
使用 Azure ML Studio 进行数据预处理
介绍
数据预处理是构建强大而强大的机器学习模型的重要数据科学活动。它有助于提高建模的数据质量并提高模型性能。在本指南中,您将学习如何在 Azure ML Studio 中处理异常值、为数值变量创建箱体以及规范化数据。
数据
在本指南中,您将使用 600 个观测值和 6 个变量的虚构数据,如下所述。
受抚养人- 申请人的受抚养人人数。
收入——申请人的年收入(以美元计)。
Loan_amount-提交申请的贷款金额(以美元计)。
信用评分- 申请人的信用评分是良好(“满意”)还是不佳(“不满意”)。
年龄— 申请人的年龄。
审批状态- 贷款申请是否已获批准(“1”)或未获批准(“0”)。这是因变量。
首先加载数据。
加载数据
登录 Azure 机器学习工作室帐户后,您将看到以下窗口。
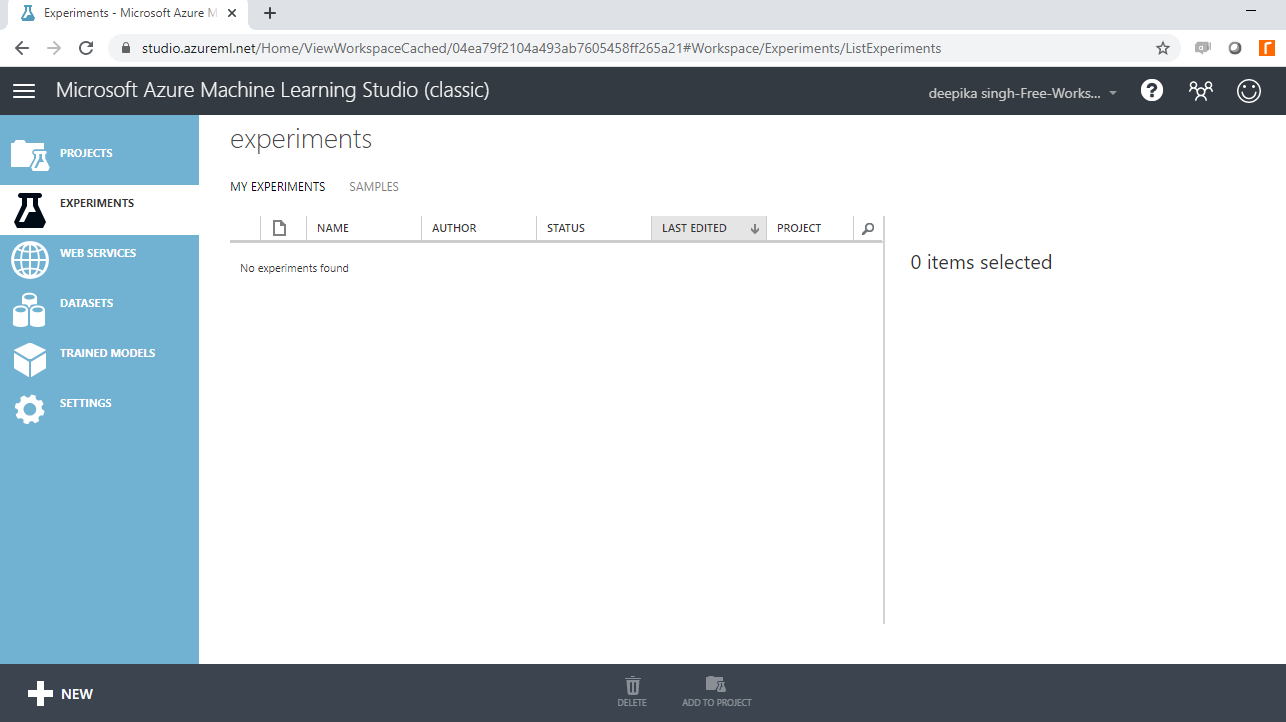
首先,单击左侧边栏列出的“实验”选项,然后单击“新建”按钮。接下来,单击空白实验,将显示以下屏幕。
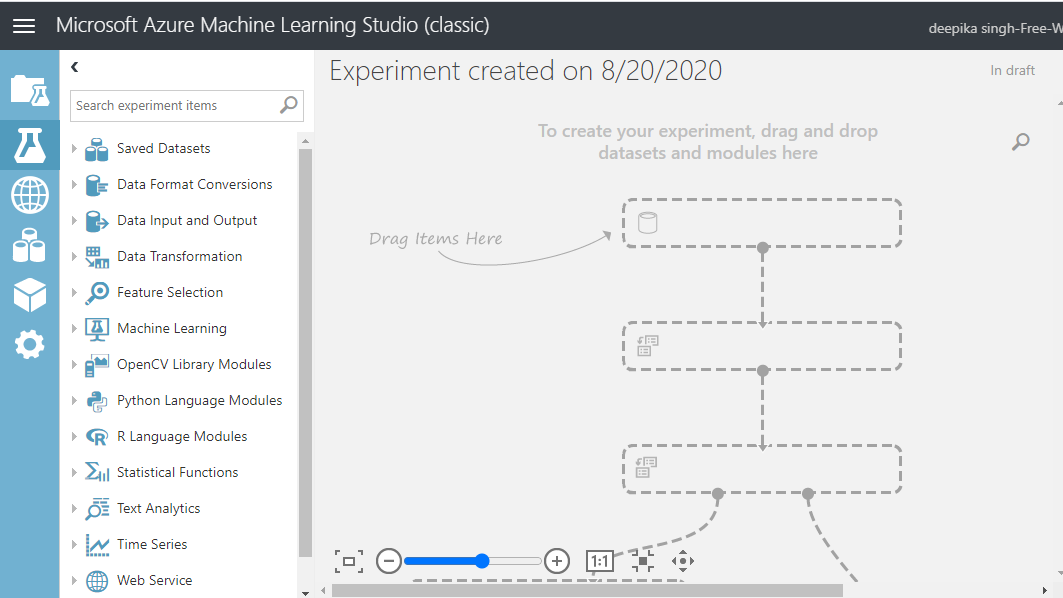
将工作区命名为Experiment。接下来,将数据加载到工作区中。单击NEW,然后选择下面显示的DATASET选项。
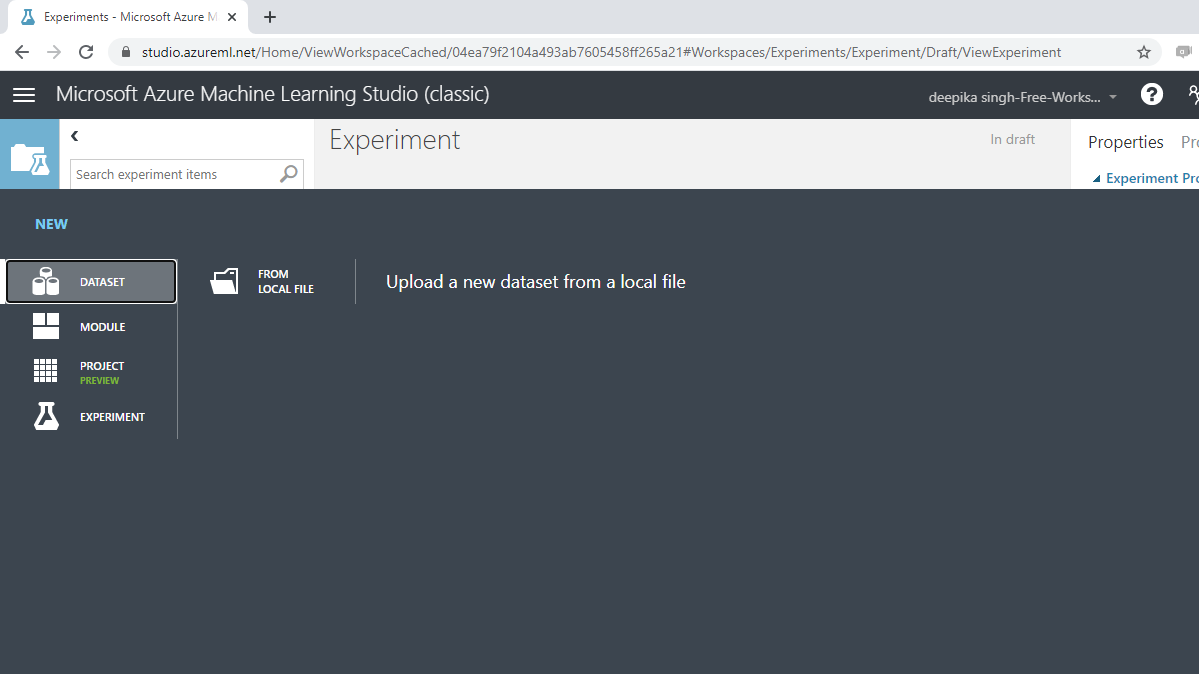
上面的选择将打开一个窗口,如下所示,可用于从本地系统上传数据集。
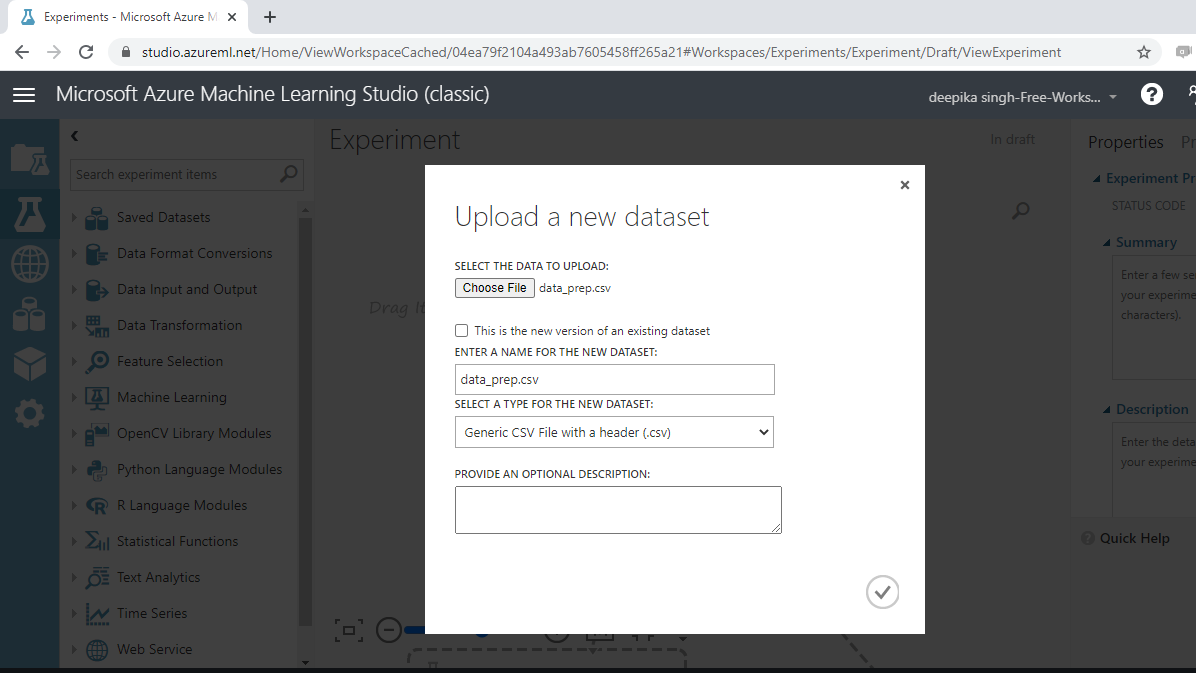
数据加载完成后,您可以在“已保存的数据集”选项中看到它。文件名为data_prep.csv。下一步是将其从“已保存的数据集”列表拖到工作区中。
探索数据
要探索数据,请右键单击并选择“可视化”选项,如下所示。
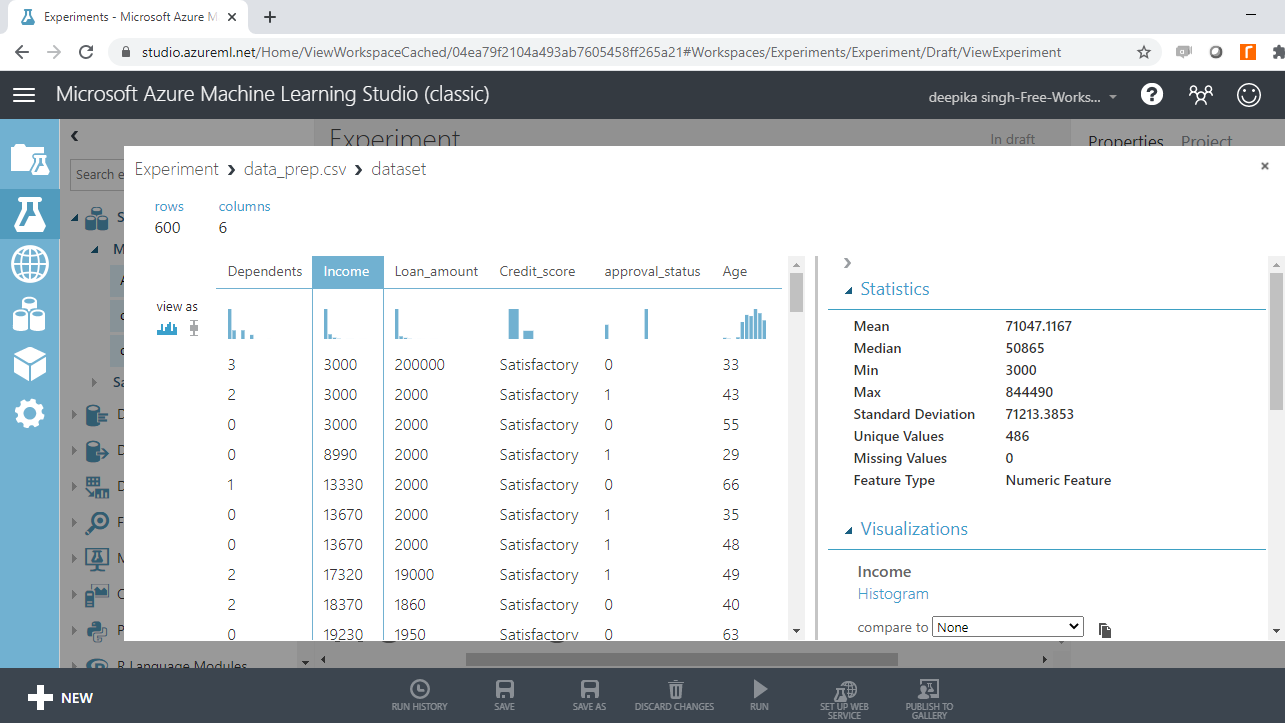
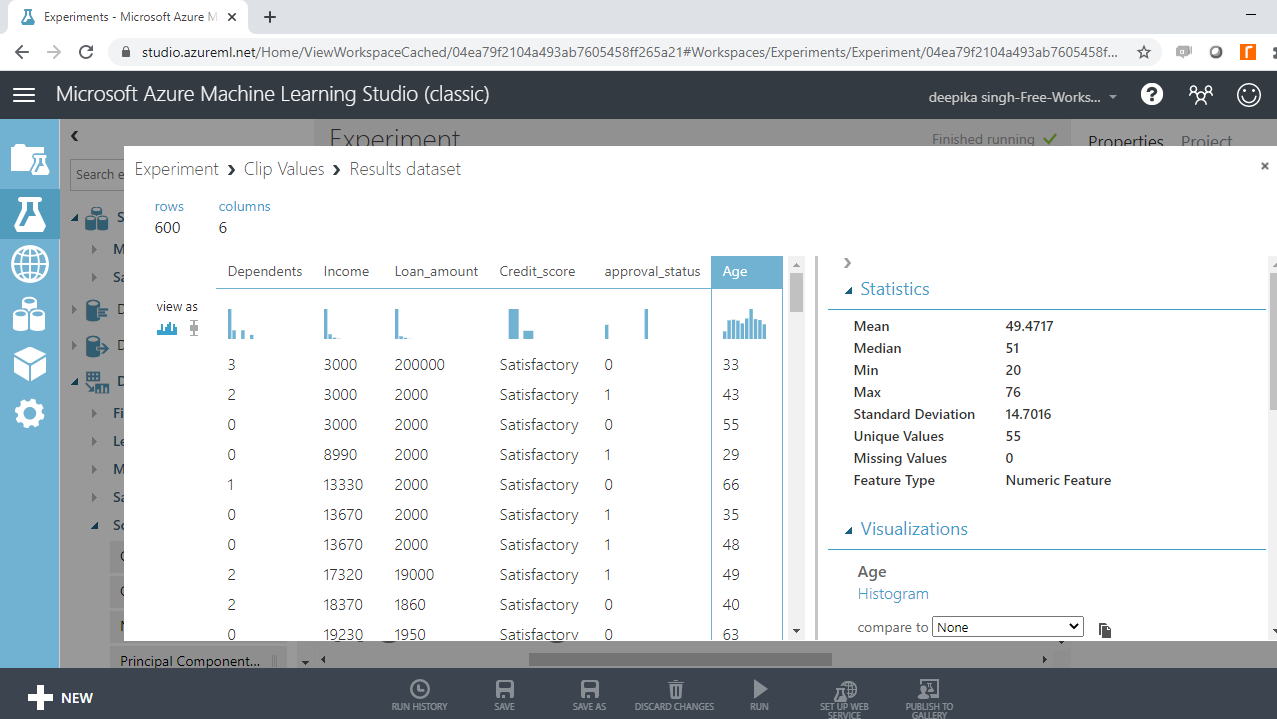
选择不同的变量来检查基本统计数据。例如,下图显示了变量Age的详细信息。
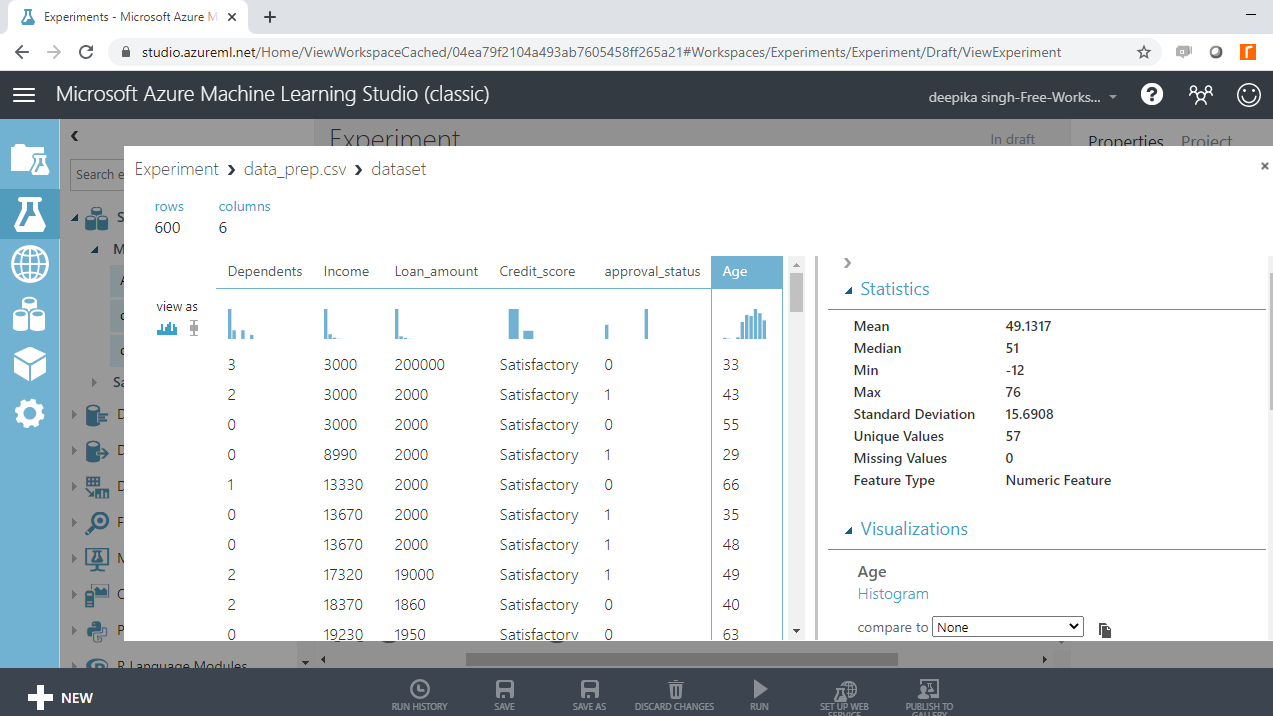
您会注意到年龄的最小值为 -12,这表明数据中存在不正确的记录。
接下来,查看变量Loan_amount和Income。
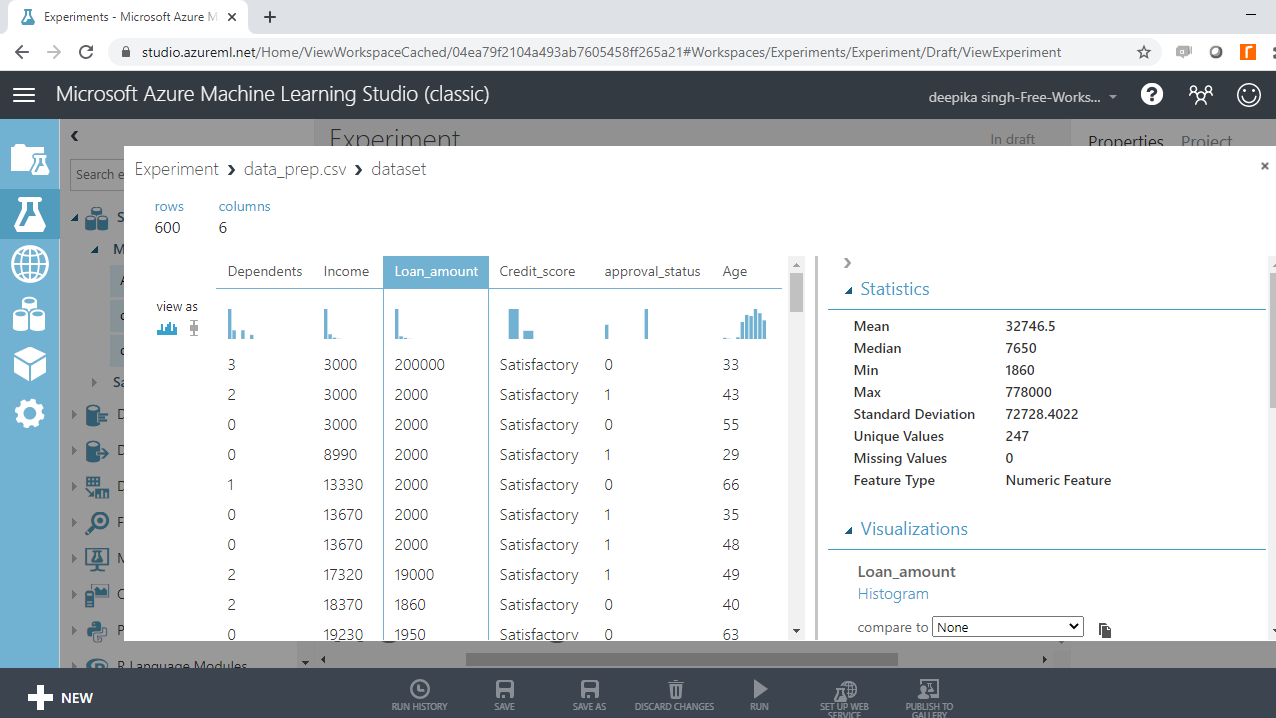
上面的两个输出都表明变量中存在异常值。您将在后续章节中处理这些问题。
错误记录
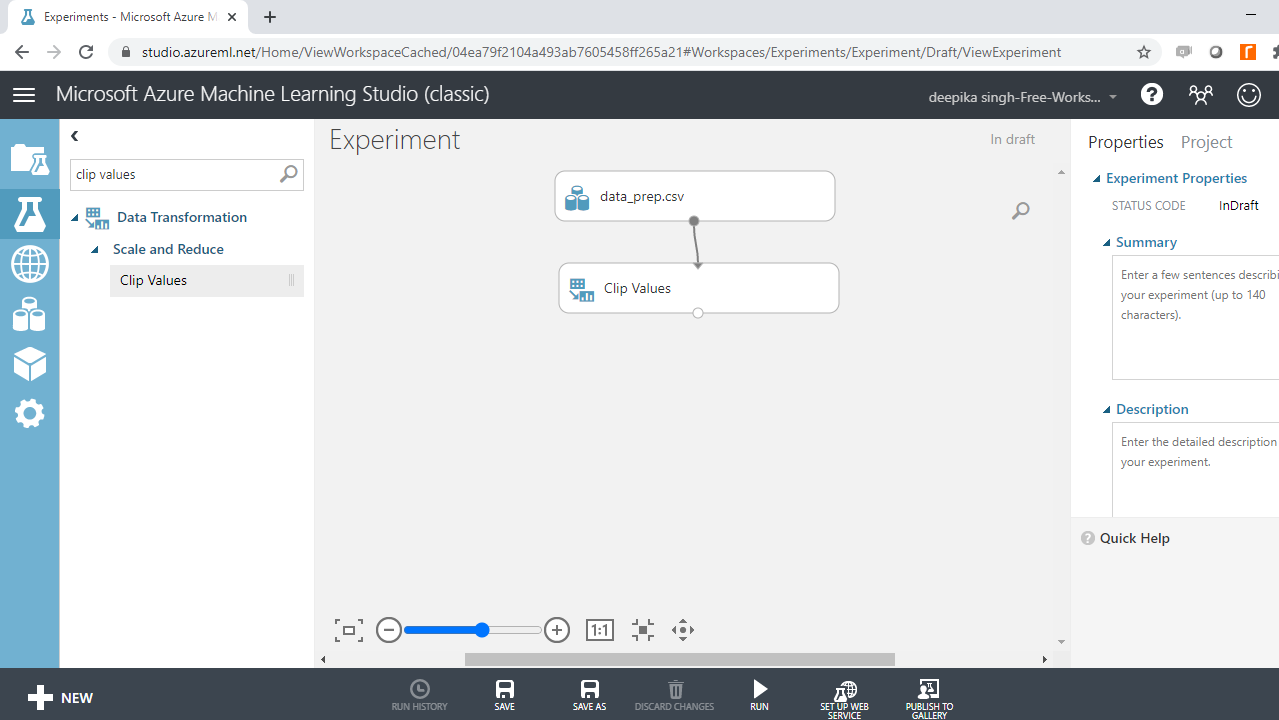
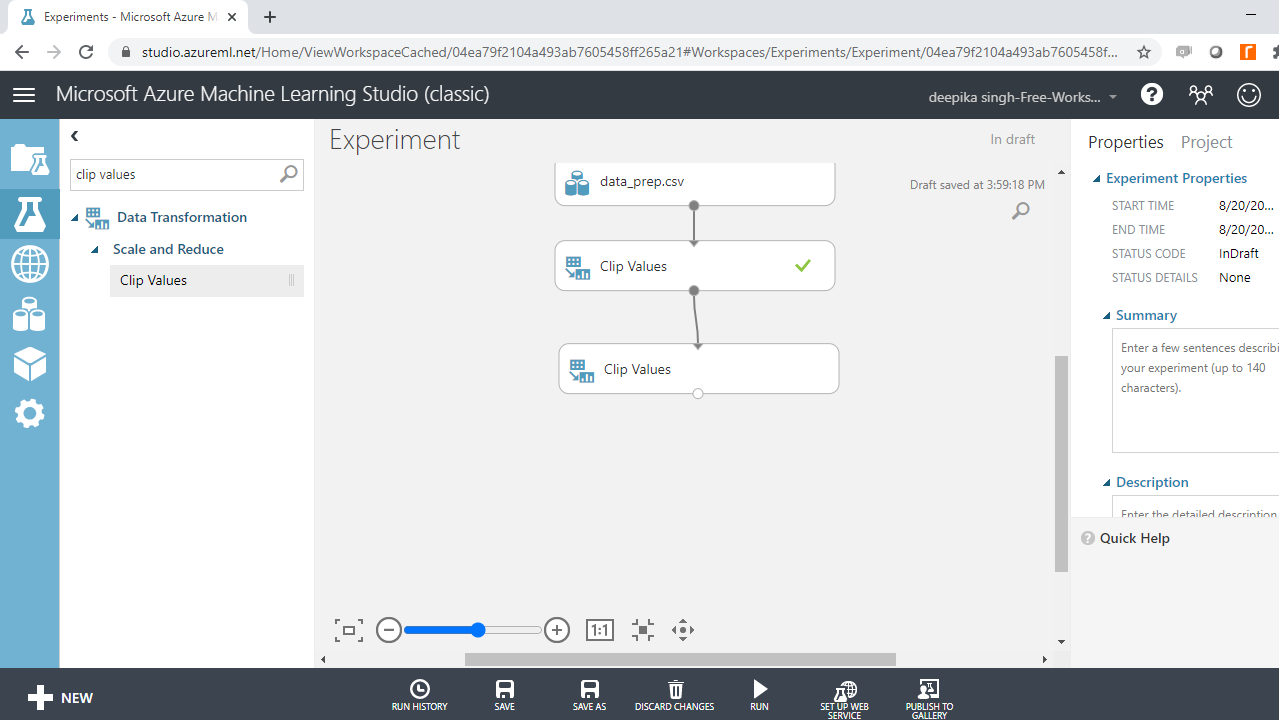
从上面的分析中,您知道变量Age的记录不正确。要处理这种不一致,一种方法是使用Clip Values模块来裁剪值,该模块用于识别并选择性地替换高于或低于指定阈值的数据值。
首先在搜索栏中输入剪辑值以找到剪辑值模块,然后将其拖到工作区中,如下所示。
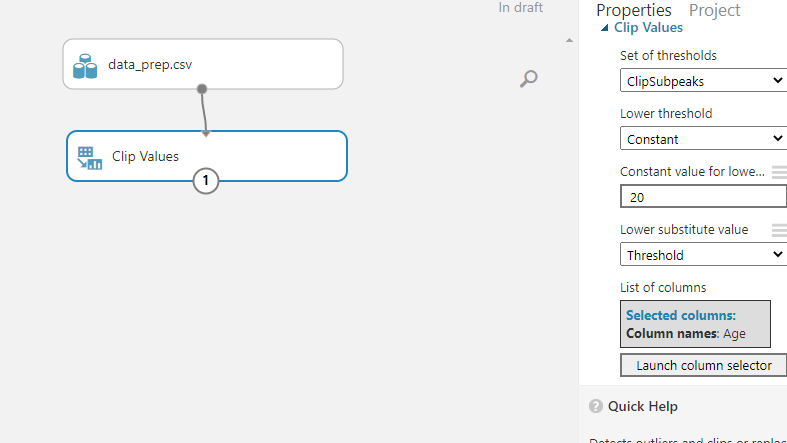
接下来,单击启动列选择器以选择用于识别重复项的列。这可以在属性窗格中找到。选择变量Age。
下一步是设置Clip Values模块。ClipSubpeaks选项指定下限。低于边界值的值将被替换或删除。在本例中,将下限值保持在 20。这意味着年龄的最小值为 20。设置完成后,单击Run。
要检查上一步的结果,请单击“可视化”。
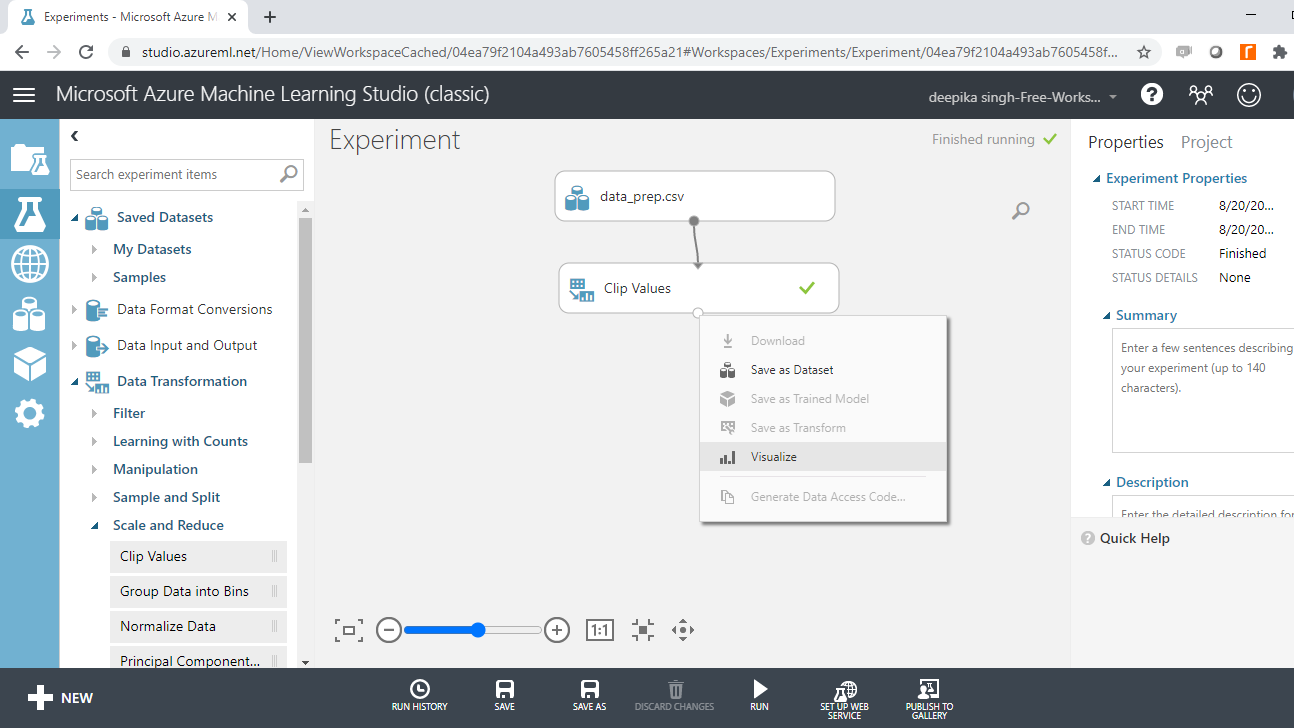
接下来,选择年龄变量,你会看到负值已被替换。年龄的新亚峰值为二十岁。
处理异常值
预测建模中的另一个障碍是存在异常值,即与其他数据点不同的极端值。异常值通常是一个问题,因为它们会误导训练过程并导致模型不准确。您可以通过直方图直观地识别异常值,也可以通过汇总统计值以数字方式识别异常值。
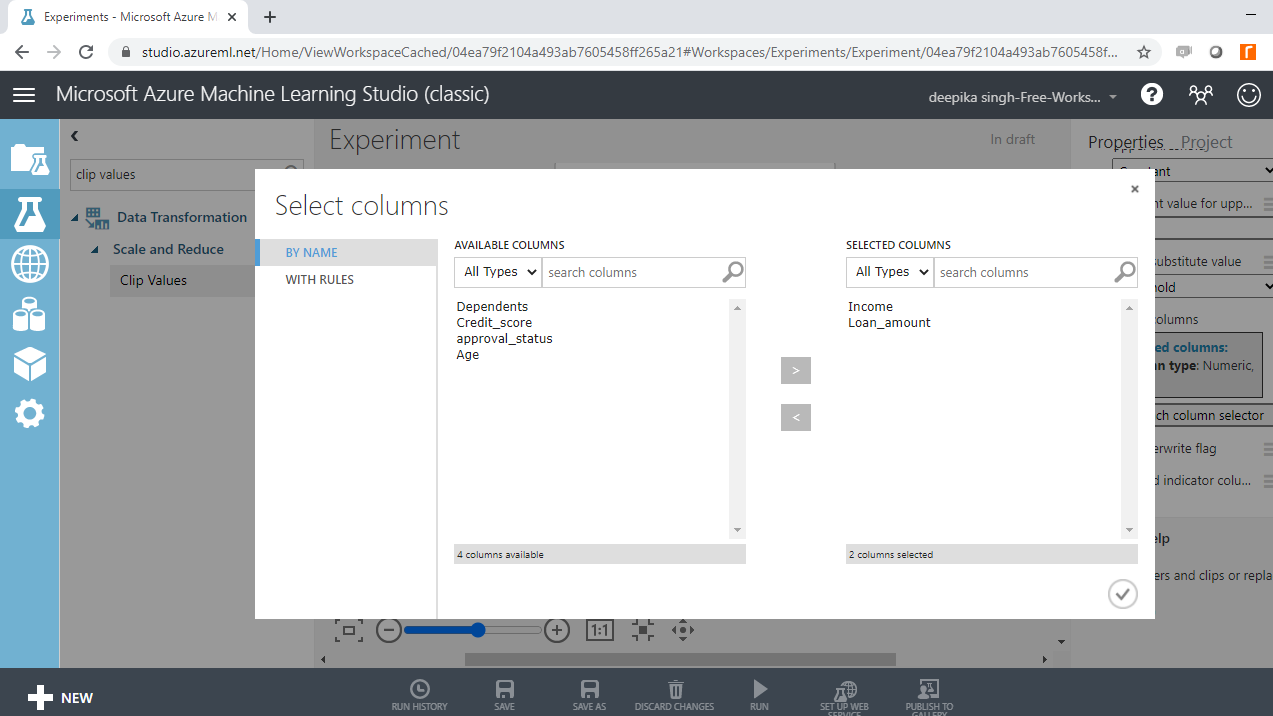
在探索数据时,您发现Income和Loan_amount变量有异常值。要开始处理异常值,请将Clip Values模块拖到工作区中,如下所示。
单击启动列选择器并选择两个变量。
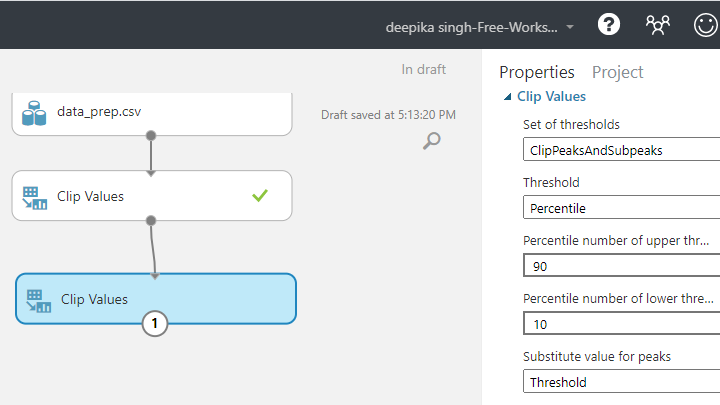
在“属性”窗格中,在选项中作出以下参数。
对于阈值集,选择ClipPeaksAndSubpeaks选项。这将指定上边界和下边界。
对于阈值,选择百分位数选项。这将指定百分位数范围内的值。
将下限阈值的百分位数值设置为 10,将上限阈值的百分位数值设置为 90。这意味着低于和高于这些阈值的值将分别被第十和第九十个百分点的数值替换。
设置完成后,单击下面显示的“运行选定选项”。
要检查上述转换的结果,请右键单击输出端口并选择“可视化”。
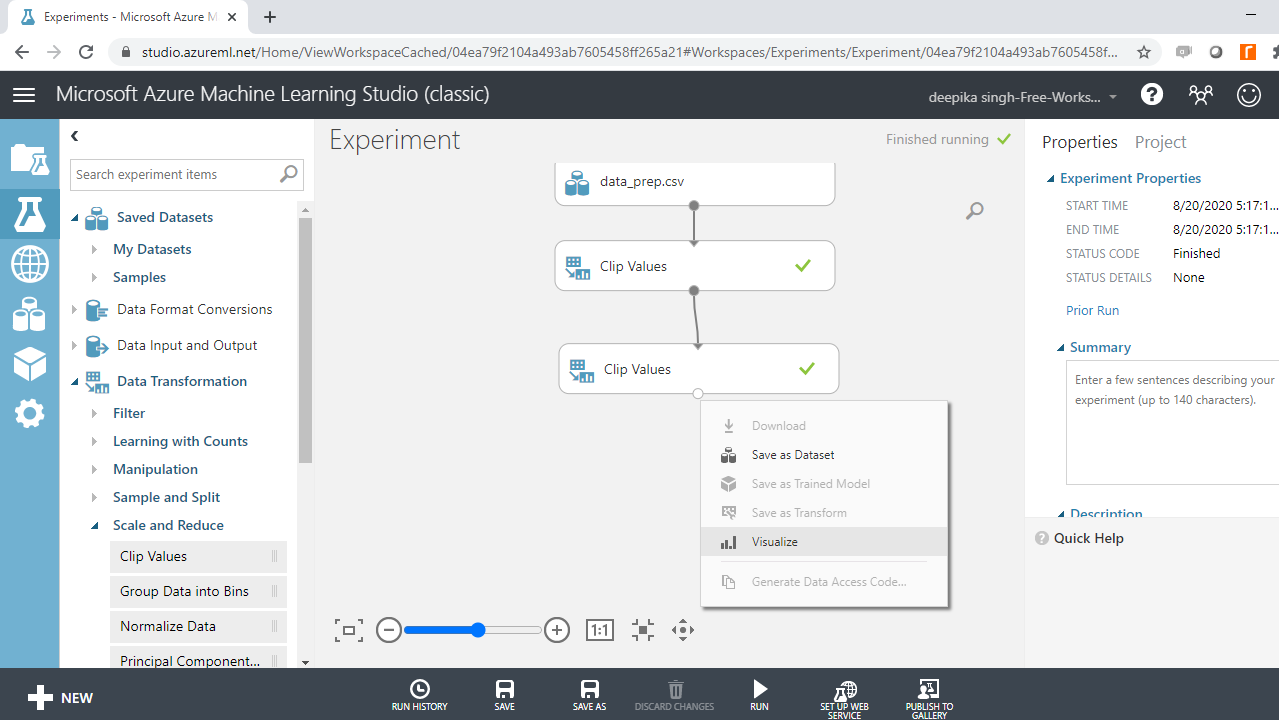
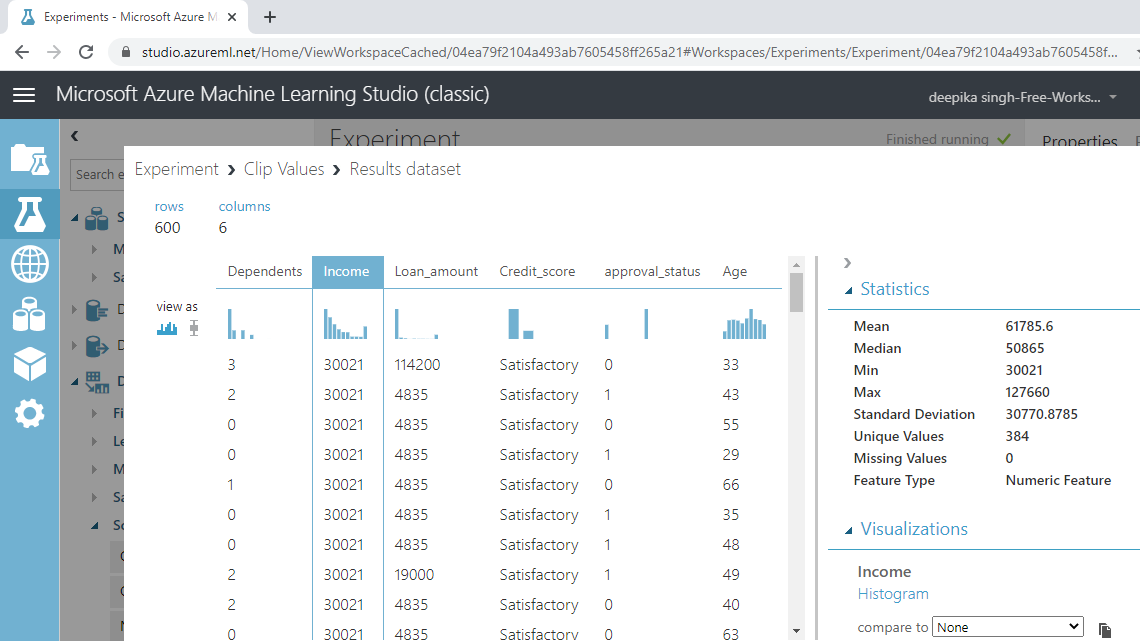
单击收入变量并检查结果。汇总统计值表明平均值和中位数现在更接近,标准差从 71,213 美元降至 30,771 美元。
规范化数据
您已移除异常值,但数值变量的单位不同,例如年龄(以年为单位)和收入(以美元为单位)。当特征使用不同的尺度时,尺度较大的特征可能会过度影响模型。因此,对数据进行规范化非常重要。规范化的目标是将数值列的值更改为使用通用尺度。某些算法也需要进行规范化才能正确建模数据。
要执行规范化,请搜索并将规范化数据模块拖到工作区。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~