
Hadoop YARN 简介
介绍
在大数据处理中,与分布式处理一样,迫切需要管理计算集群内的资源。管理资源的组件必须高效且独立地完成管理。在Hadoop的具体情况下,第一个版本将资源管理任务分配给Map Reduce。在此设置中,有一个组件Job Tracker,它将任务分配给以控制器-操作员方式调用的下属进程。这些任务主要是map和Reduce任务。由于单个控制器限制了可以添加到计算集群的节点数量,因此该架构出现了瓶颈。
这导致了Hadoop YARN的诞生,该组件的主要目的是从 MapReduce 中接管资源管理任务,使 MapReduce 专注于处理,并将资源管理分为作业调度、资源协商和分配。与 MapReduce 分离为 Hadoop 带来了巨大优势,因为它现在可以运行 MapReduce 范式之外的作业。这些作业包括图形处理、批处理、流处理和交互式处理。
本指南探讨了 YARN(又一个资源协商器)、其架构以及它如何实现其目的。本指南假设您熟悉一般的 Hadoop 架构并对其组件有基本的了解。您可以在此处找到 Hadoop 的入门指南。
分布式系统中的资源利用
在分布式系统中,资源(主要是计算能力和存储)通常位于远程位置并可远程访问。这意味着需要一个中央主管来协调如何管理远程资源。每个节点还需要一个资源利用率对应组件,以便在资源管理和调度方面与资源利用率控制器进行通信。这种架构称为控制器-操作员架构。控制器组件是发出资源管理指令的中央组件,而辅助组件则是操作员节点。它们接收来自控制器的指令并提供反馈。只要控制器能够有效地处理所有操作员节点,这种架构就可以在分布式系统中实现可扩展性。
Hadoop YARN
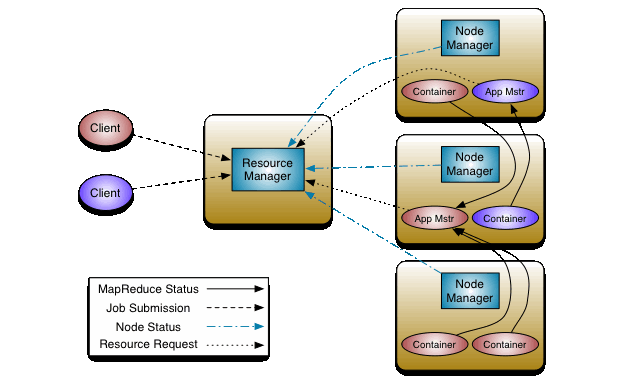
成分
资源管理器:控制器。管理计算集群内的资源分配
节点管理器:操作员。负责执行来自资源管理器的命令。它们位于 Hadoop 集群中的每个数据节点中。
应用程序主机:负责管理作业或任务,与资源管理器协商资源,并监视在其分配节点上运行的应用程序的健康状况。
容器:单个节点提供的 CPU、RAM 和存储等资源的集合。
结论
现在您应该了解 Hadoop 分布式系统中资源协商器的内部工作原理,并更好地理解如何管理分布式架构中的多个节点。
从这里,您可以进一步探索除 Hadoop 之外的分布式系统中的资源协商、冲突解决和容错研究。为了巩固本指南中获取的知识,您可以进一步探索生态系统中的其他技术,例如Apache Ambari、Hive和Pig等。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~