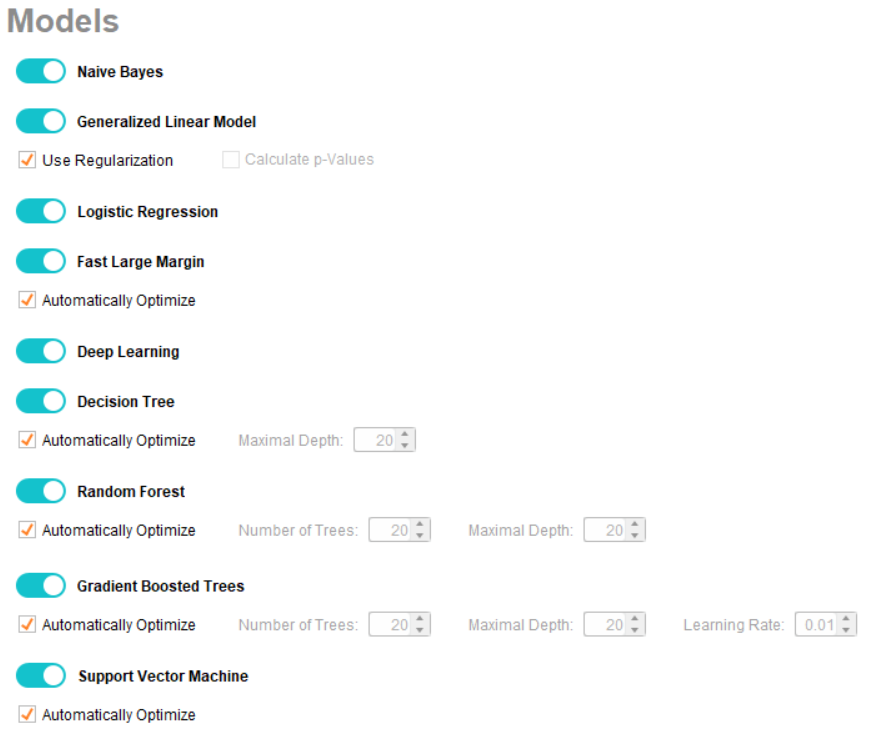
您可以从此列表中选择任意数量的模型。目前,所有模型都已选中。您还有一个数据准备列,类似于回归场景。单击运行,一旦所有模型都构建完毕,您将看到此概览页面:

对于此数据集,深度学习模型再次表现最佳,并且提供最佳增益(橙色美元符号图标)。与每个属性相关的权重如下所示:
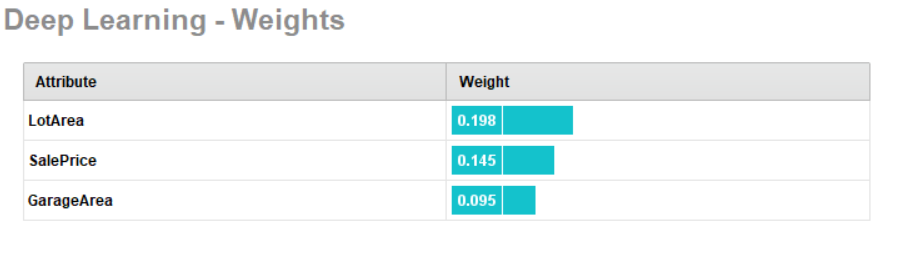
您可以根据需要进一步优化此模型或其他模型,并将其导出以供将来使用。
结论
RapidMiner 可帮助您通过几次点击构建多个预测模型,因此比 Python 和 R 等其他机器学习语言更具优势。您可以使用 RapidMiner 在数据集上快速测试常用模型,然后自定义性能最佳的模型。要了解有关 RapidMiner 的更多信息,请阅读Pluralsight 上的RapidMiner:入门课程。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~