
了解 Hadoop 的分布式文件系统
介绍
大数据应用的资源需求通常非常大。由于这些数据也很有价值,因此将数据存储在副本中很重要,以降低因硬件故障而导致数据丢失的风险。大型数据密集型应用对可扩展性和可靠性的需求催生了分布式存储和处理架构。
Hadoop 分布式文件系统 (HDFS) 是Google 文件系统的后代,它是为了解决大规模大数据处理问题而开发的。HDFS 只是一个分布式文件系统。这意味着单个大型数据集可以存储在计算集群中的几个不同的存储节点中。HDFS 是 Hadoop 能够以分布式方式为大型数据集的存储提供可扩展性和可靠性的方式。
分布式方法的动机
为什么公司会选择分布式架构而不是通常的单节点架构?
容错性:由于副本的存在,分布式架构对故障的免疫力更强。
可扩展性:HDFS 允许向集群添加更多节点。它不受限制。这使企业能够根据需求轻松扩展。
访问速度:与传统的关系数据库相比,分布式架构可以快速从存储中检索数据。
成本效益:在大数据规模下,分布式方法在存储和检索计算方面更便宜,因为读取和写入关系数据库所需的额外处理成本要高得多。
HDFS 和 Hadoop 具有诸多优势,最适合处理海量数据。如果您的用例数据量相对较小且易于管理,那么 HDFS 可能不是理想之选。
HDFS 架构
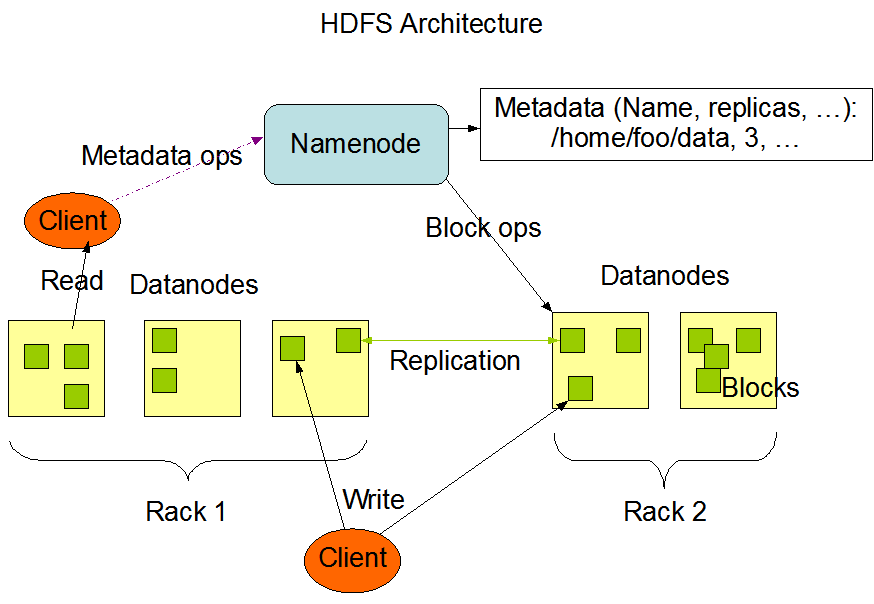
组件包括:
Namenode:主节点。它管理系统上的文件的访问,也管理系统的命名空间。
DataNode:从属节点。它执行文件系统的读/写操作以及创建、删除和复制等块操作。
Block : 存储的单位,一个文件被分成多个块,不同的块按照namenode的指令存储在不同的datanode上。
可以将多个数据节点分组为一个单元,称为机架。机架设计取决于大数据架构师及其想要实现的目标。典型的架构可能有一个主机架和一些复制机架,以便在发生故障时提供冗余。
基本使用命令
要使用 Hadoop 文件系统,您需要具备一些 Linux 或命令行使用方面的背景知识,因为大多数命令与 Linux 中的命令类似。
要启动 HDFS,假设你的机器上安装了 Hadoop,请运行以下命令
start-dfs.sh
一般模式是使用基本的 Linux 文件系统命令,但前面加上命令hadoop fs,以便它们在 HDFS 而不是本地文件系统上运行。
要在 HDFS 中创建新目录,请使用命令
hadoop fs -mkdir <directory_name>
要将文件从主机复制到 HDFS,请使用命令
hadoop fs -put ~/path/to/localfile /path/to/hadoop/directory
put的反向操作是get,它将文件从 HDFS 复制回主机文件系统。
hadoop fs -get /hadoop/path/to/file ~/path/to/local/storage
HDFS 中还提供更多 Linux 文件系统命令,例如chown、rm、mv、cp、ls等。
结论
现在您应该对 Hadoop 的一项基本技术有了清晰的了解。随着技术的进步,Hadoop 和 HDFS 面临着来自Google Big Query、Cloudera等替代方案的竞争。对于任何希望成为大数据工程师或大数据架构师的人来说,进一步了解 Hadoop 及其技术至关重要。
为了进一步理解本指南,请详细了解 Hadoop 生态系统中的其他基本组件。这些组件包括但不限于用于管理 Hadoop 集群的Apache Ambari 、用于数据查询和分析的Hive 、用于分布式处理的MapReduce 、用于使用类似 SQL 的语言编写数据转换的Pig以及用于资源管理和调度的YARN 。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~