
使用 Azure 机器学习 Studio 进行文本分析
介绍
自然语言处理 (NLP) 无处不在,具有多种应用。一些用例包括将电子邮件分类为垃圾邮件和正常邮件、聊天机器人、AI 代理、社交媒体分析以及将客户或员工反馈分类为正面、负面或中性。本指南将演示如何使用 Azure 机器学习工作室在文本数据上构建监督机器学习模型。
数据
在本指南中,您将承担医学领域自动化评审的任务。医学文献数量庞大且变化迅速,这增加了评审的需求。此类评审通常由人工完成,既繁琐又耗时。您将尝试通过构建一个文本分类模型来自动化该过程,以解决此问题。
您将使用的数据集来自PubMed搜索,包含 1,748 个观测值和 4 个变量,如下所述。
title:由检索到的论文标题组成的变量
abstract:包含检索到的论文摘要的变量
试验:变量表明该论文是否是测试癌症药物治疗的临床试验
class:目标变量,表明该论文是否为临床试验(是)或不是(否)
您将从加载数据开始。
加载数据
登录 Azure 机器学习工作室帐户后,单击左侧栏列出的“实验”选项,然后单击“新建”按钮。
接下来,点击空白实验,将打开一个新的工作区。将工作区命名为“文本分析”。

接下来,您将数据加载到工作区中。单击NEW,然后选择如下所示的DATASET选项。
上面的选择将打开如下所示的窗口,可用于从本地系统上传数据集。
加载数据后,您可以在“已保存的数据集”选项中看到它。文件名为nlpdata2.csv。下一步是将其从“已保存的数据集”列表拖到工作区中。要浏览此数据,请右键单击并选择“可视化”选项,如下所示。
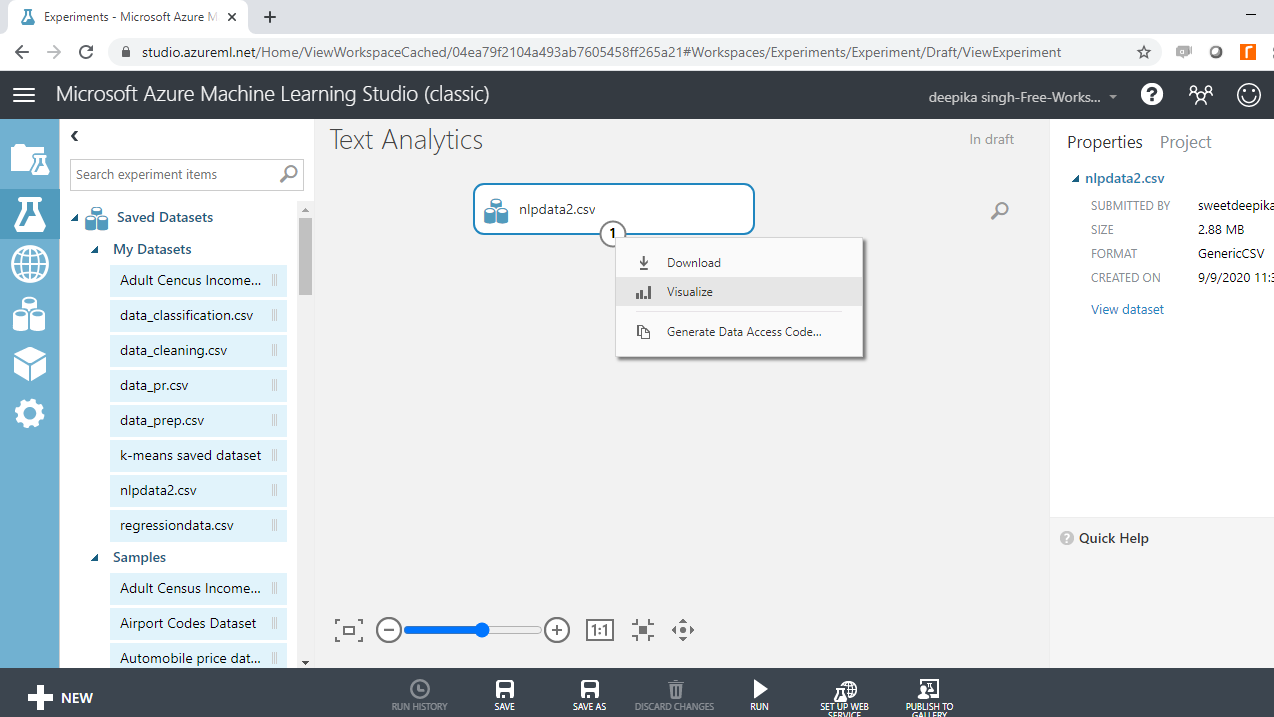
选择不同的变量来检查基本统计数据。例如,下图显示目标变量类的详细信息。
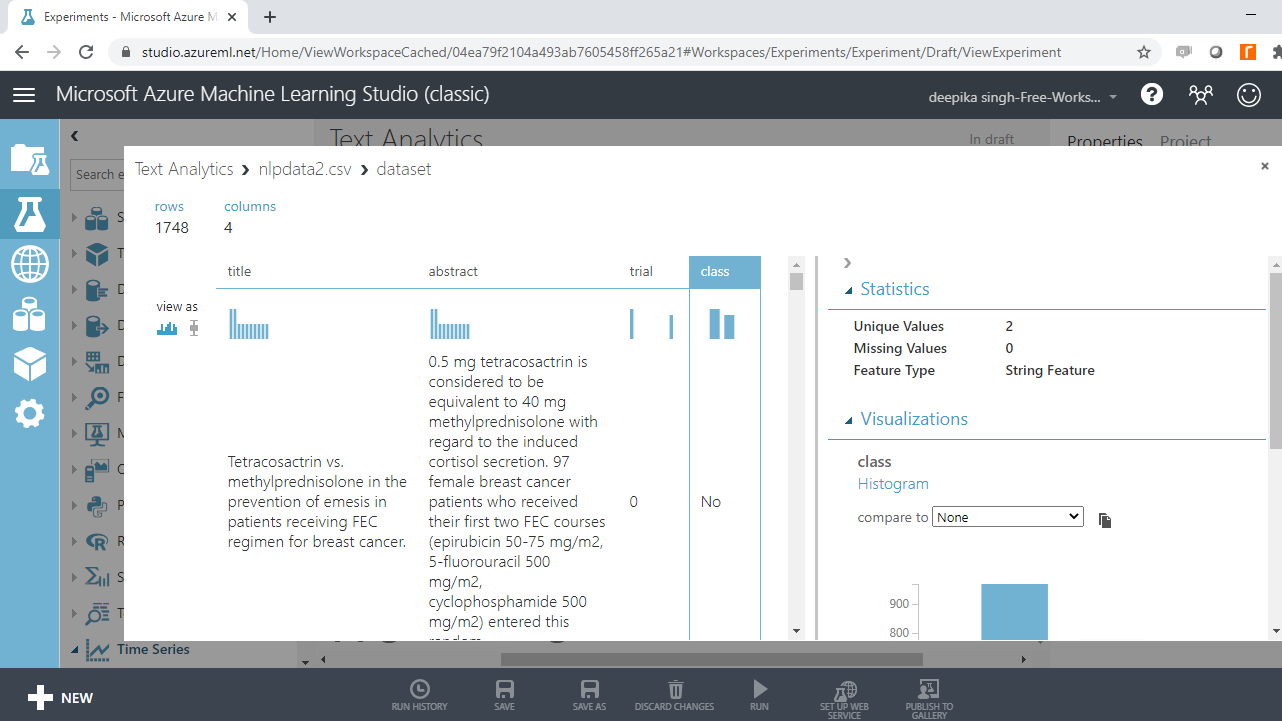
您会注意到目标变量有两个唯一值。此外,它显示为字符串特征,需要转换为分类特征。
转换数据类型
首先在搜索栏中输入“编辑元数据”以找到编辑元数据模块,然后将其拖入工作区。
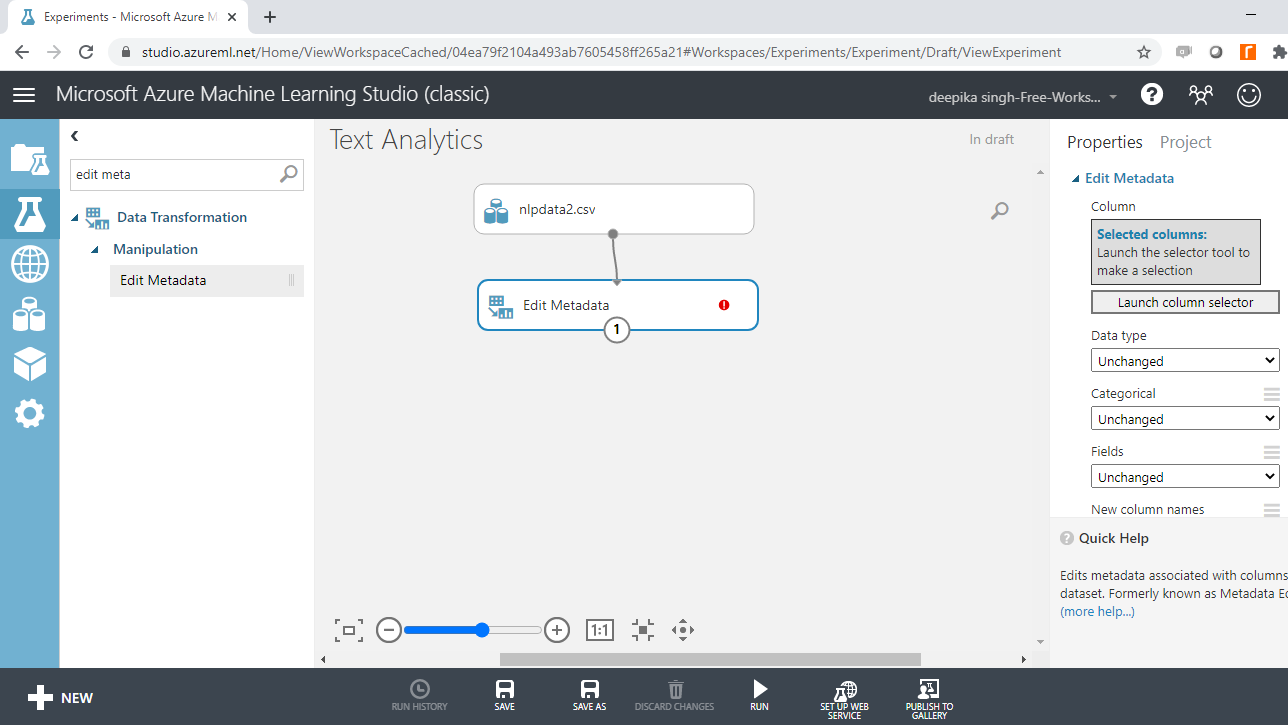
下一步是单击启动列选择器选项,然后选择类变量。
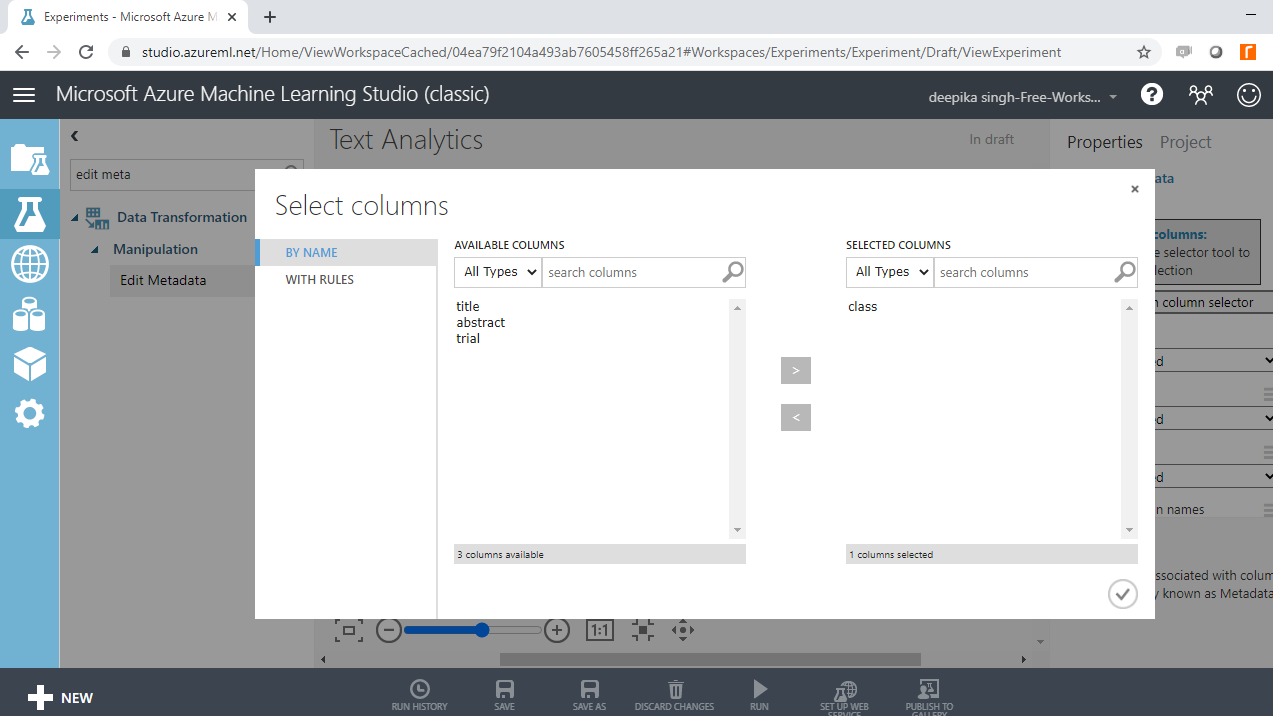
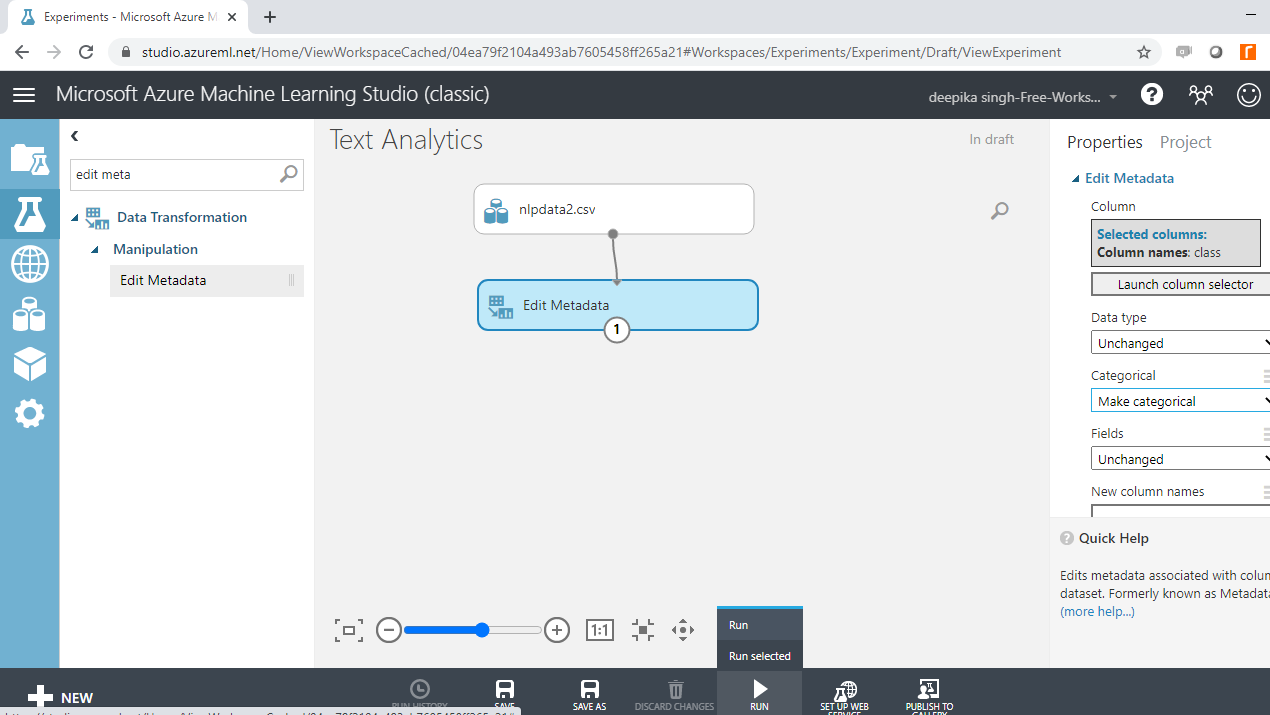
完成此选择后,所选列将显示在工作区中。接下来,从“分类”下的下拉选项中选择“制作分类”选项。接下来,运行实验。
预处理文本
现在,您可以构建文本分类器了。然而,这正是 NLP 中事情开始变得棘手的地方。数据是原始文本格式,不能用作特征。因此,这需要文本预处理。
下面给出常见的预处理步骤。
删除标点符号:经验法则是删除所有不属于 x,y,z 形式的内容。
删除停用词:这些是无用的词,例如“the”、“is”、“at”。这些词没有帮助,因为此类停用词在语料库中出现的频率很高,但它们无助于区分目标类别。删除停用词也会减少数据量。
转换为小写:像“Clinical”和“clinical”这样的词需要被视为一个词。因此,这些词被转换为小写。
词干提取:词干提取的目的是减少文本中出现的单词的屈折形式数量。这使得诸如“argue”、“argued”、“arguing”和“argues”等单词被简化为它们的共同词干“argu”。这有助于减少词汇空间的大小。
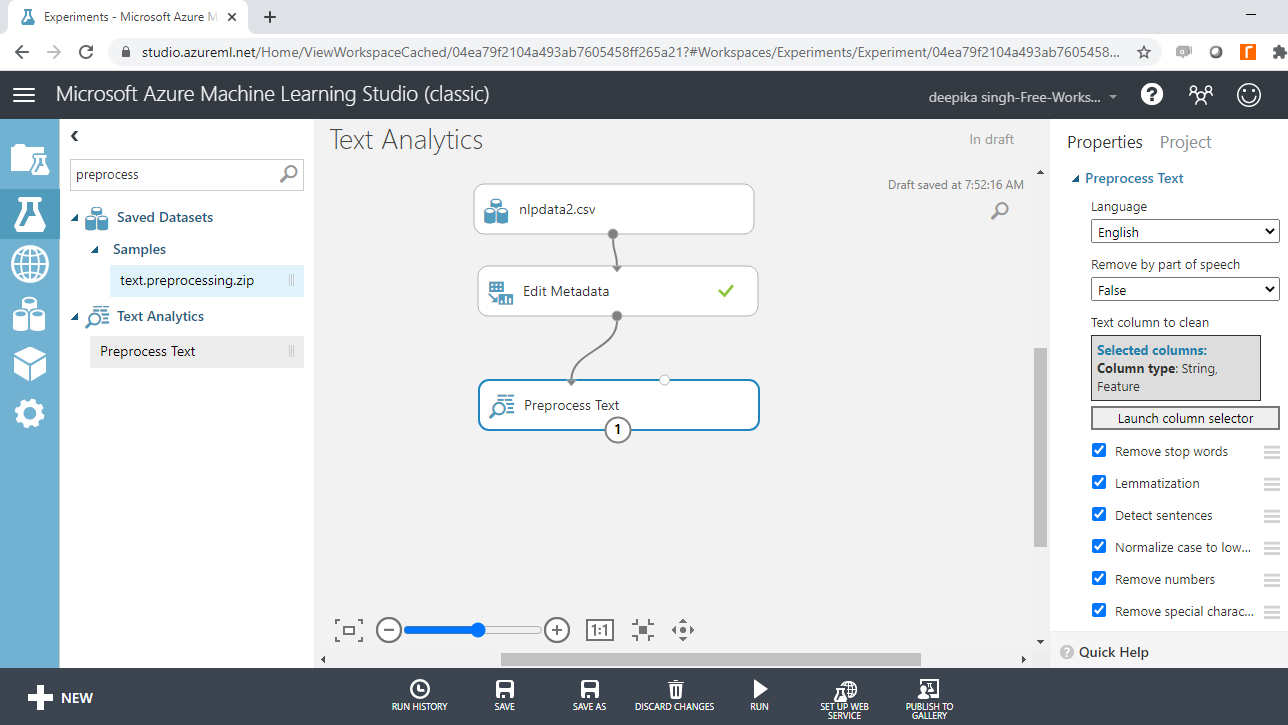
您必须指定要预处理的文本变量。为此,请单击启动列选择器选项,然后选择抽象变量。
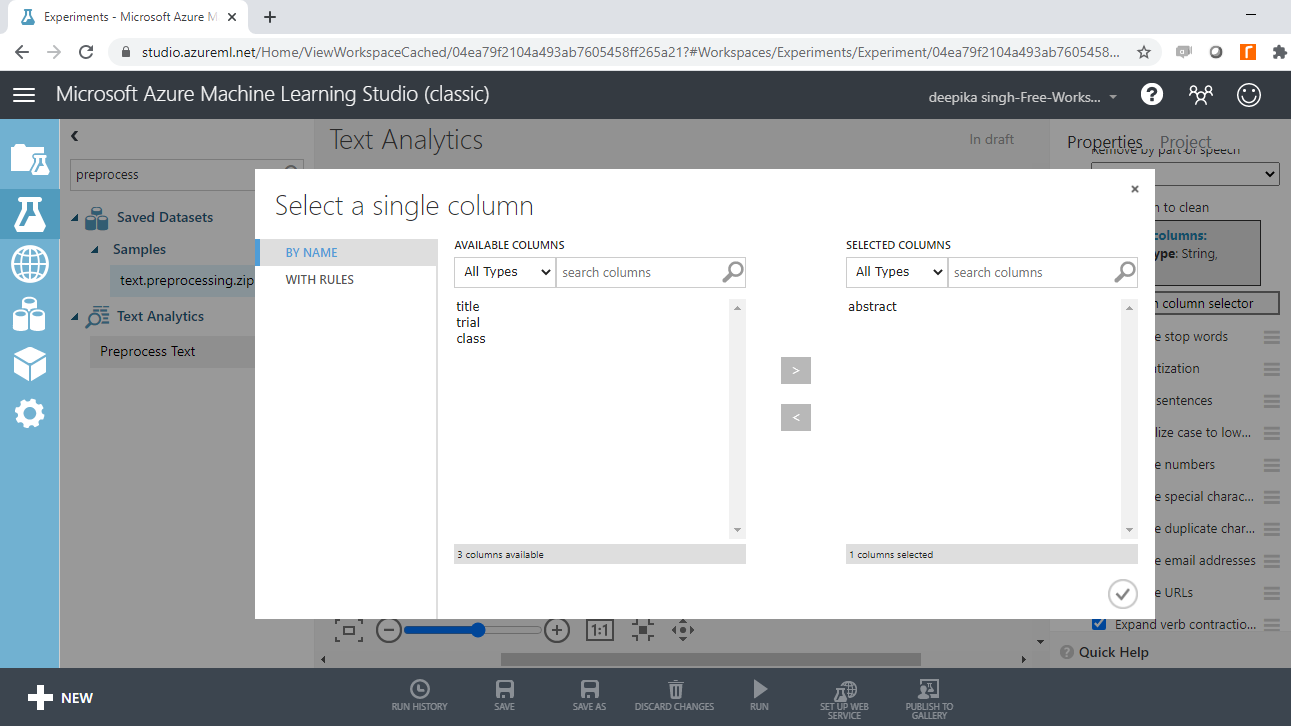
有几种文本清理选项,由于这是临床研究数据,可能具有复杂的结构,因此您将选择所有选项。运行实验。
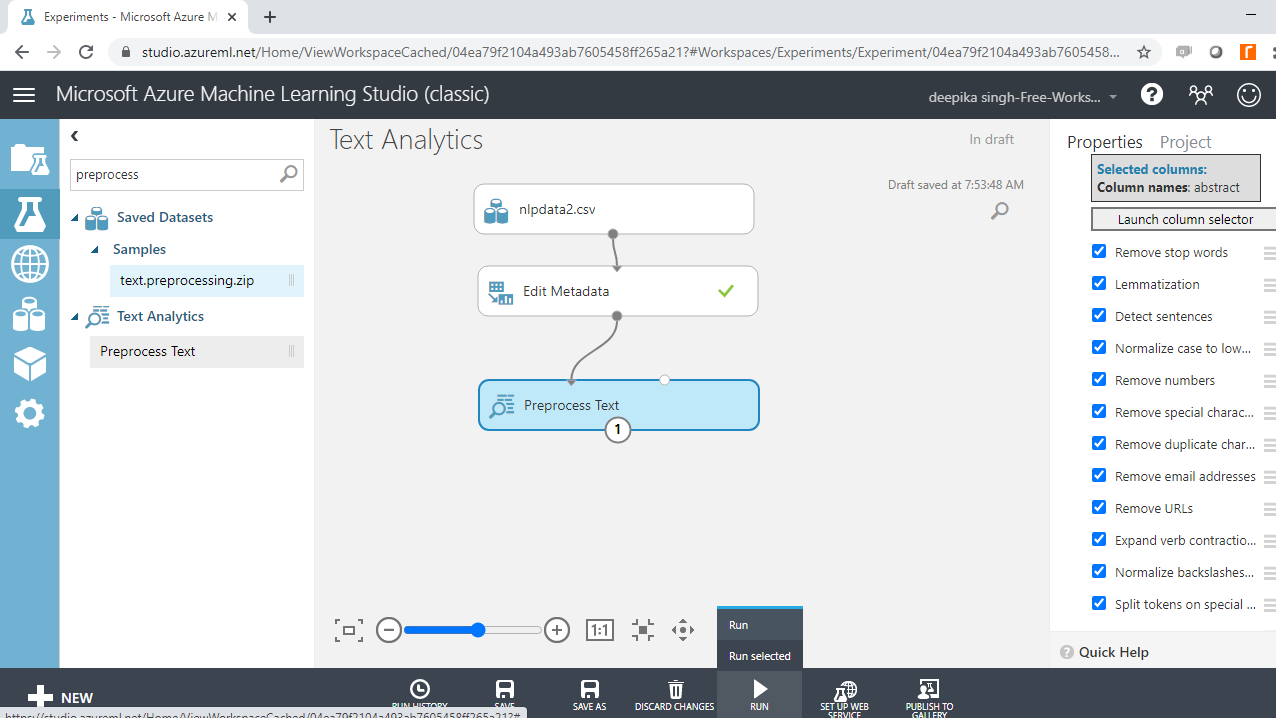
下一步是探索生成的预处理数据。右键单击并选择“可视化”选项。
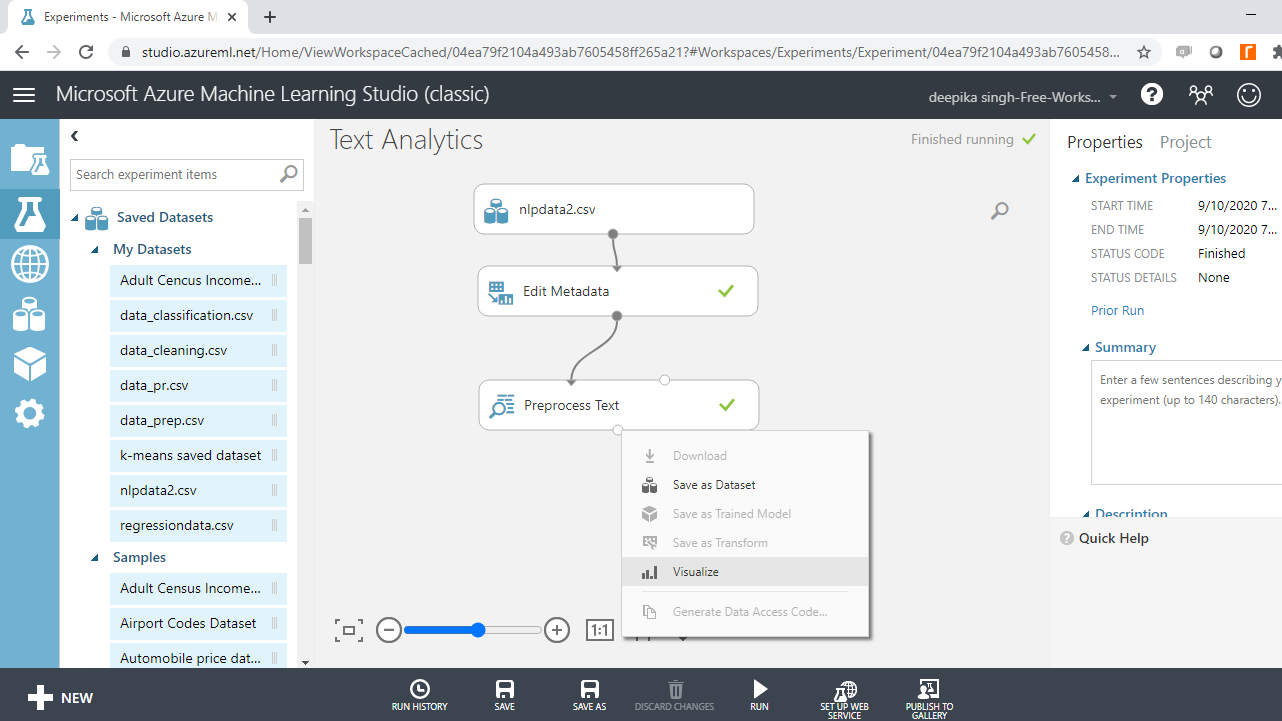
下面的输出显示添加了一个变量Preprocessed abstract ,它包含在Preprocess Text模块中所做的更改。
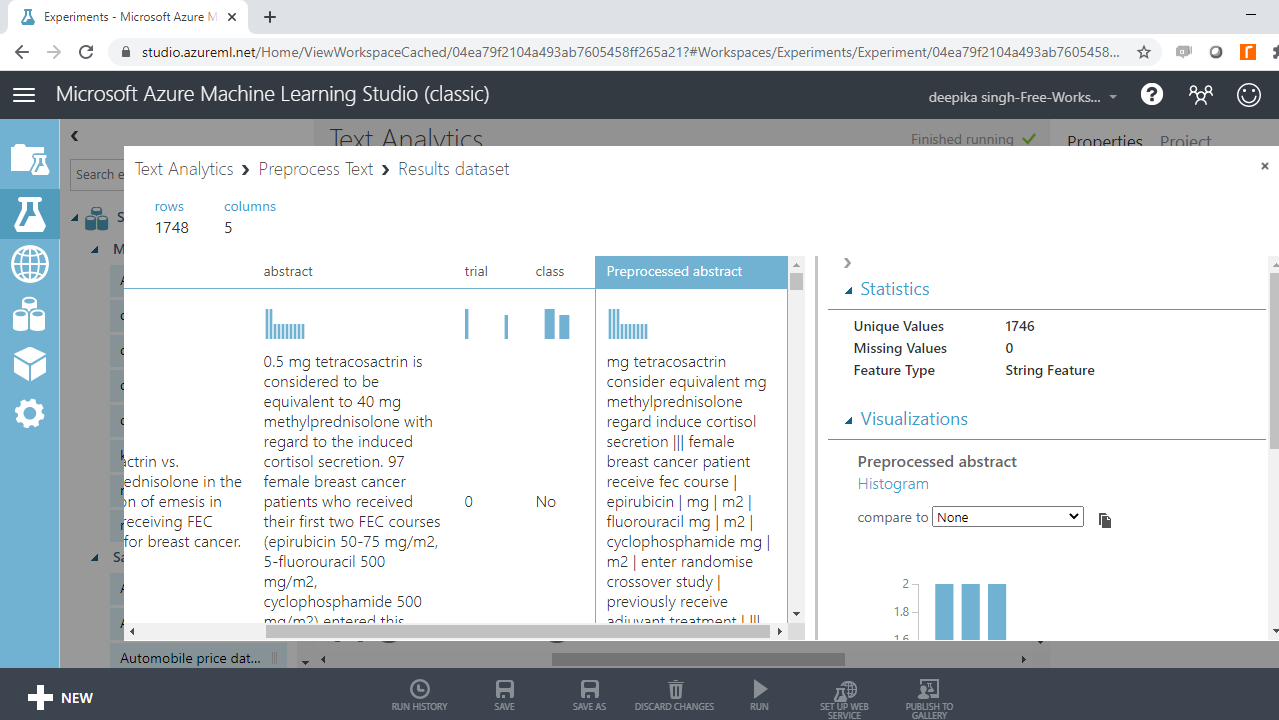
运行实验。
特征生成
您已对文本进行了预处理,下一步是生成一组特征。这是通过特征哈希模块完成的。它的工作原理是,它获取文本变量并将其转换为以整数表示的一组特征。搜索并将特征哈希模块拖到工作区中。
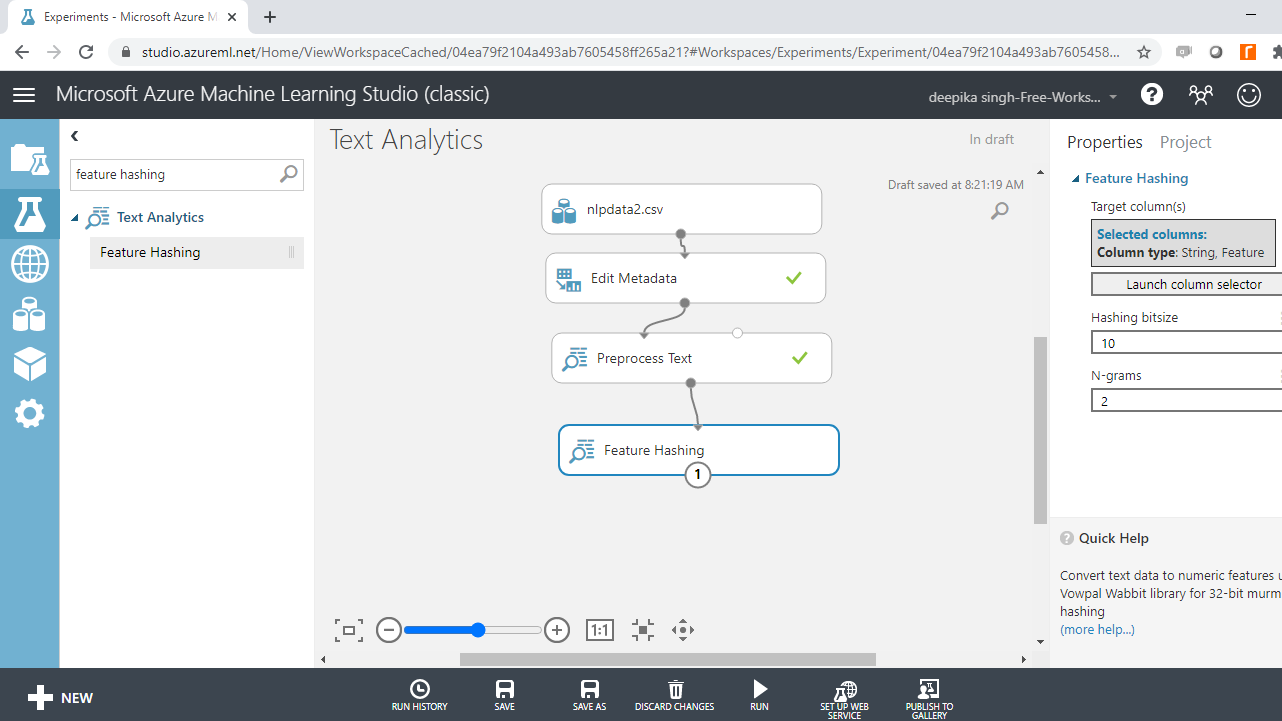
单击启动列选择器选项,然后选择预处理的抽象变量。
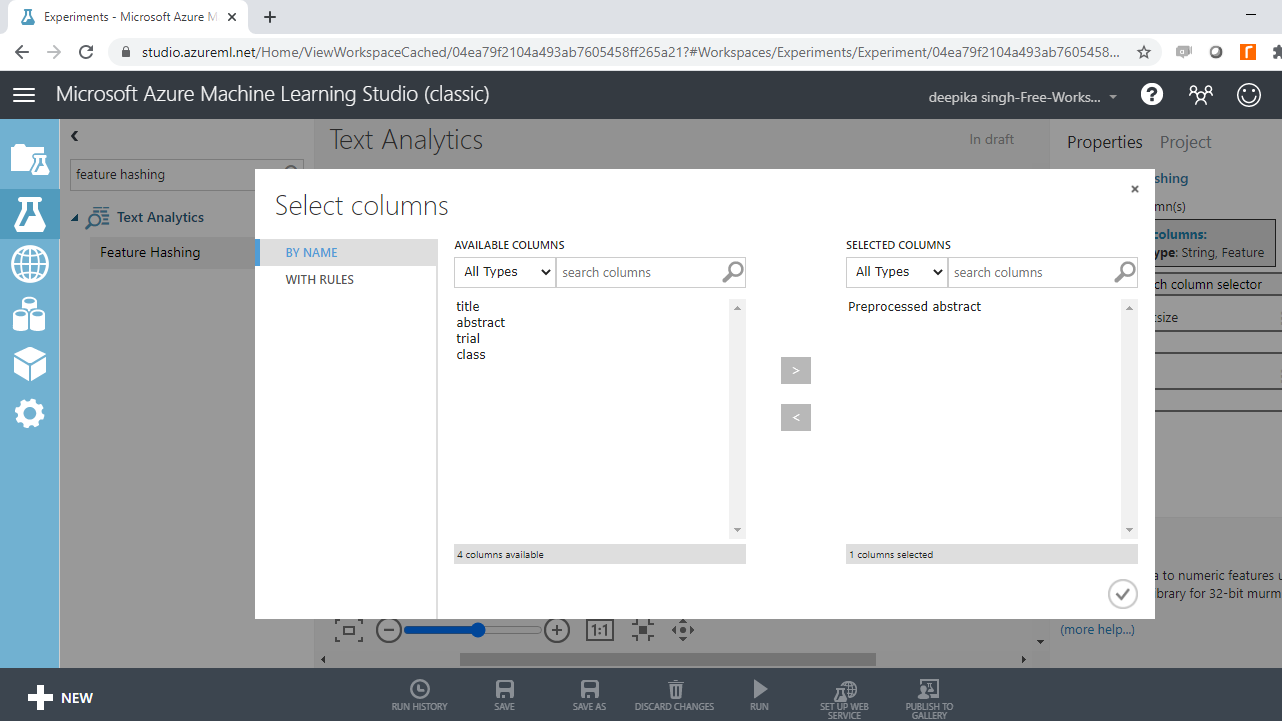
Next, use the Hashing bitsize parameter to specify the number of bits to use when creating the hash table. Keep the default option of ten. The next step is to provide the value to N-grams parameter. Set the value to two. This argument defines the length of the word sequence. Keeping the value to two will result in creation of two word sequences, along with unigrams. Run the experiment.
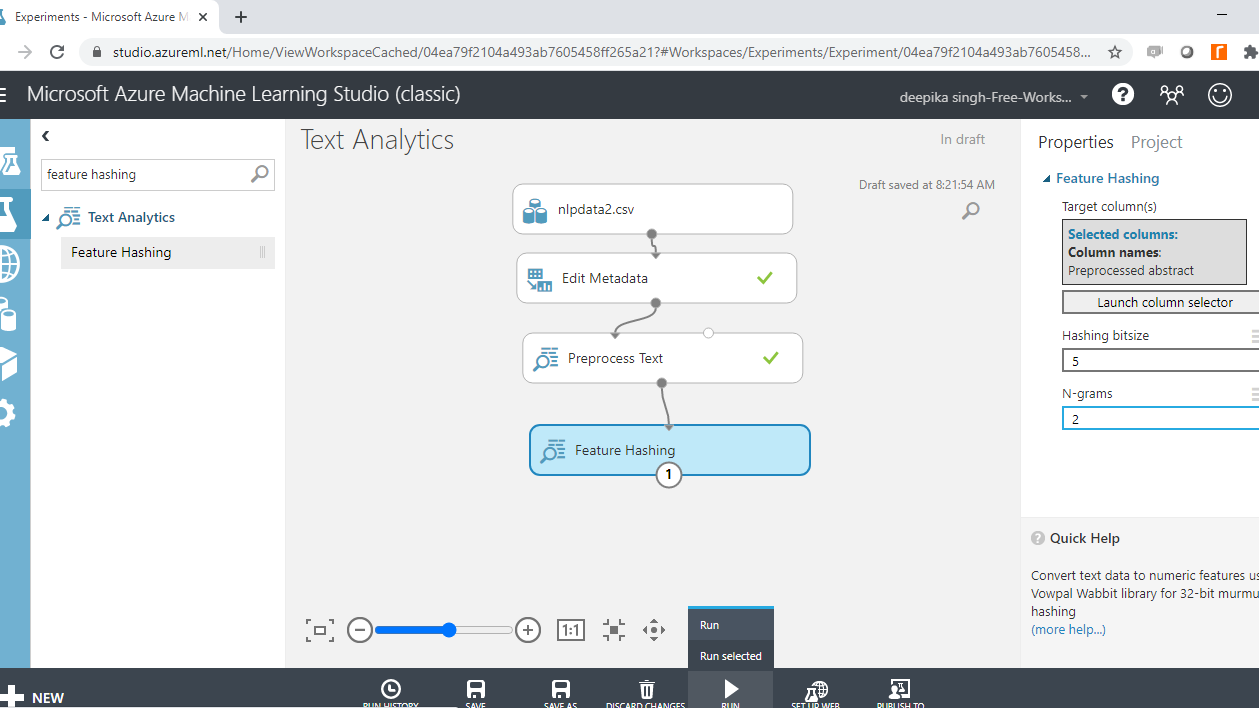
Once the experiment run is complete, right click and select the Visualize option.
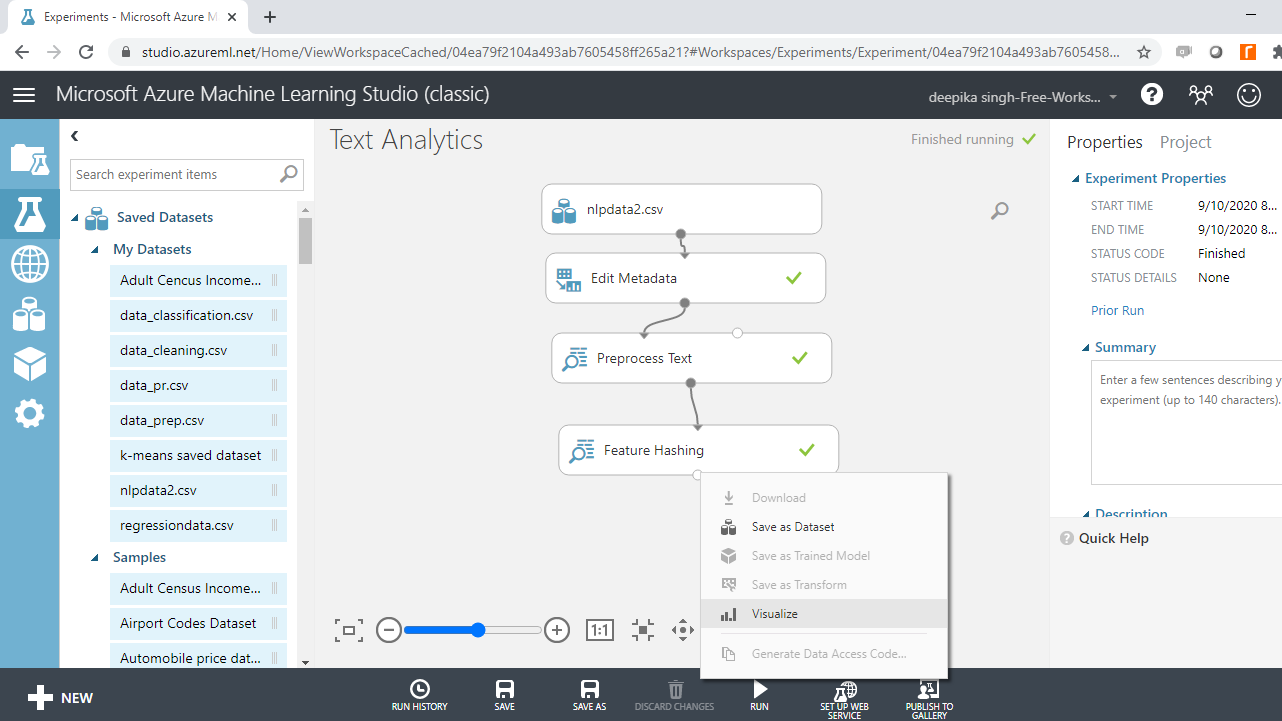
Completing the above step will result in the output below. You can see that new features have been added to the data, which now has 1748 observations and 37 columns.

Select Columns of Interest
You have created new features, and the next step is to select the variables of interest. The Select Columns in Dataset module performs this task. Drag it to the workspace.
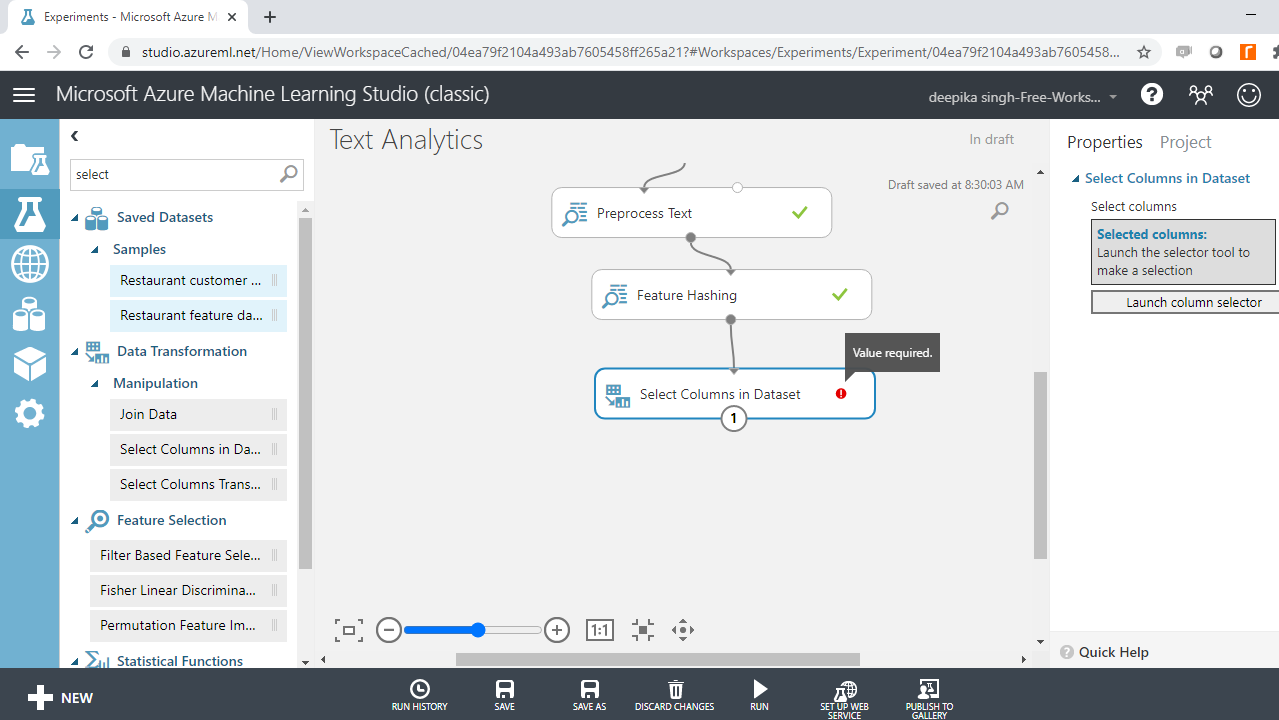
Select the variables of interest with Launch column selector. The target variable, class, and the preprocessed hashed features will be included in model building.
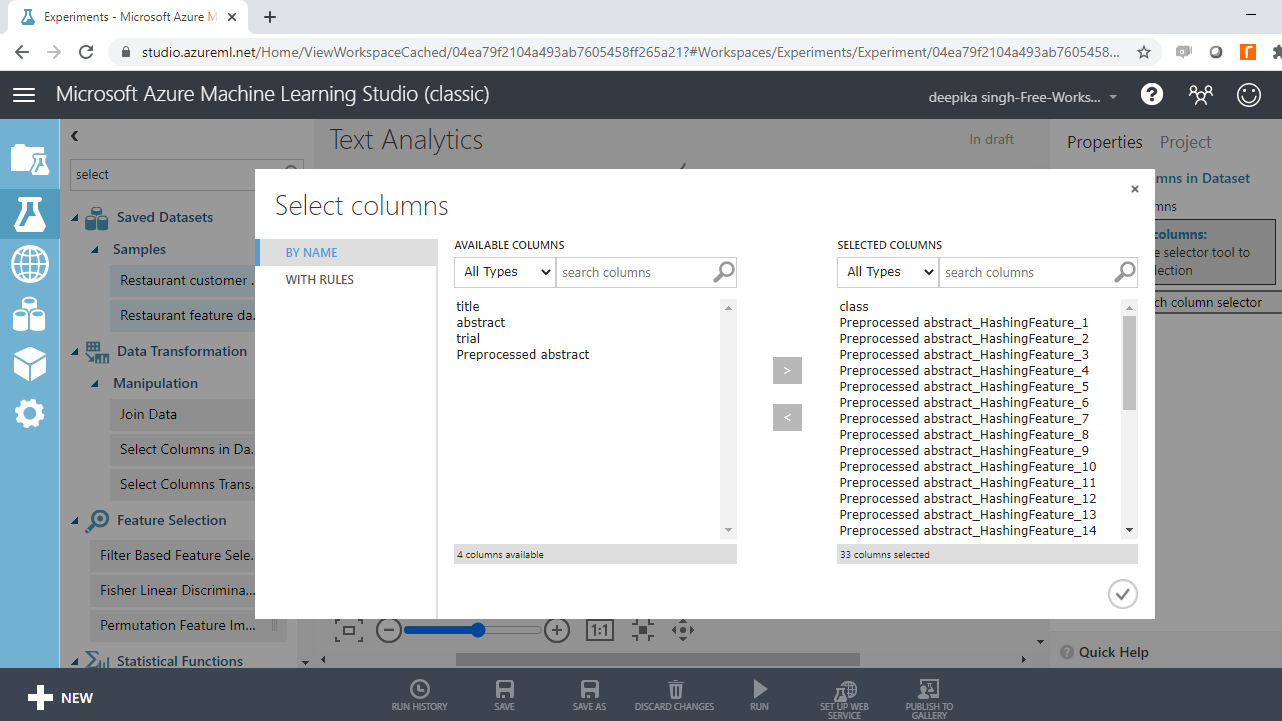
Run the experiment.
Model Building
You have converted the text data into a format of independent variables, and a target variable. The next step is to build the machine learning model. You will build the classifier with the Two Class Boosted Decision Tree module. Search and drag it in the workspace.
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~