
Azure 机器学习工作室中的无监督机器学习
介绍
无监督学习是一种机器学习算法,其中洞察是从没有任何因变量的数据中生成的。无监督学习有几种用例。最流行的用例是市场细分,将市场或客户群划分为不同的集群。这有助于制定有针对性的营销策略。无监督学习的另一个应用是关联挖掘或构建推荐引擎。最常见的无监督机器学习技术是k 均值聚类。
K 均值聚类是将观测值划分为k 个聚类的过程。 一个聚类内的记录相似,而 k 个聚类彼此不同。 K 均值聚类的成功取决于算法创建这些分区的能力。 本指南将演示如何在 Azure 机器学习工作室中配置、训练和理解无监督的 K 均值聚类模型。
数据
在本指南中,您将使用 Azure 机器学习工作室中提供的 Pima Indian 糖尿病数据集。该数据最初来自美国国家糖尿病、消化和肾脏疾病研究所。该数据集包含多个变量,例如患者的怀孕次数、BMI、胰岛素水平、年龄等。您可以在此处查看这些数据。
您将从加载数据开始。
加载和探索数据
登录 Azure 机器学习工作室帐户后,单击左侧栏列出的“实验”选项,然后单击“新建”按钮。
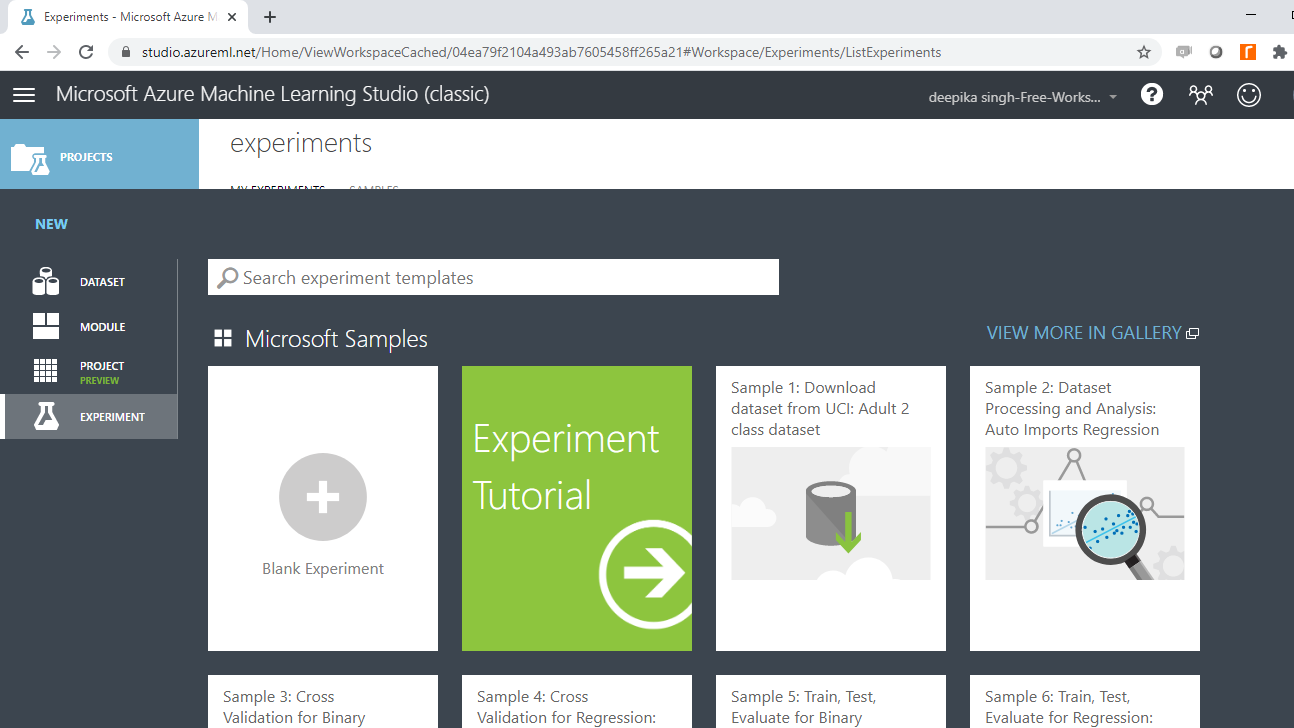
接下来,点击空白实验并将实验命名为“Clustering”。在保存的数据集下,将Pima Indians Diabetes数据集拖到工作区中。
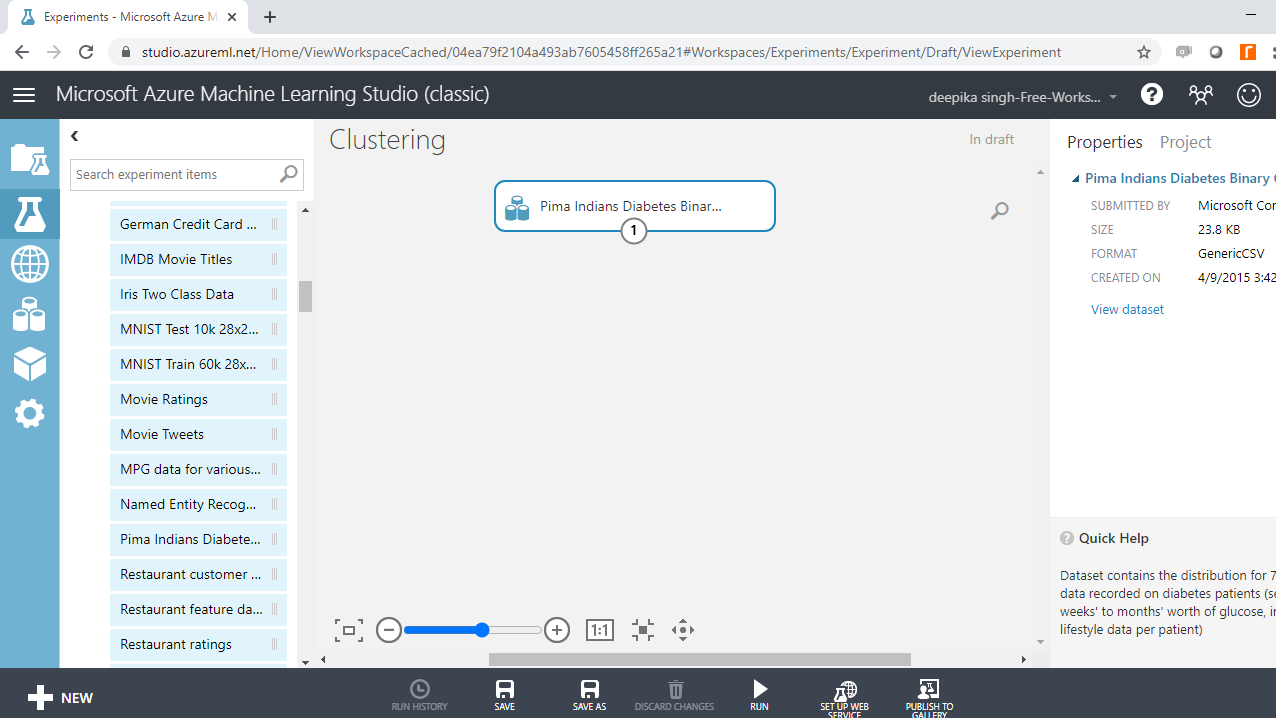
加载数据后,下一步就是探索它。为此,右键单击并选择“可视化”选项,如下所示。这有助于理解数据的结构。
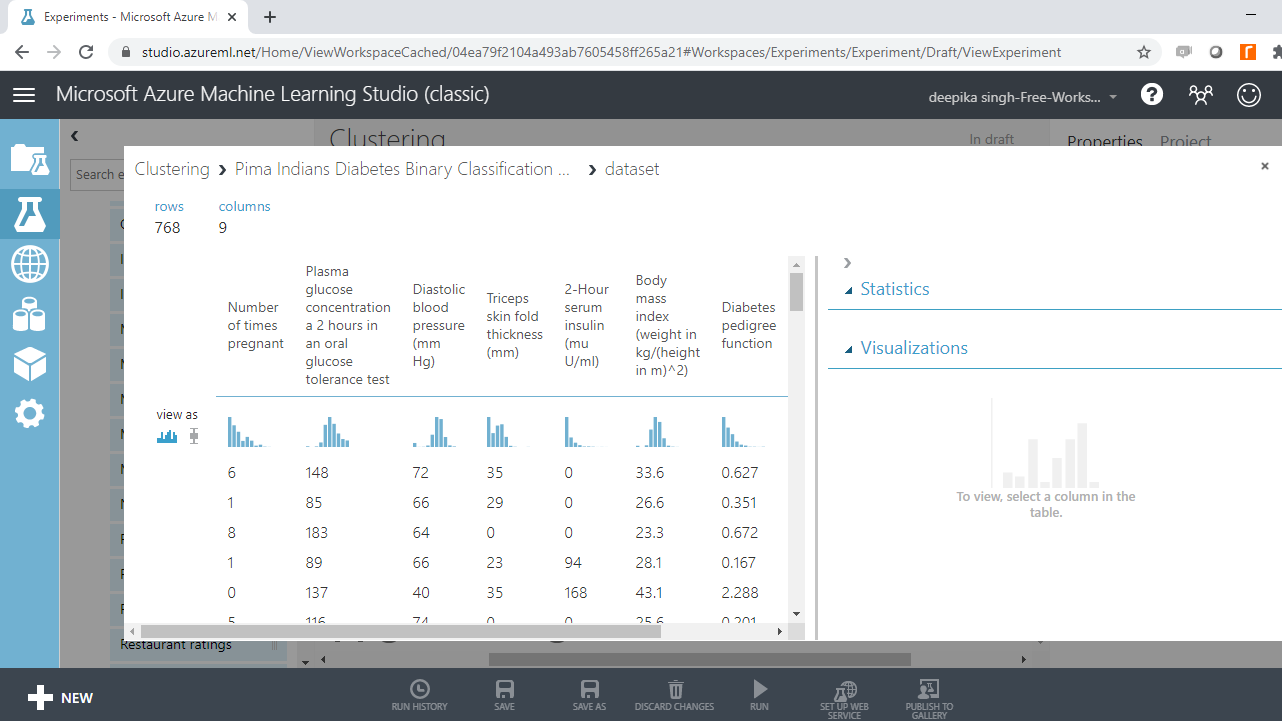
数据包含 768 行和 9 列。您可以通过单击来检查任何变量。
K 均值聚类
K 均值聚类是一种无监督机器学习算法,用于根据相似性指标将相似的项目分组在一起。 Azure 机器学习工作室中的K 均值聚类模块用于配置和创建 K 均值聚类模型。 首先搜索模块并将其拖到工作区中。
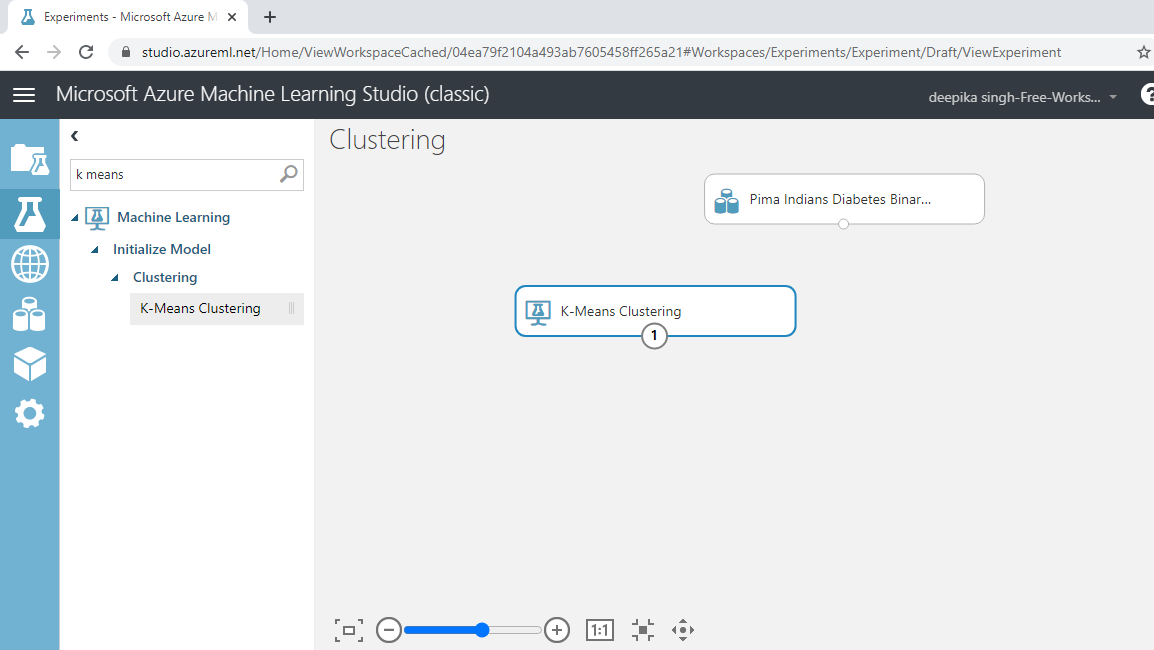
配置 K-means 模块
工作区中已有模块,下一步是对其进行配置。对于“创建训练器模式”,选择“单参数”选项,当您知道如何配置算法时会使用该选项。第二个参数是“质心数”,表示开始时的簇数。将此值设置为 5。最终的簇数可能与此不同,但这有助于算法以数字开始。
初始化方法是K-Means++,这是启动聚类的默认方法。在随机数种子中输入一个整数值以确保可重复性。对于度量,选择欧几里得方法,这是一种计算聚类点之间距离的方法。
Iterations参数指定算法将经历的迭代次数,以确定质心的数量。将此值设置为 100。其他选项保留默认设置,如下所示。
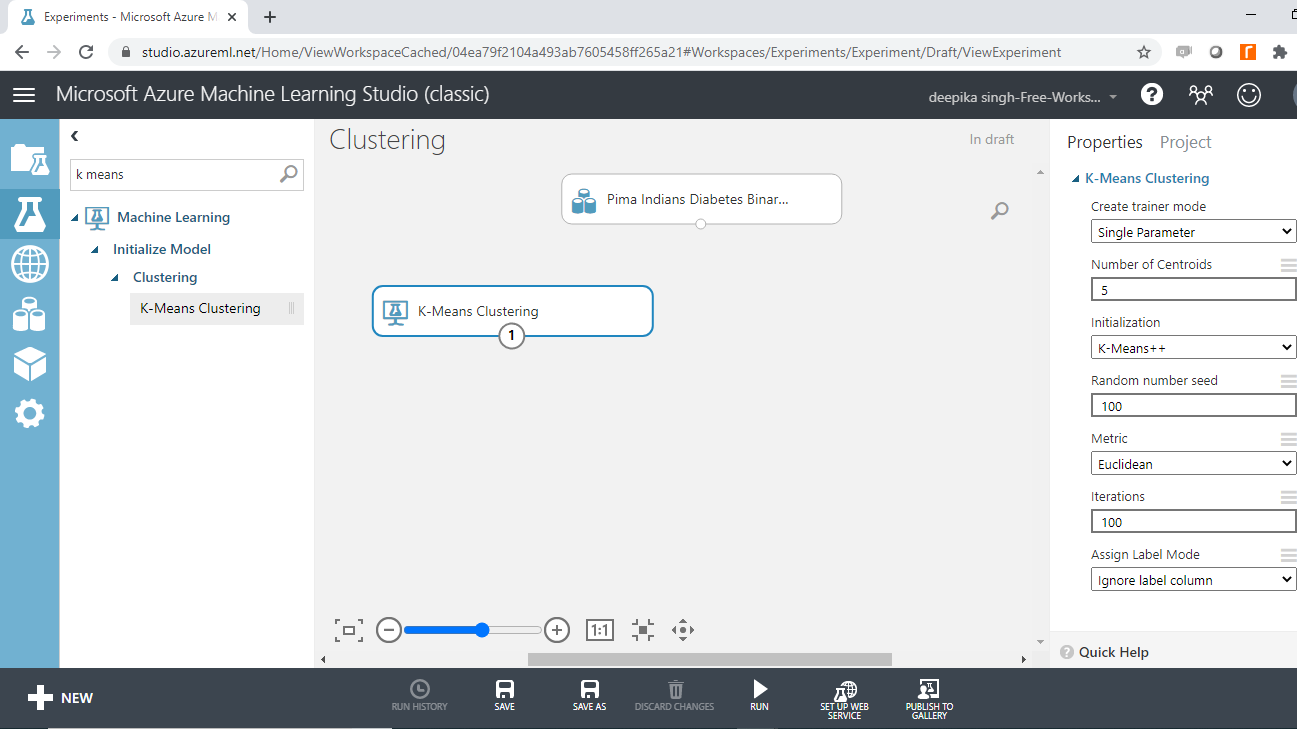
训练聚类模型
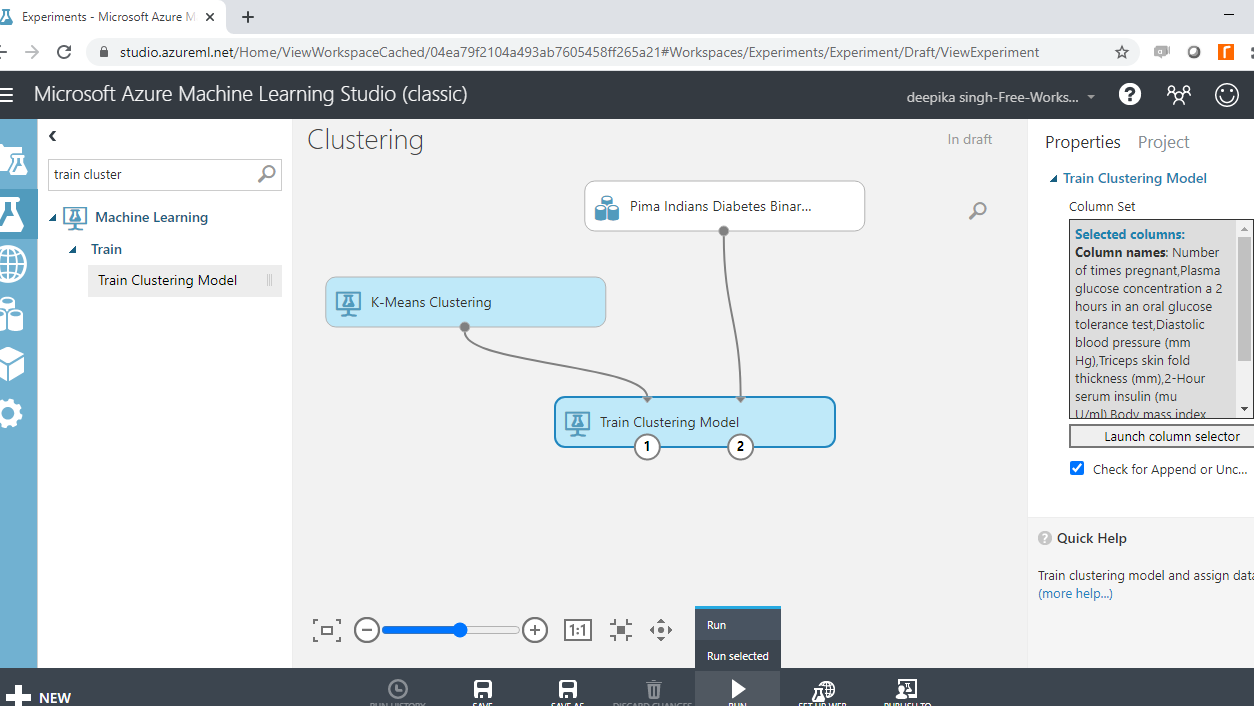
**训练聚类模型**模块用于训练聚类模型,搜索并将该模块拖入工作区,并按照下图所示与其他模块连接。
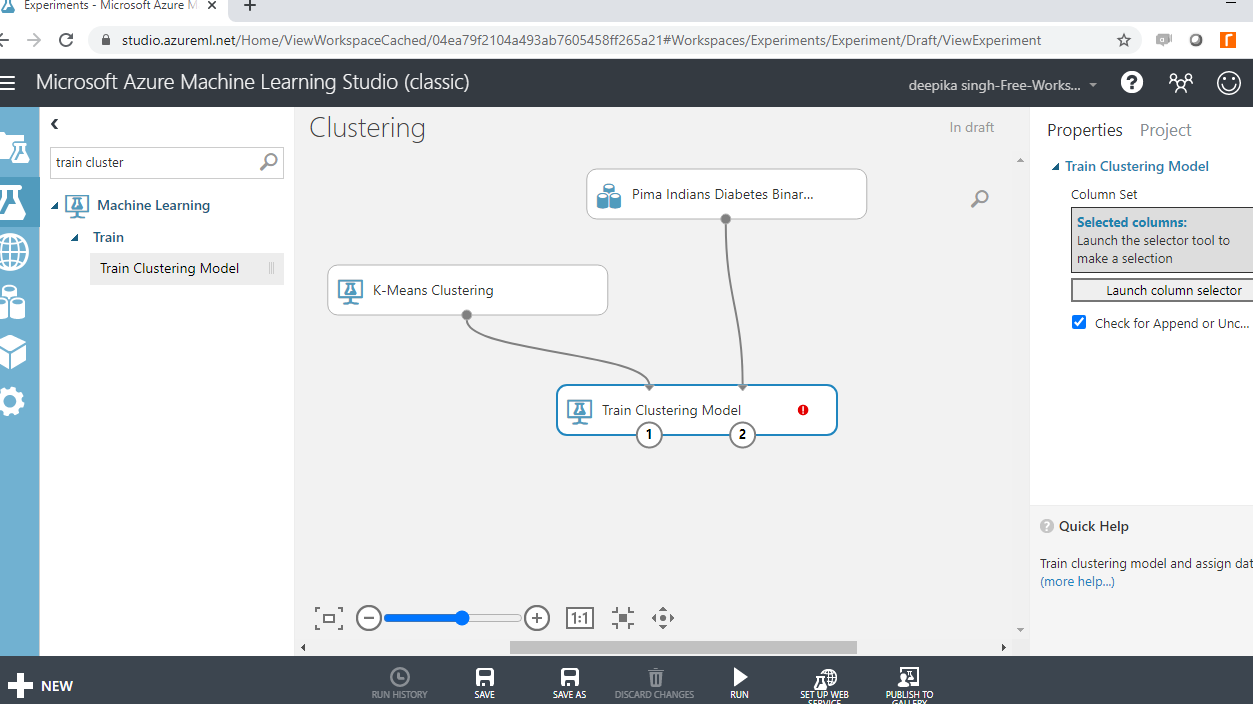
您可以在“训练聚类模型”模块旁边看到红色标记,表示需要更正某些内容。单击“启动列选择器”选项,然后选择所有数值变量,如下所示。您将只选择数值变量,因为无法计算分类变量的距离。
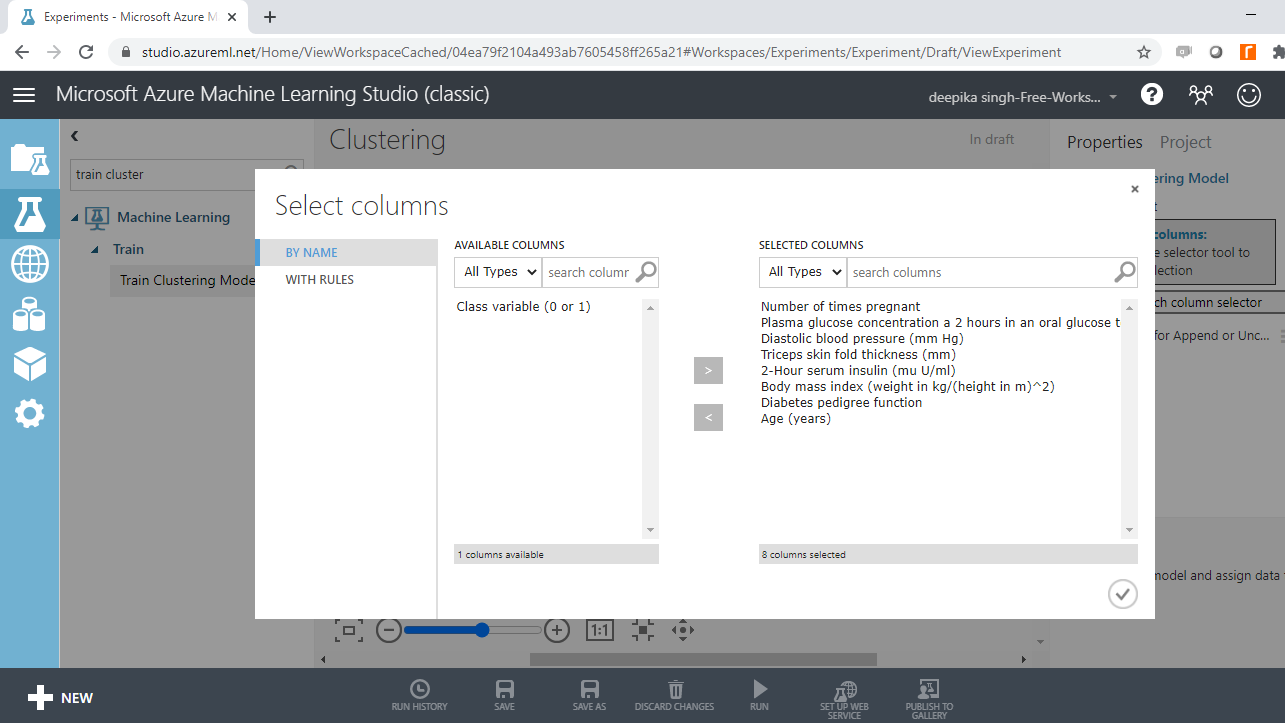
运行实验。
了解集群分配
实验运行成功,结果存储在训练聚类模型模块的右侧输出端口中。
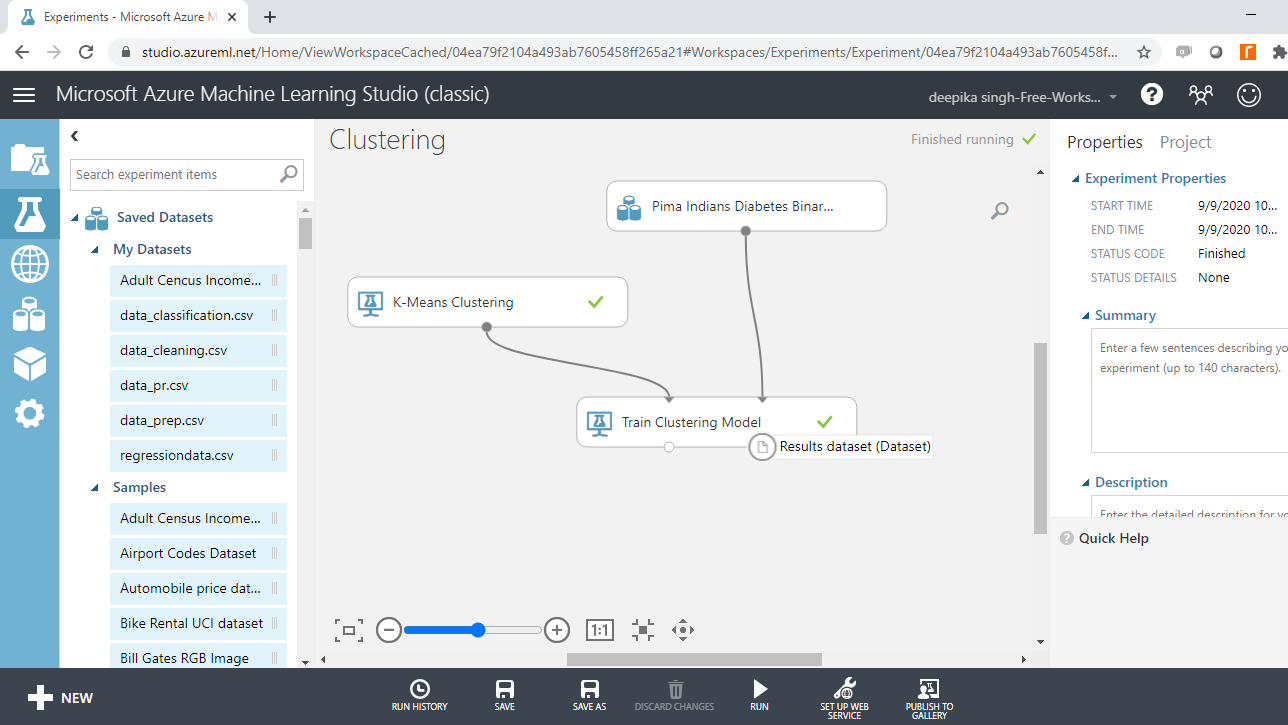
要探索结果,请搜索并将“转换为 CSV”模块拖到工作区中,如下所示。
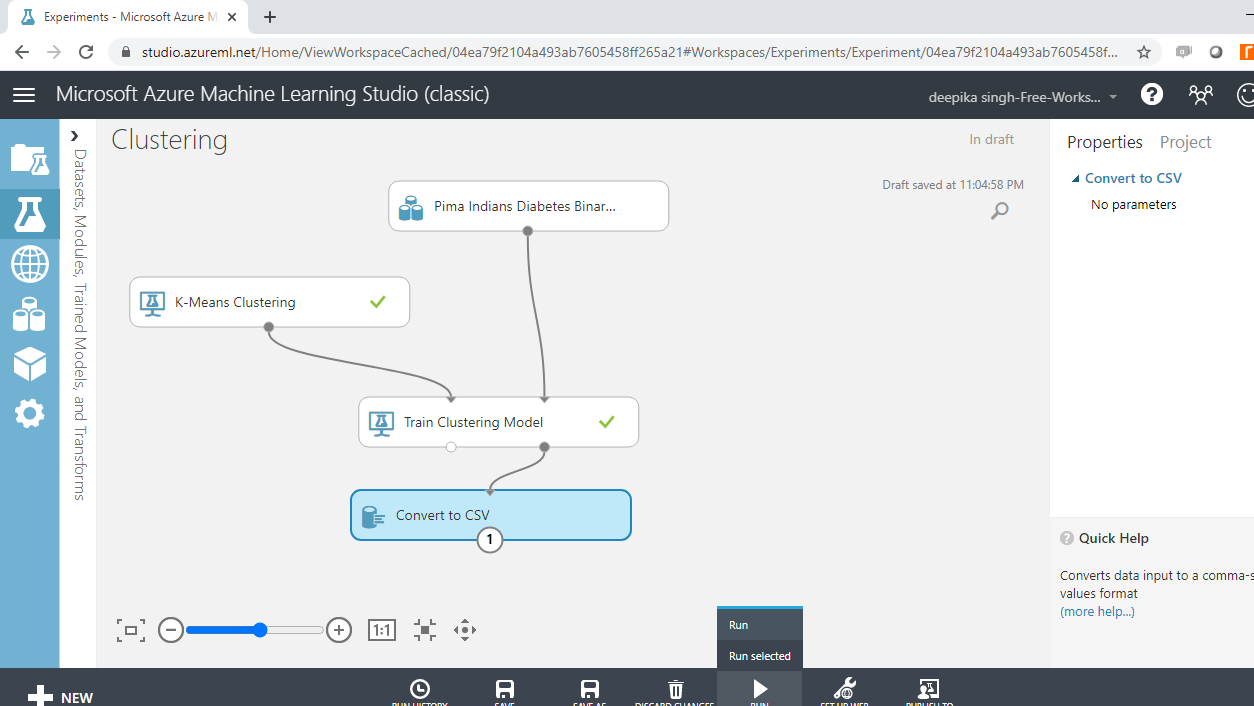
运行实验。接下来,右键单击并选择下载选项。
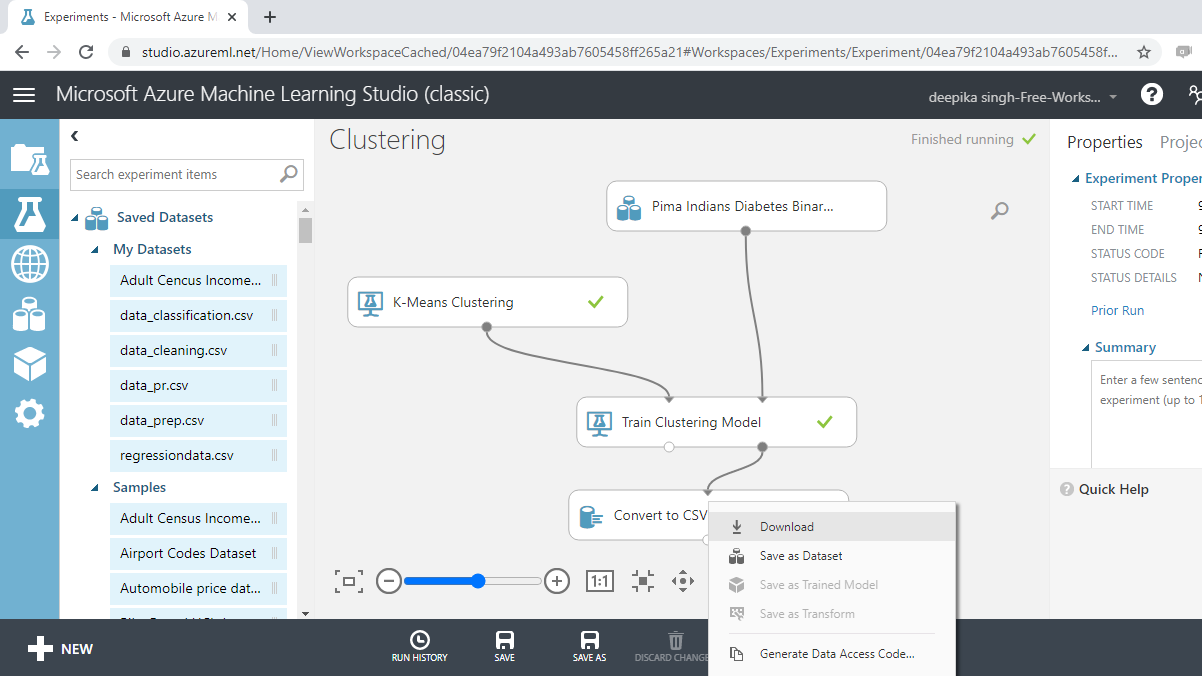
上述操作将下载您可以在左下角看到的数据集,以蓝色框突出显示,名为“Clustering - 50615”。
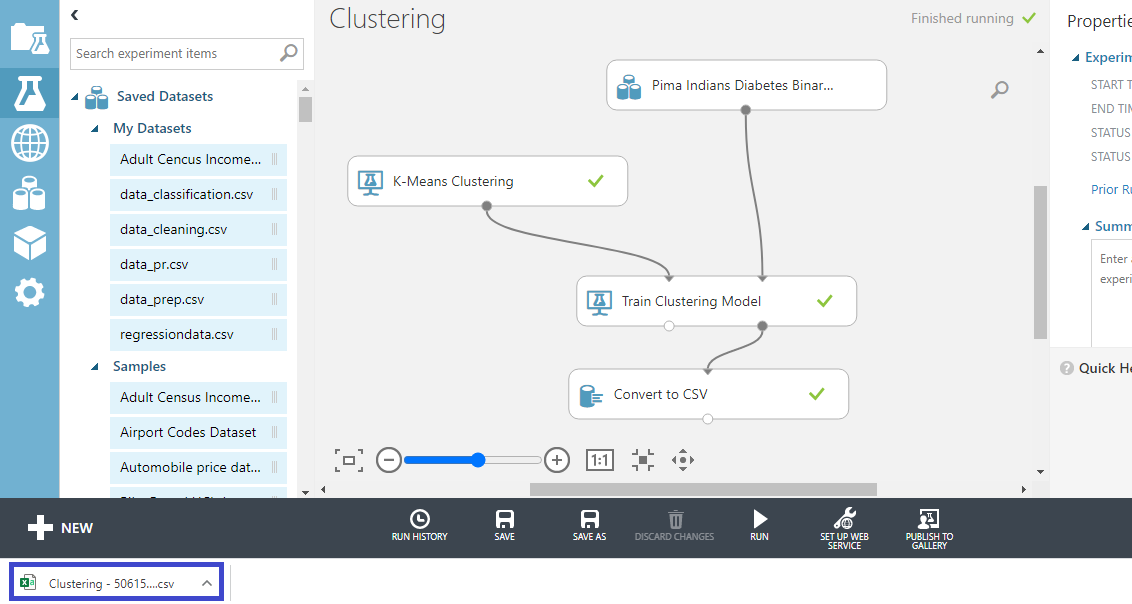
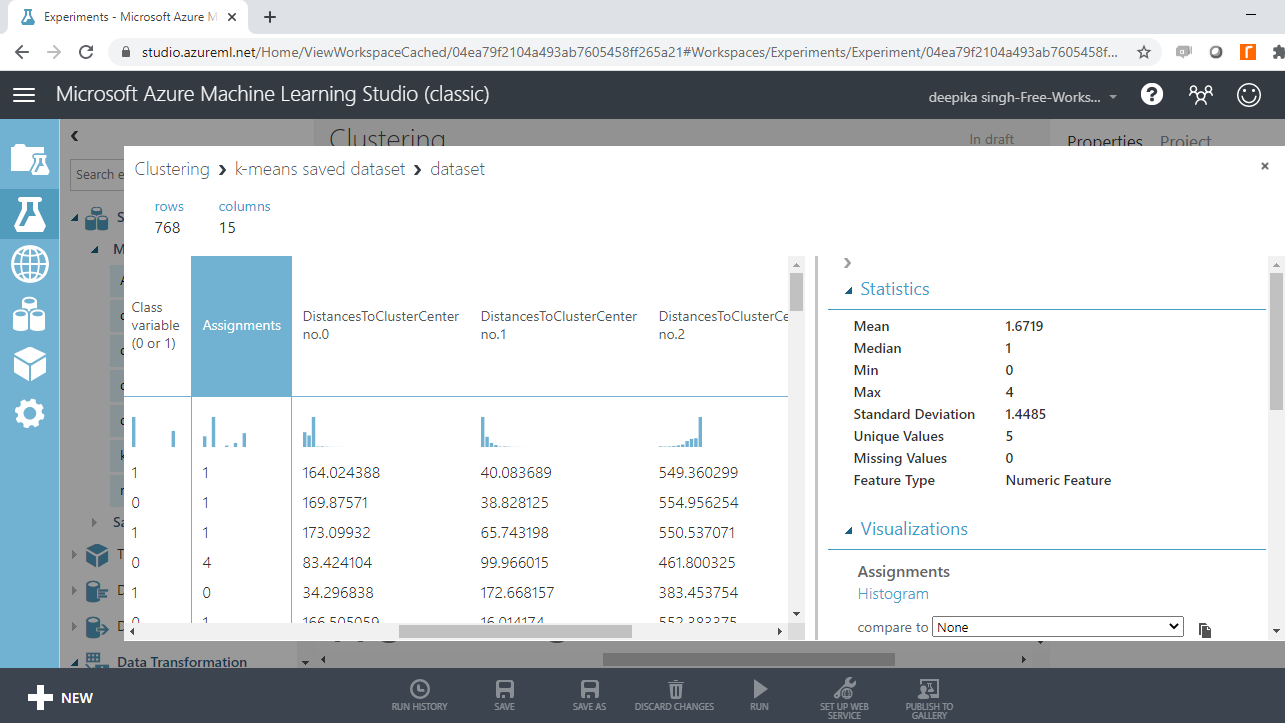
打开文件,您将看到以下输出。由于聚类,原始数据集中添加了新变量。分配变量告诉我们该观察结果被分配到哪个聚类。共有五个聚类,从零到四。还创建了其他变量,提供有关每个特定聚类的距离的信息。如下所示。
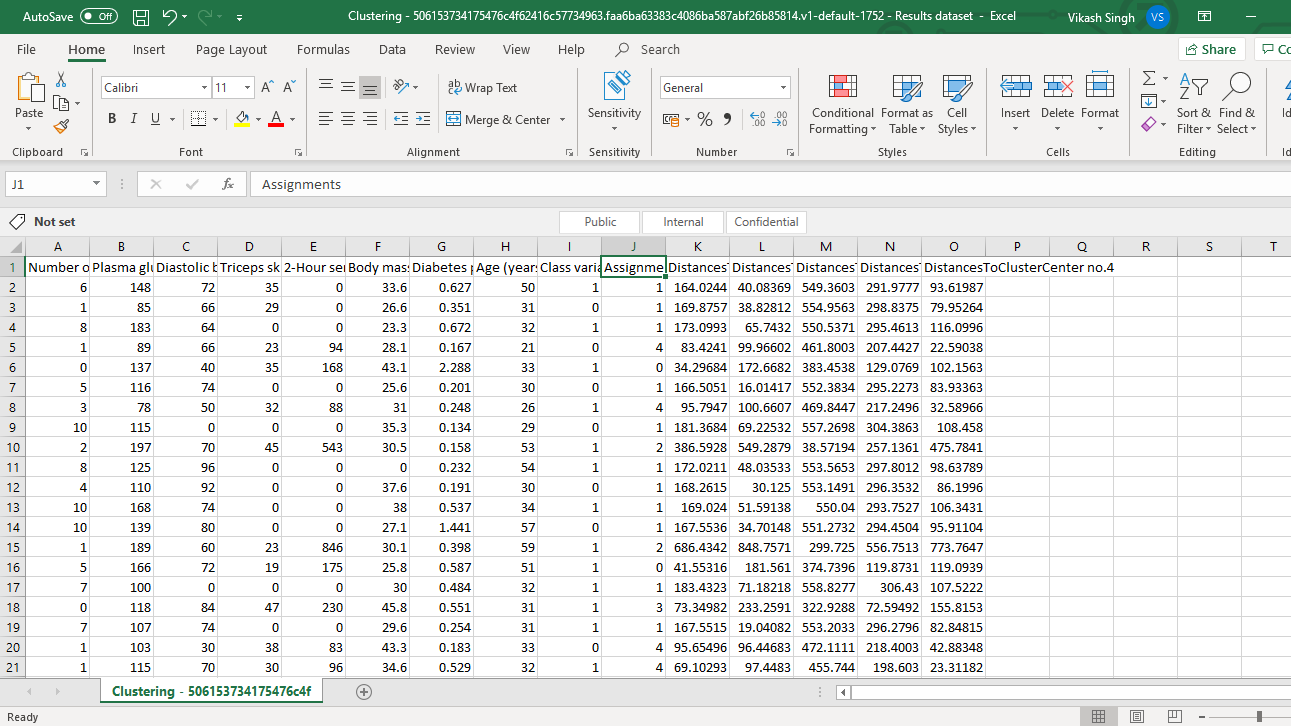
上述步骤需要将数据下载到您的机器上。还有另一种方法来了解集群结果。您可以在 Azure 工作室本身中将结果保存为数据集。为此,右键单击转换为 CSV模块的输出端口,然后选择另存为数据集。
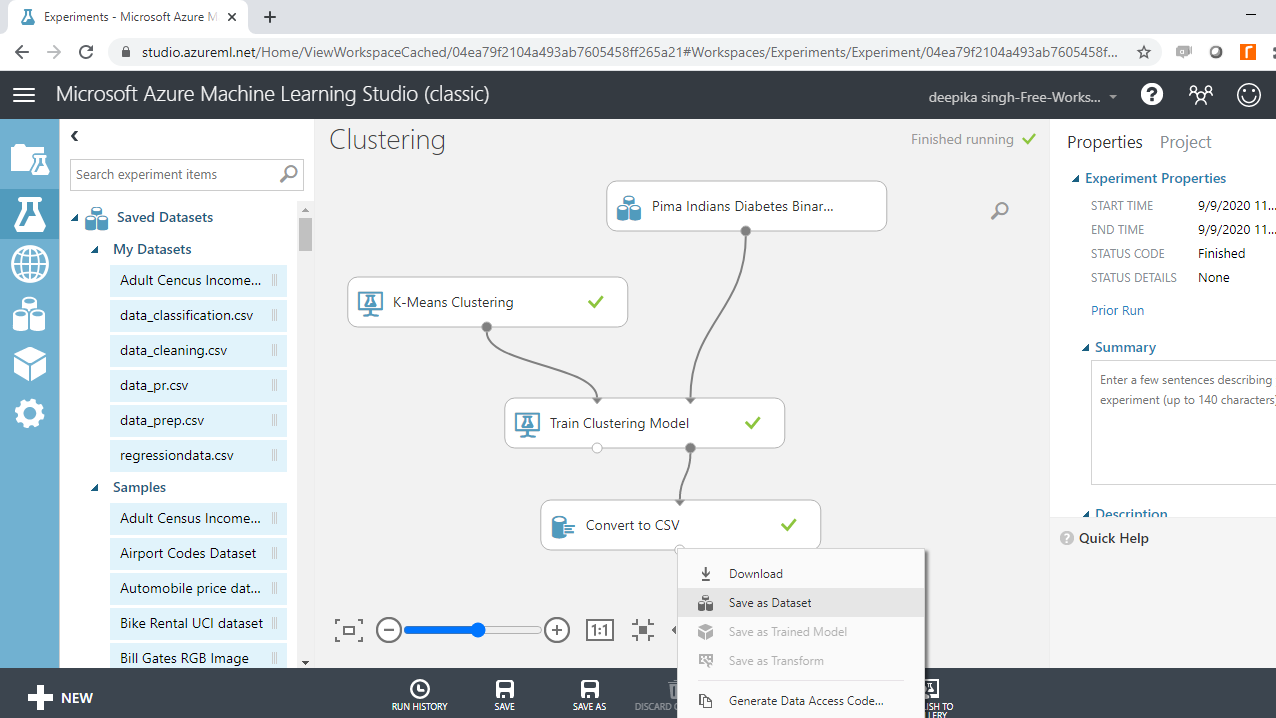
上述步骤将打开一个新窗口,您可以在其中输入名称。文件名为“k-means saved dataset”。
数据将保存在“已保存的数据集”下的“我的数据集”文件夹中。
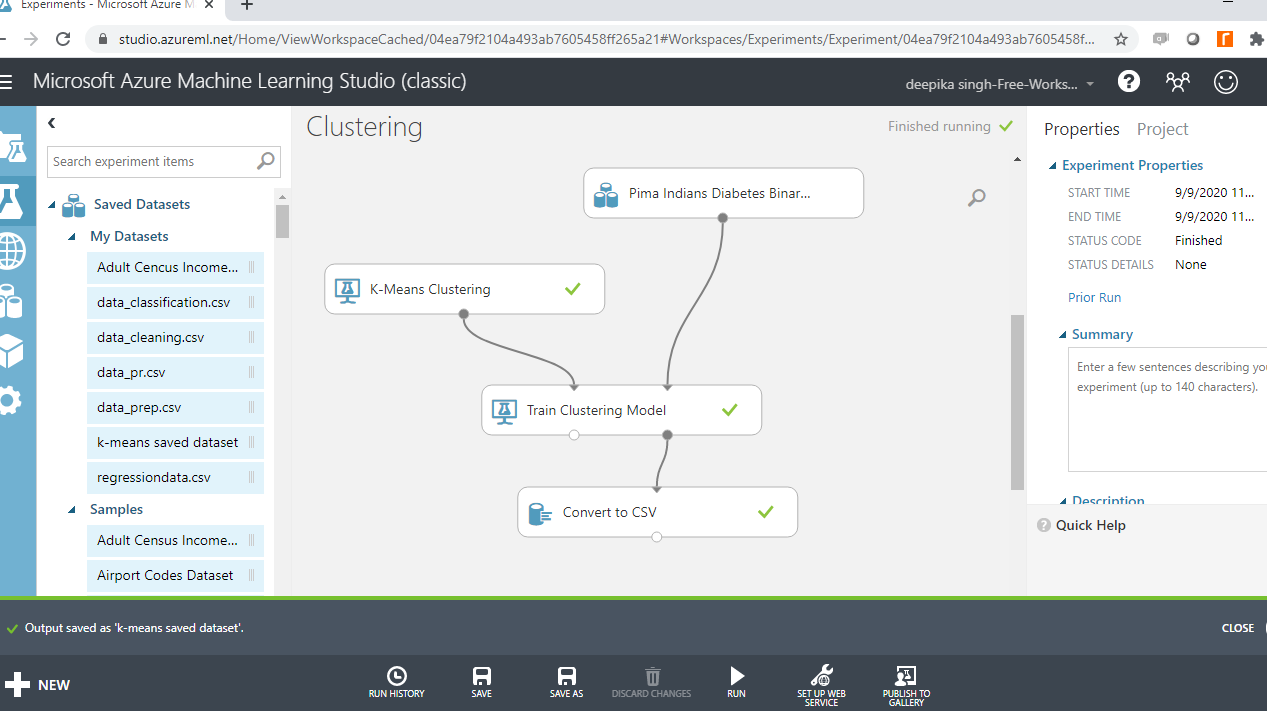
该数据集的可视化和操作非常简单。例如,您可以将数据集拖到工作区中,然后右键单击以进行可视化。
输出显示结果数据集有附加列。单击Assignments变量可查看摘要统计信息。Assignments变量采用五个唯一值,代表创建的五个集群。
结论
在许多数据科学项目中,您不会有目标变量。相反,您将拥有一个具有特征的数据集,并且您将期望从中产生有价值的见解。经典的例子是谷歌的搜索引擎、优步的出租车算法、Netflix 的推荐引擎和亚马逊的购物篮分析。所有这些强大的机器学习解决方案不仅依赖于监督学习,还依赖于无监督机器学习算法。
要了解有关使用 Azure 机器学习工作室进行数据科学和机器学习的更多信息,请参阅以下指南:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~