
Azure ML Studio 中的 R 和 Python 脚本
介绍
Azure 机器学习工作室的一项重要功能是可以使用 Azure 工作区中提供的模块编写 R 或 Python 脚本。这使数据科学家能够在工作区中利用他们对 R 和 Python 的知识。在本指南中,您将了解如何使用这些模块在 Azure 机器学习工作室中运行 R 和 Python 代码。
数据
在本指南中,您将使用 600 个观测值和 4 个变量的虚构数据,如下所述。
受抚养人:申请人的受抚养人人数。
Credit_score:申请人的信用评分是良好(“1”)还是不良(“0”)。
年龄:申请人的年龄。
审批状态:贷款申请是否已获批准(“1”)或未获批准(“0”)。这是因变量。
首先加载数据。
加载数据
登录 Azure 机器学习工作室帐户后,单击左侧栏上列出的EXPERIMENTS选项,然后单击NEW按钮。接下来,单击空白实验,将显示新的工作区。将工作区命名为Execute Scripts。
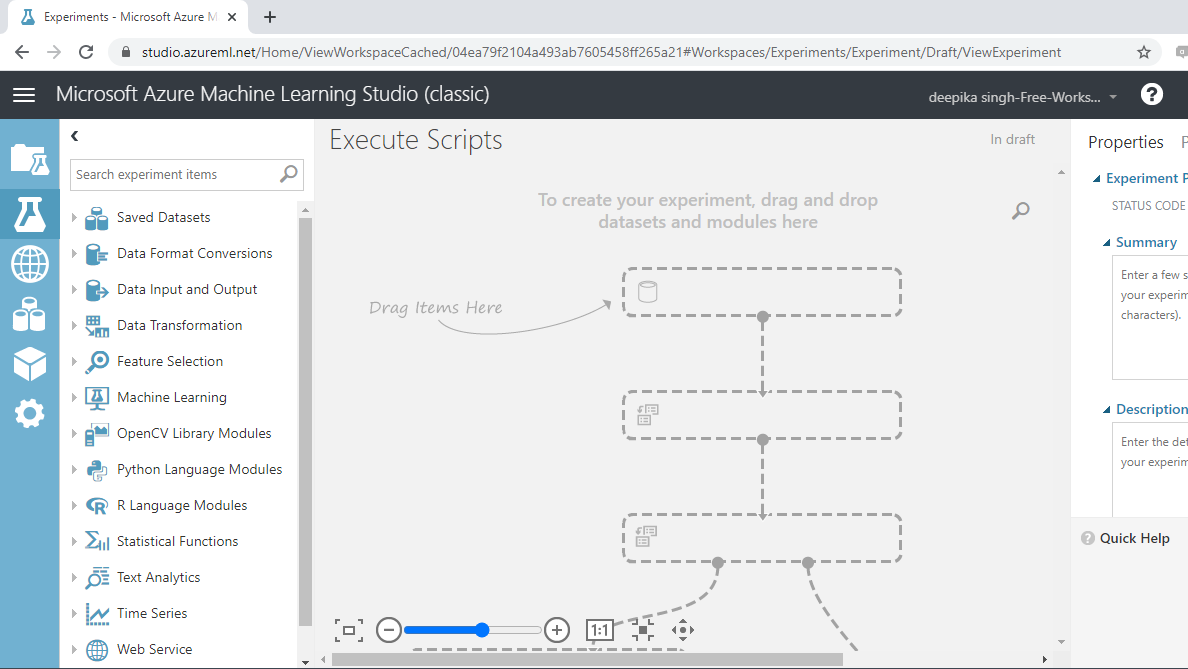
接下来,您将把数据加载到工作区中。单击NEW,然后选择DATASET选项。
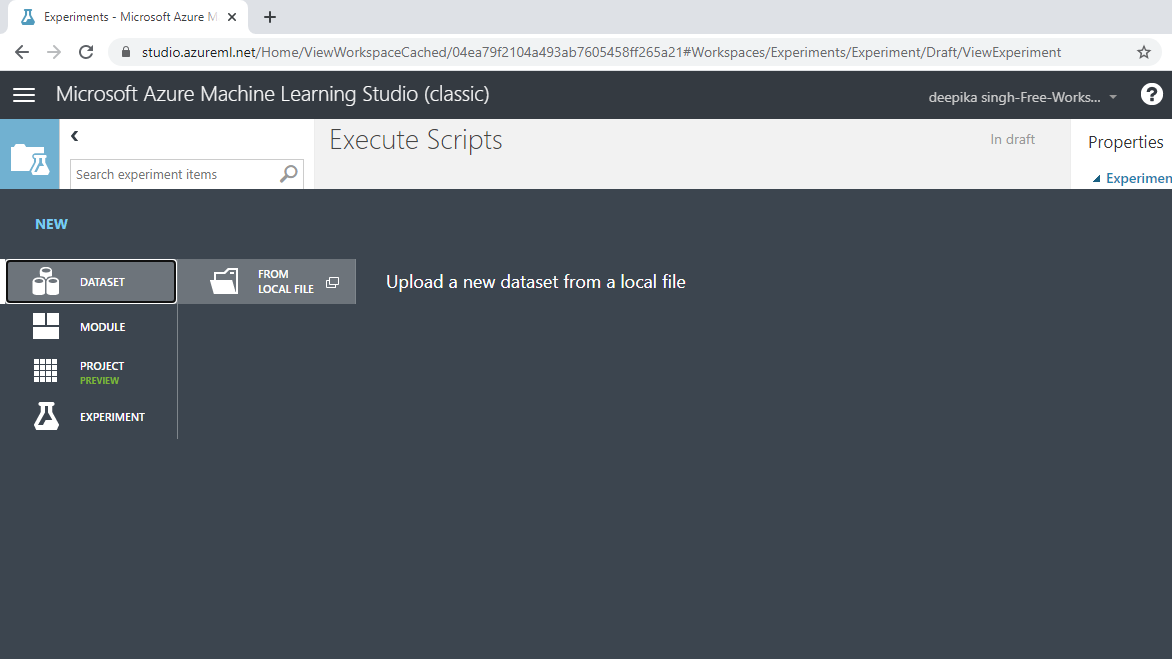
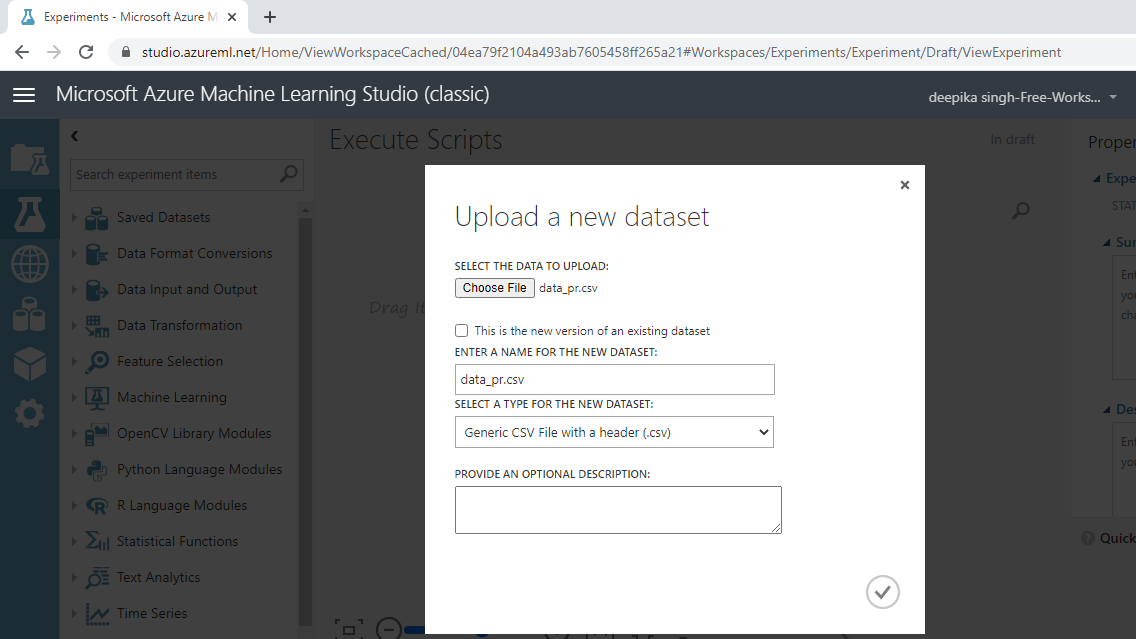
上面的选择将打开如下所示的窗口,可用于从本地系统上传数据集。
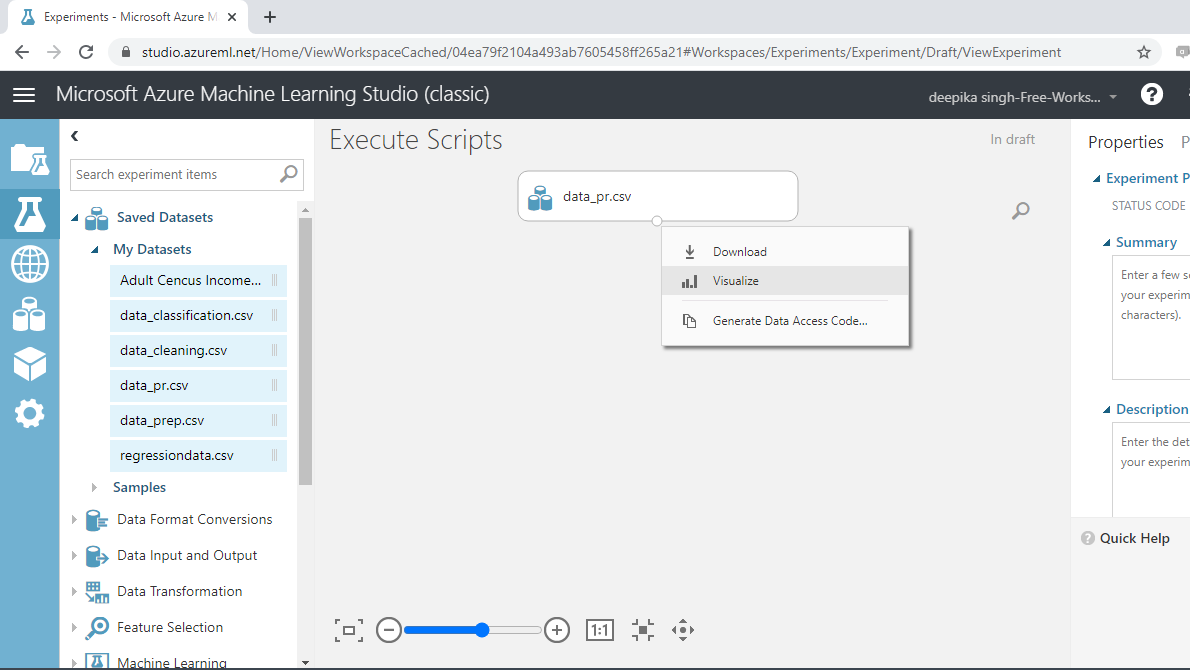
数据加载完成后,您可以在“已保存的数据集”选项中看到它。文件名为data_pr.csv。
探索数据
首先,将数据从“已保存的数据集”列表拖到工作区。接下来,右键单击并选择“可视化”选项,如下所示。
选择不同的变量来检查基本统计数据。例如,下图显示了变量Age的详细信息。
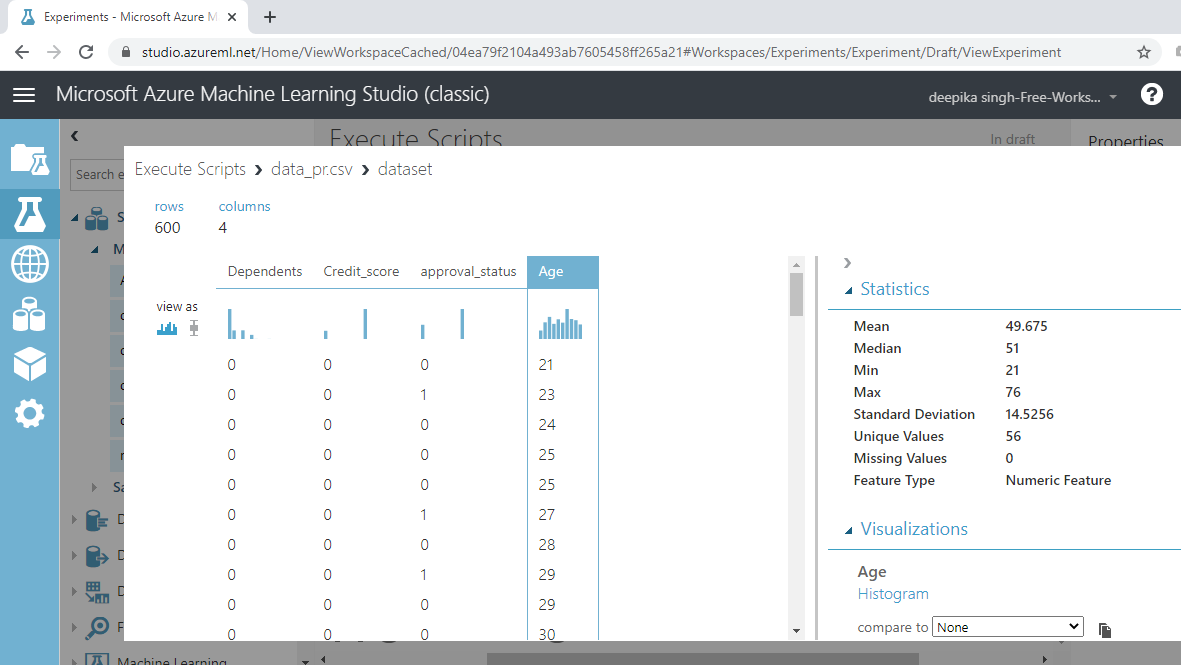
您将注意到变量的摘要统计信息。接下来,查看变量approval_status。
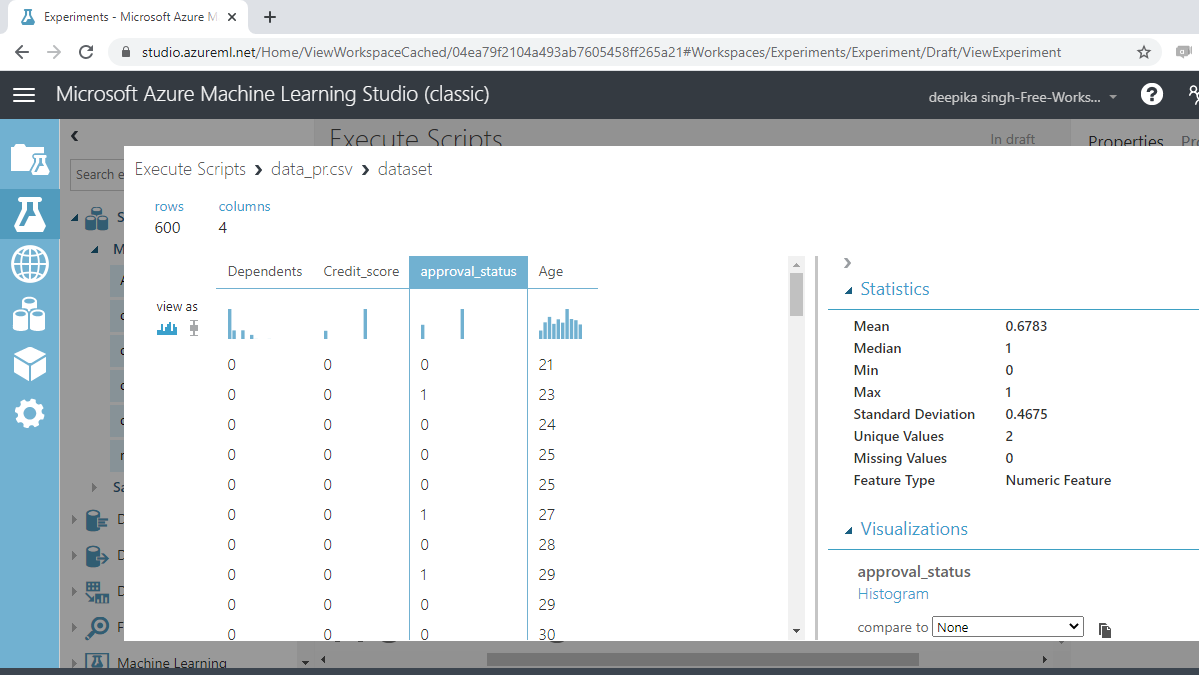
这是一个以数字表示的分类变量。您将使用执行 R 脚本模块更改数据类型。
执行 R 脚本
执行 R 脚本模块可用于在机器学习实验中执行 R 代码。您可以使用 R 代码执行数据准备、数据探索和机器学习等任务。您将使用 R 脚本转换Dependents、Credit_score和approved_status变量的数据类型。
首先,搜索并添加执行 R 脚本模块到您的实验中。接下来,将数据连接到执行 R 脚本模块的第一个输入端口(最左边)。单击模块,然后在**属性**窗格下。您将看到编写 R 脚本的选项。输入如下所示的代码。
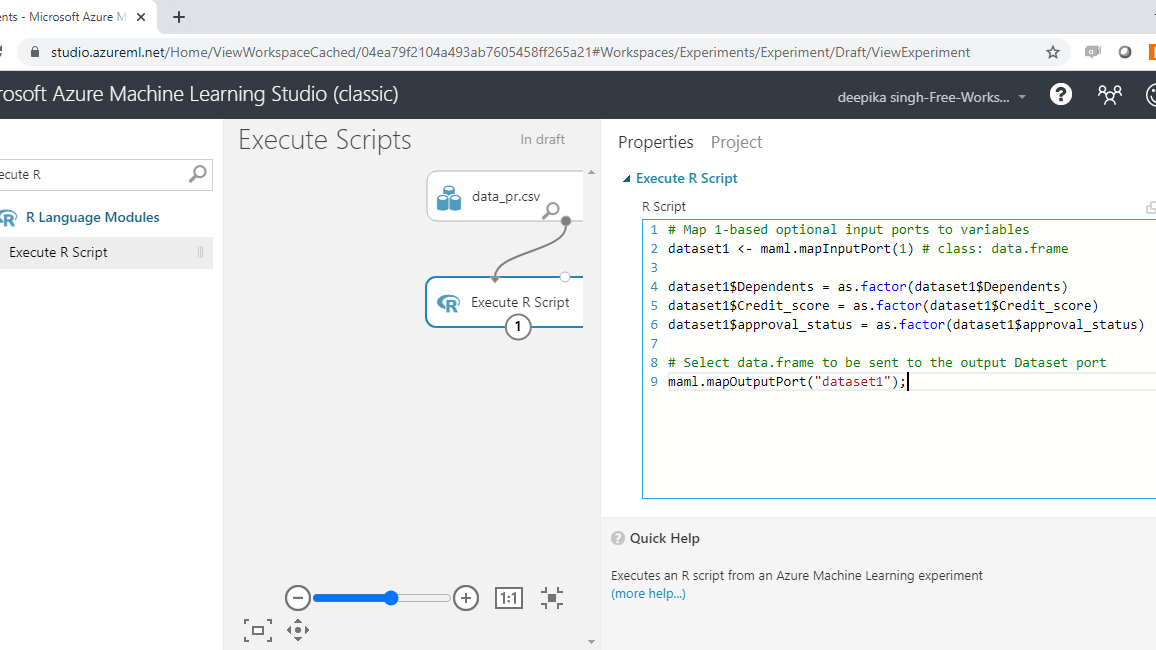
您也可以从下面复制代码。
dataset1 <- mam1.mapInputPort(1)
dataset1$Dependents = as.factor(dataset1$Dependents)
dataset1$Credit_score = as.factor(dataset1$Credit_score)
dataset1$approval_status = as.factor(dataset1$approval_status)
mam1.mapOutputPort("dataset1");
在上面的代码中,第一行创建一个数据框dataset1 ,它使用函数mam1.mapInputPort()映射到第一个输入端口。第二行到第四行代码使用as.factor()函数将数值变量转换为分类变量。最后,mam1.mapOutputPort(“dataset1”)函数将生成的输出保存在执行 R 脚本模块最左边的第一个输出端口中。
您可以将随机种子设置为 11,并将其他选项保留为默认设置。
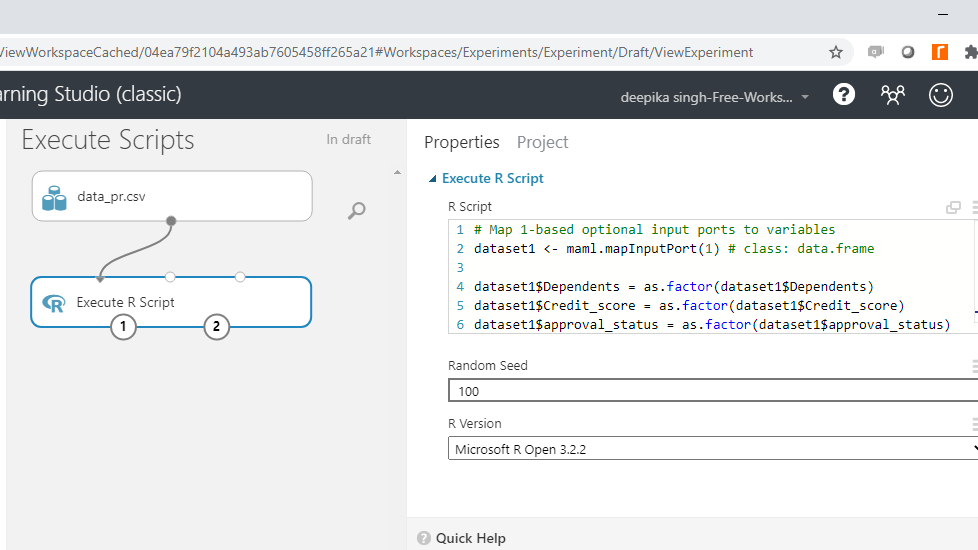
运行实验。成功完成后,您可以在模块中看到绿色勾号。
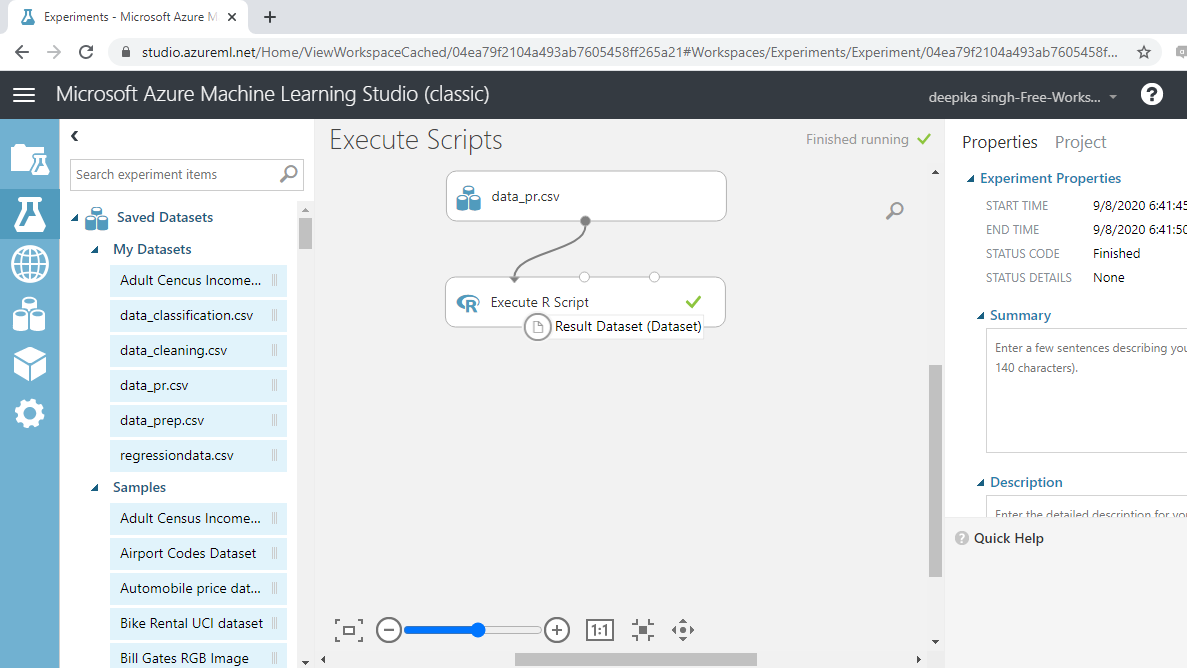
右键单击并选择“可视化”以再次查看数据。
如果您单击approval_status变量,您将看到特征类型现在是分类的。
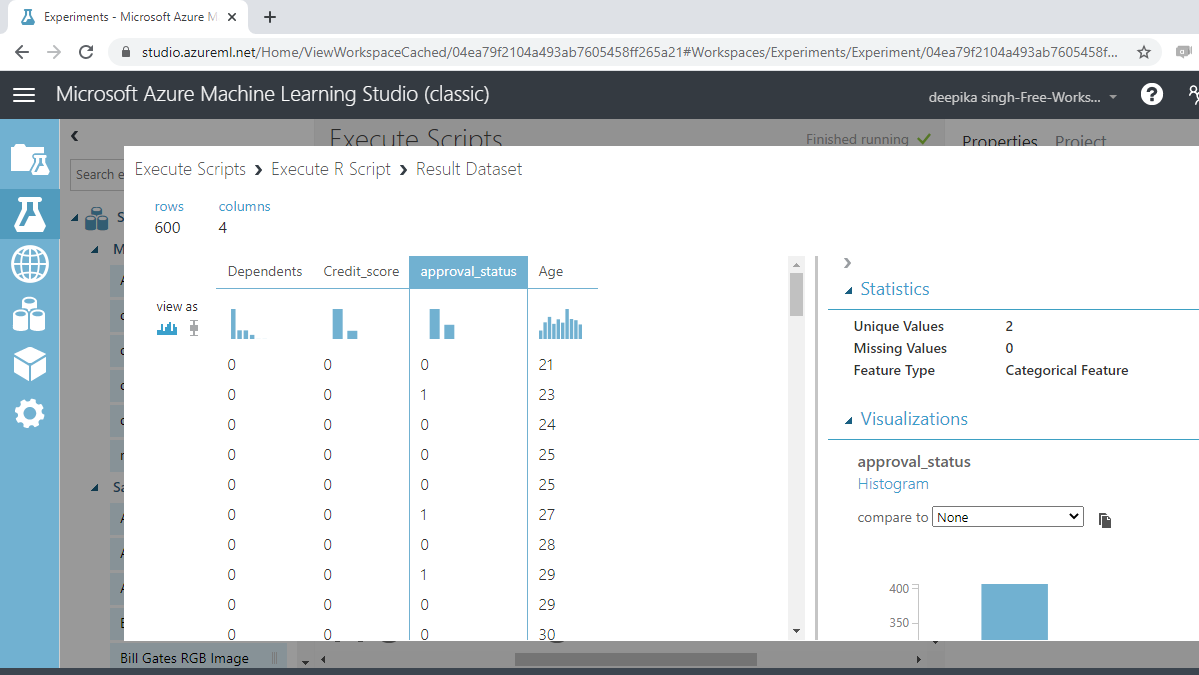
您已使用 R 脚本将变量Dependents、Credit_score和approved_status转换为分类变量。
执行 Python 脚本
执行 Python 脚本模块可用于在 Azure 机器学习工作室实验中调用和运行 Python 代码。
您已使用执行 R 脚本模块将变量转换为分类变量。唯一的数字变量是Age。在构建机器学习模型时,有时您可能希望通过称为分箱的过程将数字特征转换为分类特征。一种这样的算法是朴素贝叶斯算法,它要求所有特征都是分类的。
您将使用 Python 脚本对Age变量执行分箱。首先,搜索并将执行 Python 脚本模块添加到您的实验中。

接下来,将数据连接到执行 Python 脚本模块的第一个输入端口(最左边),如下所示。
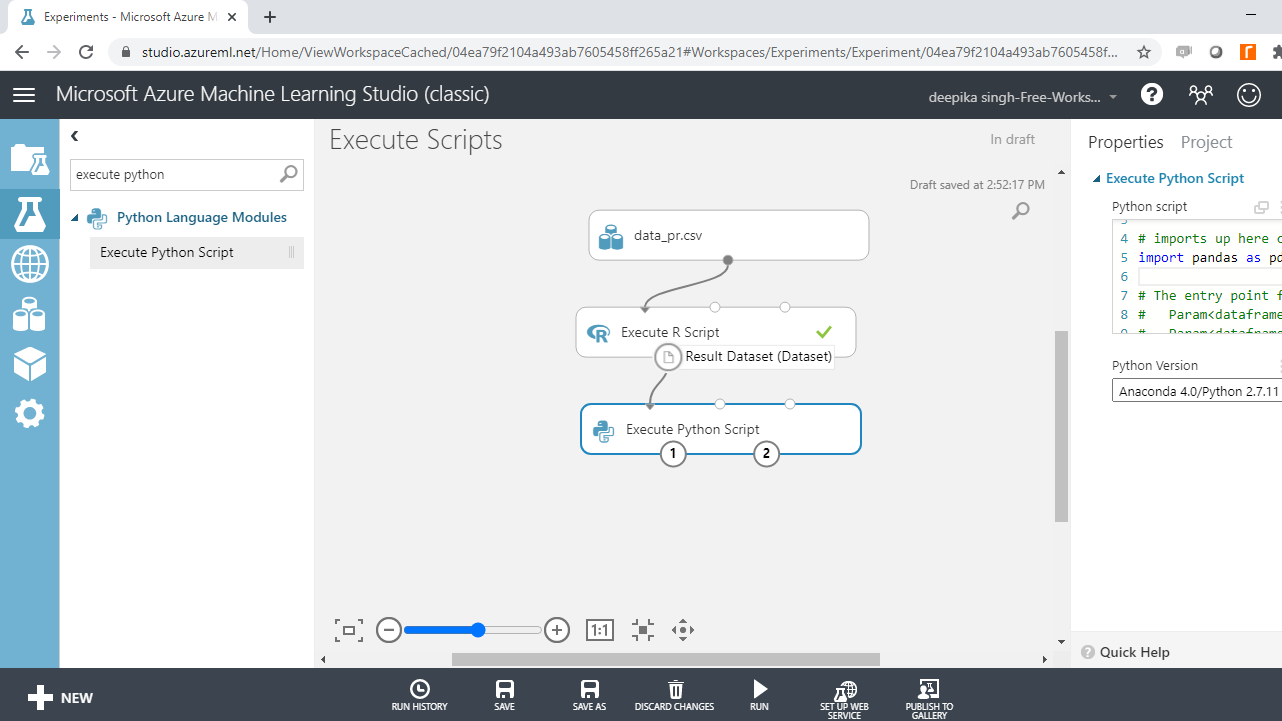
单击模块,在“属性”窗格下,您将看到编写脚本的选项。输入如下所示的代码。
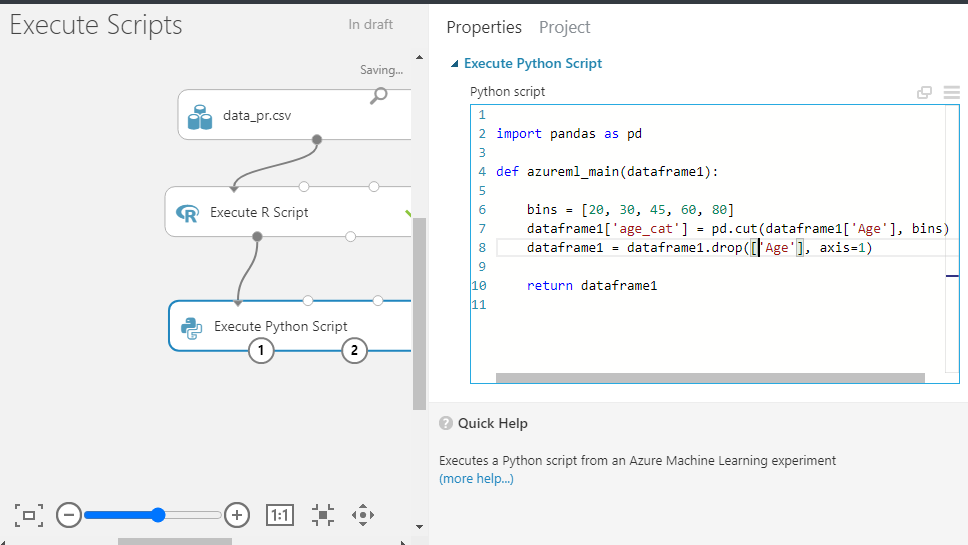
您也可以从下面复制代码。
import pandas as pd
def azureml_main(dataframe1):
bins = [20,30,45,60,80]
dataframe1['age_cat'] = pd.cut(dataframe1['Age'],bins)
dataframe1 = dataframe1.drop(['Age'],axis=1)
return dataframe1
此代码的第一行导入了pandas库。第二行遵循强制性惯例,包括名为azureml_main()的函数作为此模块的入口点。
第二行创建函数,第三行创建 bin 范围。第四行使用pd.cut函数创建age_cat变量。第五行从数据集中删除Age变量。最后,第六行返回结果数据框。
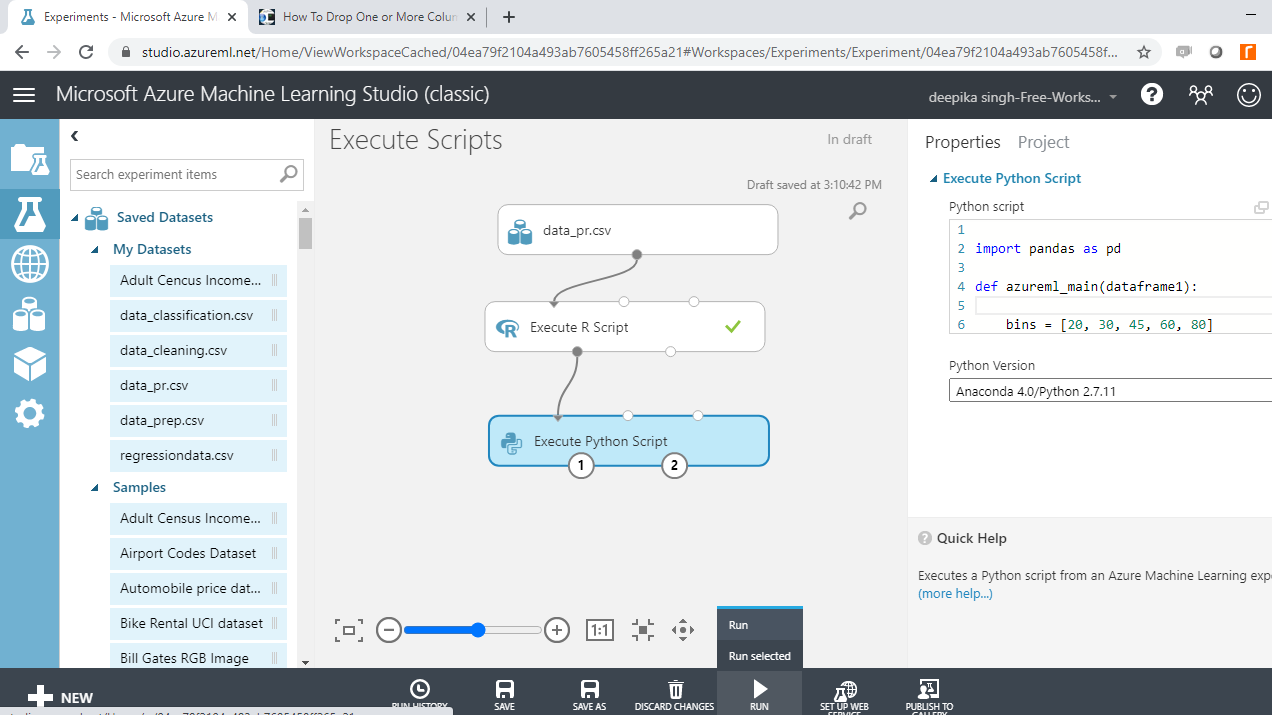
单击“运行”并选择“运行所选”选项。
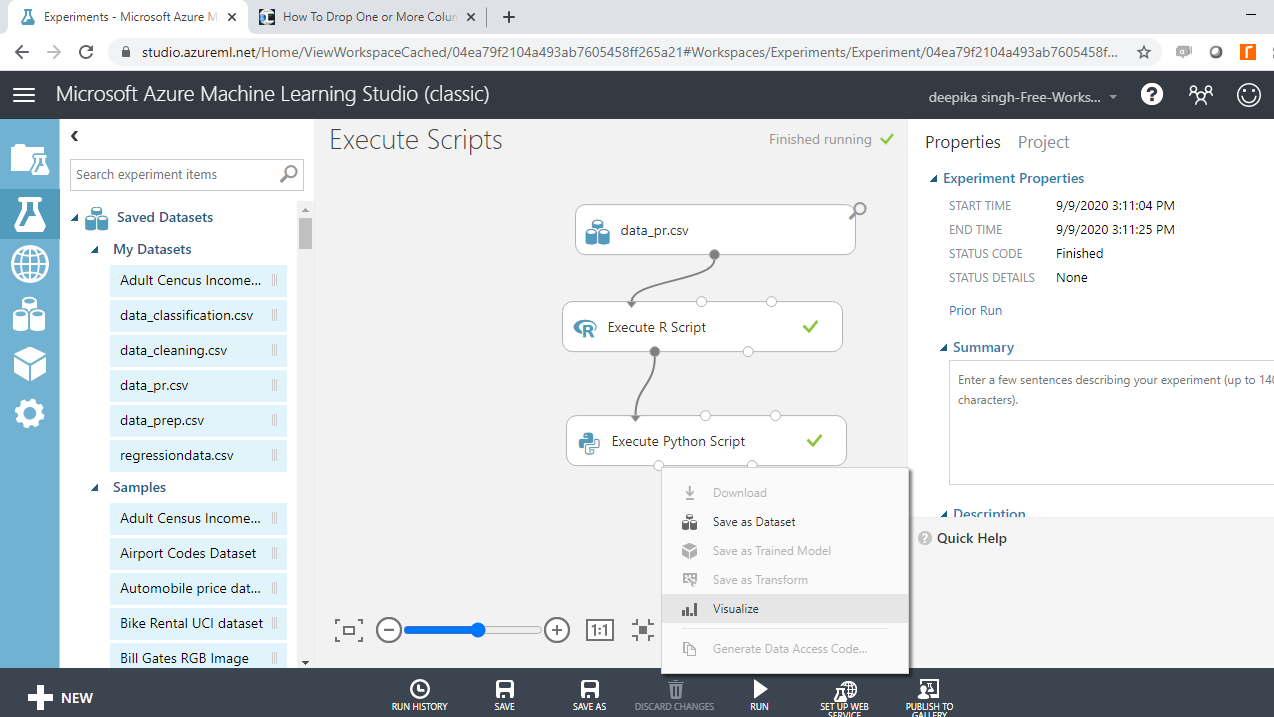
模块运行完成后,右键单击并选择“可视化”。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~