
使用 TensorFlow 构建推荐引擎
介绍
了解如何构建推荐引擎是数据科学家教育中的一个重要里程碑。毕竟,推荐引擎为电子商务市场提供了非常有用且有利可图的推荐功能。事实上,您和您的家人很可能遇到过类似“购买新笔记本电脑?这是像您这样的人过去购买的东西”的情况,并从中受益匪浅。
现在,无论您是计划以数据科学家的身份加入电子商务企业,还是攻读数据科学硕士学位,了解如何构建推荐引擎都会为您打开大门,而且您最终肯定会这样做。为了帮助您尽快上手,本指南将向您介绍一些最有用的概念,您可以学习这些概念以使用 TensorFlow 快速构建推荐引擎。
背景
推荐引擎背后的主要原理是协同过滤,即利用来自多个用户(“协作者”)的知识进行自动预测(“过滤器”)。这样的例子比比皆是,但最有名的当然是 Netflix 和亚马逊。Netflix 会根据您过去的观看历史和评论向您推荐电影。在幕后,协同过滤技术利用其他观看者的大量历史和评论为您提供最佳推荐。同样,亚马逊利用其他客户的历史数据为您提供方便的产品推荐。
协同过滤最常用的技术是矩阵分解。这项技术因几年前赢得著名的“Netflix 奖”而闻名。该技术背后的理念是,有几个“潜在”或隐藏的变量负责用户的评分。例如,也许某个用户对《哈利波特》和《指环王》等书籍的评分很高,但对亚历山大·汉密尔顿的传记的评分很低。一个可以解释这一观察结果的潜在变量是,评分高的书籍属于幻想类,而用户看重幻想类书籍。因此,我们可能有一个潜在的幻想变量。
从数学上讲,所有评分矩阵R表示为两个矩阵P和Q的乘积,其内部维度表示潜在变量。矩阵P是用户矩阵,显示每个用户如何评价潜在变量,矩阵Q是书籍或产品矩阵,显示每本书或产品与每个潜在变量的对应程度。
例如,假设只有幻想潜在变量。那么P 用户矩阵可能如下所示:
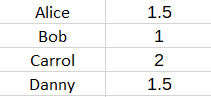
这描述了每个 用户对幻想的喜爱程度。Q Books矩阵可能如下所示:

这个矩阵描述了每本书在多大程度上属于奇幻类型。产品R将决定评级,在本例中,它是:
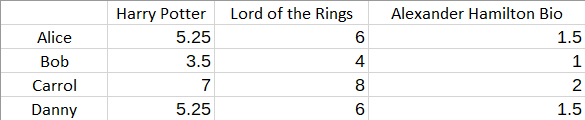
对于我们来说,目标是从R开始,然后计算潜在特征和矩阵P和Q。请注意,如果矩阵R中的某些元素缺失,则解决此问题可能会成为一个困难的优化问题。
在进行预测时,假设您想预测一位名叫 Ellen 的新用户的偏好。另外假设我们知道 Ellen 给《哈利波特》打了 6 分。
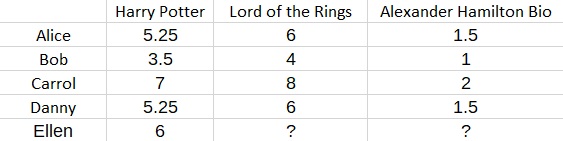
那么我们知道艾伦的幻想特征F必须满足
十

=
以便
3.5 F = 6
因此
F = 1.7
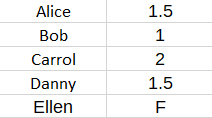
因此,我们可以填写矩阵的其余部分以获得对 Ellen 的预测:
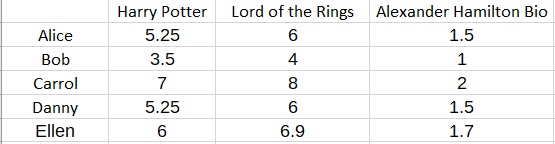
更一般地,我们可能对新用户(即“样本外”用户)有多个评分或观察结果,例如 Ellen。此用户的评分可能与矩阵分解模型不完全吻合。但这是正常的,也是意料之中的。因此,您应该做的是通过普通最小二乘法寻找最佳拟合预测。
实施:培训
此部分和后续部分的代码可在https://github.com/emmanueltsukerman/build-a-recommendation-engine-with-tensorflow.git找到
假设你获得了一系列评级。
import numpy as np
ratings = np.array(
[
[3.0, 3.0, 2.0, 3.0, 3.0, 3.0],
[4.0, 1.0, 1.0, 4.0, 5.0, 3.0],
[1.0, 2.0, 2.0, 1.0, 1.0, 2.0],
[3.0, 2.0, 1.0, 3.0, 4.0, 3.0],
[1.0, 5.0, 3.0, 1.0, 1.0, 3.0],
[2.0, 5.0, 3.0, 2.0, 3.0, 4.0],
[2.0, 2.0, 1.0, 2.0, 2.0, 2.0],
[1.0, 4.0, 3.0, 1.0, 2.0, 3.0],
]
)
加载 TensorFlow 并指定潜在变量的数量K。
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
K = 2
R = ratings
接下来,配置 TensorFlow 计算。创建P和Q矩阵及其乘积,并将损失设置为P和Q矩阵乘积与评分矩阵之间的平方误差。
N = len(ratings)
M = len(ratings[0])
P = np.random.rand(N, K)
Q = np.random.rand(M, K)
ratings = tf.placeholder(tf.float32, name="ratings")
P_matrix = tf.Variable(P, dtype=tf.float32)
Q_matrix = tf.Variable(Q, dtype=tf.float32)
P_times_Q = tf.matmul(P_matrix, Q_matrix, transpose_b=True)
squared_error = tf.square(P_times_Q - ratings)
loss = tf.reduce_sum(squared_error)
选择优化器,在本例中为梯度下降。
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
最后,训练模型计算P和Q矩阵。
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(5000):
sess.run(train, {ratings: R})
检查生成的矩阵。
final_P_times_Q = np.around(sess.run(P_times_Q), 3)
print(final_P_times_Q)
print()
final_P_matrix = np.around(sess.run(P_matrix), 3)
print(final_P_matrix)
print()
final_Q_matrix = np.transpose(np.around(sess.run(Q_matrix), 3))
print(final_Q_matrix)
print()
[[2.721 2.93 1.932 2.721 3.375 3.185] [4.056 1.135 0.787 4.056 4.902 3.014] [0.93 2.376 1.55 0.93 1.208 1.826] [3.136 1.898 1. 269 3.136 3.83 2.877] [0.846 4.844 3.146 0.846 1.206 3.099] [2.157 4.917 3.211 2.157 2.778 3.916] [ 1.826 1.825 1.205 1.826 2.258 2.061] [1.226 4.198 2.733 1.226 1.635 2.979]]
[[1.422 0.955] [2.364 0.085] [0.382 0.895] [1.75 0.488] [0.146 1.924] [0.931 1.83] [0.965 0.582] [0.424 1.621]]
[[1.705 0.39 0.275 1.705 2.057 1.22 ] [0.311 2.488 1.615 0.311 0.471 1.519]]
如您所见,P和Q的乘积非常接近原始评分。通过增加K可能会获得更好的近似值,但代价是过度拟合的可能性更高。
实现:预测
假设观察到一个新用户,其评分如下。
new_user_indices = [1, 2, 4, 5]
new_user_ratings = [2, 2, 1, 2]
换句话说,用户分别对第 2、第 3、第 5 和第 6 个产品给出了评分 2、2、1 和 2。现在你将预测此用户剩余的评分。
为此,您将对P的新行实施普通最小二乘拟合,通过与Q相乘将导致矩阵R具有与新用户的新行相对应的新行。
new_user_P_row_initial = np.random.rand(1, K)
new_user_P_row = tf.Variable(new_user_P_row_initial, dtype=tf.float32)
new_user_P_row_times_Q = tf.matmul(new_user_P_row, final_Q_matrix)
res = tf.gather(new_user_P_row_times_Q, new_user_indices, axis=1)
squared_error = tf.square(new_user_ratings - res)
loss = tf.reduce_sum(squared_error)
optimizer = tf.train.GradientDescentOptimizer(0.01)
predict = optimizer.minimize(loss)
运行计算。
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(50000):
sess.run(predict)
最后打印出计算的结果,就会得到新用户对应的新行。
final_new_user_P_row_times_Q = np.around(sess.run(new_user_P_row_times_Q), 3)
print(np.round(final_new_user_P_row_times_Q))
[[1. 2. 2. 1. 1. 2.]]
太棒了!您已成功使用以前的评分历史记录和矩阵分解技术预测了新用户的评分。
结论
现在,您已经基本掌握了如何使用 TensorFlow 中的矩阵分解创建原型推荐引擎。这很重要。您可以通过学习其他矩阵分解技术(例如Funk MF、<font s
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~