
探索 R 库:MICE
介绍
处理缺失值是数据科学家在构建机器学习模型时经常要完成的任务。处理缺失值的方法有很多种,如果你想使用高级技术,R 中的mice库是个不错的选择。
MICE 代表链式方程多元插补,其工作原理是为多元缺失数据创建多个插补(替换值)。MICE 算法可用于不同类型的数据类型,例如连续、二进制、无序分类和有序分类数据。
在本指南中,您将学习如何使用R 中的mice库。
数据
在本指南中,您将使用包含 600 个观测值和 8 个变量的虚构贷款申请人数据,如下所述:
Is_graduate:申请人是否为毕业生(“是”)或不是(“否”)
收入:申请人的年收入(美元)
Loan_amount:提交申请的贷款金额(美元)
Credit_score:申请人的信用评分是否令人满意(“Satisfactory”)或不令人满意(“Not_Satisfactory”)
审批状态:贷款申请是否获得批准(“是”)或未获得批准(“否”)
年龄:申请人的年龄(岁)
投资额:申请人申报的股票和共同基金投资总额(美元)
目的:申请贷款的目的
第一步是加载所需的库和数据。
library(plyr)
library(readr)
library(dplyr)
library(caret)
library(mice)
library(VIM)
dat <- read_csv("C:/Notes_Old/A_Resources/data_qna/Content writing/R guides/caret package/data_mice.csv")
glimpse(dat)
输出:
Observations: 600
Variables: 8
$ Is_graduate <chr> "No", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Ye...
$ Income <int> 3000, 3000, 3000, 3000, 8990, NA, NA, NA, NA, NA, N...
$ Loan_amount <dbl> 6000, NA, NA, NA, 8091, NA, NA, NA, NA, NA, NA, NA,...
$ Credit_score <chr> "Satisfactory", "Satisfactory", "Satisfactory", NA,...
$ approval_status <chr> "Yes", "Yes", "No", "No", "Yes", "No", "Yes", "Yes"...
$ Age <int> 27, 29, 27, 33, 29, NA, 29, 27, 33, 29, NA, 29, 27,...
$ Investment <dbl> 9331, 9569, 2100, 2100, 6293, 9331, 9569, 9569, 121...
$ Purpose <chr> "Education", "Travel", "Others", "Others", "Travel"...
输出显示数据集有四个数值变量和四个字符变量。您将使用以下代码将它们转换为因子变量。
names <- c(1,4,5,8)
dat[,names] <- lapply(dat[,names] , factor)
glimpse(dat)
输出:
Observations: 600
Variables: 8
$ Is_graduate <fct> No, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, No...
$ Income <int> 3000, 3000, 3000, 3000, 8990, NA, NA, NA, NA, NA, N...
$ Loan_amount <dbl> 6000, NA, NA, NA, 8091, NA, NA, NA, NA, NA, NA, NA,...
$ Credit_score <fct> Satisfactory, Satisfactory, Satisfactory, NA, NA, S...
$ approval_status <fct> Yes, Yes, No, No, Yes, No, Yes, Yes, Yes, No, No, N...
$ Age <int> 27, 29, 27, 33, 29, NA, 29, 27, 33, 29, NA, 29, 27,...
$ Investment <dbl> 9331, 9569, 2100, 2100, 6293, 9331, 9569, 9569, 121...
$ Purpose <fct> Education, Travel, Others, Others, Travel, Travel, ...
缺失数据模式分析
summary ()函数快速概览变量和缺失值(如果有)。
summary(dat)
输出:
Is_graduate Income Loan_amount Credit_score
No :130 Min. : 3000 Min. : 6000 Not _satisfactory:123
Yes:470 1st Qu.: 39045 1st Qu.:115665 Satisfactory :458
Median : 50995 Median :135990 NA's : 19
Mean : 65901 Mean :149313
3rd Qu.: 76170 3rd Qu.:170740
Max. :277770 Max. :466660
NA's :20 NA's :17
approval_status Age Investment Purpose
No :190 Min. :22.00 Min. : 2100 Education: 94
Yes:410 1st Qu.:35.00 1st Qu.: 16678 Home :132
Median :50.00 Median : 26439 Others : 64
Mean :48.82 Mean : 34442 Personal :174
3rd Qu.:61.00 3rd Qu.: 35000 Travel :118
Max. :76.00 Max. :190422 NA's : 18
NA's :19
上面的输出显示一些变量有缺失值,用NA表示。为了更好地理解缺失值的模式,可以使用md.pattern()函数。
md.pattern(dat)
输出:
Is_graduate approval_status Investment Loan_amount Purpose
559 1 1 1 1 1
4 1 1 1 1 1
4 1 1 1 1 1
3 1 1 1 1 1
10 1 1 1 1 0
3 1 1 1 1 0
2 1 1 1 0 1
2 1 1 1 0 1
1 1 1 1 0 1
1 1 1 1 0 1
6 1 1 1 0 1
4 1 1 1 0 0
1 1 1 1 0 0
0 0 0 17 18
Credit_score Age Income
559 1 1 1 0
4 1 0 1 1
4 0 1 1 1
3 0 1 0 2
10 1 0 1 2
3 1 0 0 3
2 1 1 1 1
2 1 1 0 2
1 1 0 0 3
1 0 1 1 2
6 0 1 0 3
4 0 1 0 4
1 0 0 0 5
19 19 20 93
输出的最上面一行显示有 559 条记录没有缺失值。只有Income变量中有 10 条记录有缺失值,该变量总共有 20 个缺失值。
也可以用下面的代码来分析缺失值模式。
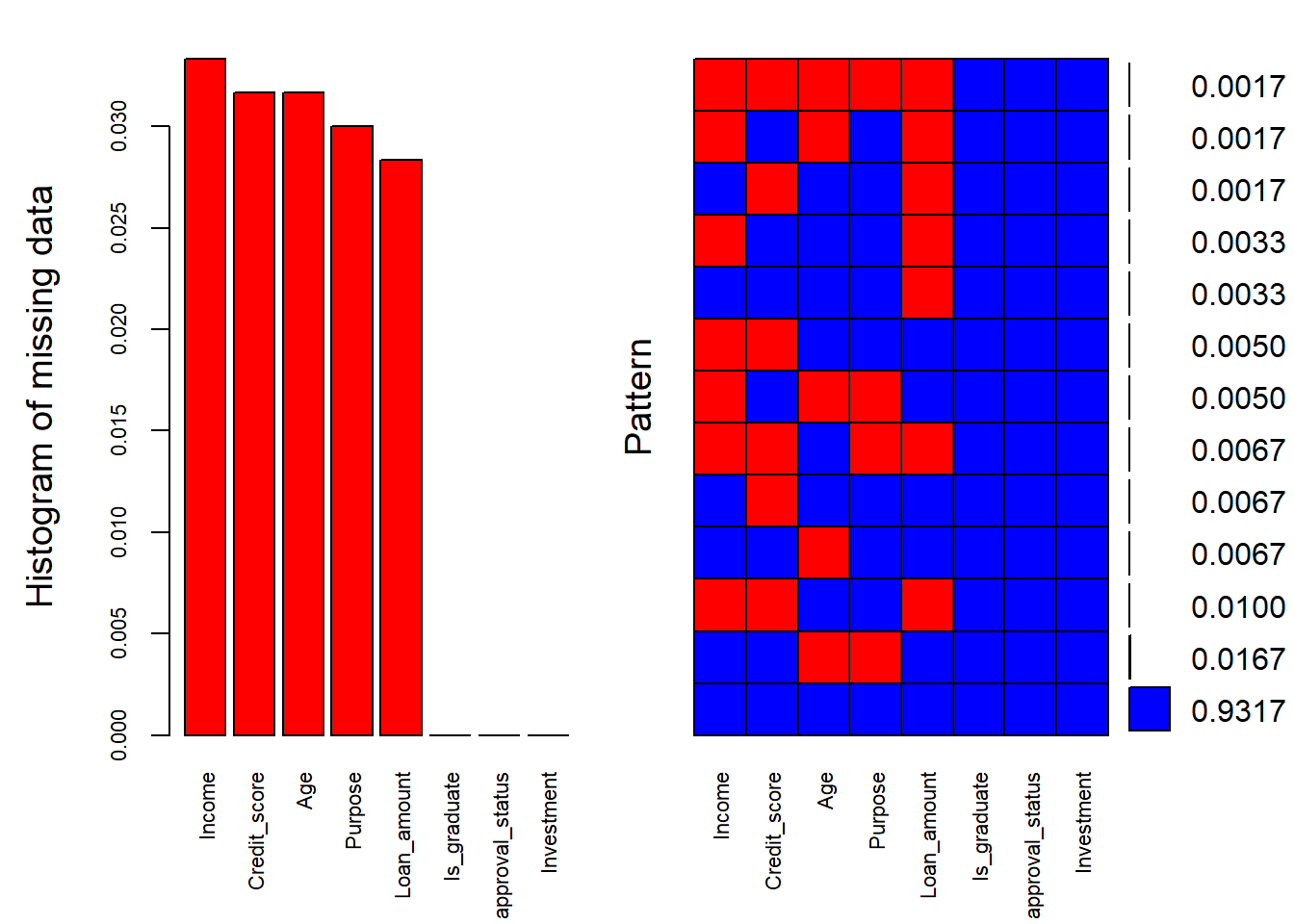
plot1 <- aggr(dat, col=c('blue','red'), numbers=TRUE, sortVars=TRUE, labels=names(dat), cex.axis=.7, gap=3, ylab=c("Histogram of missing data","Pattern"))
输出:
Variables sorted by number of missings:
Variable Count
Income 0.03333333
Credit_score 0.03166667
Age 0.03166667
Purpose 0.03000000
Loan_amount 0.02833333
Is_graduate 0.00000000
approval_status 0.00000000
Investment 0.00000000
上面的输出打印了每个变量中缺失值的百分比。总体而言,93%的数据没有缺失值,可以从下面右侧的图中看到。
缺失值的数量不多,您可以删除这些观察值。但目标是使用mice库来处理缺失值。
MICE 估算
mice ()函数用于估算缺失值。代码中使用的一些重要参数解释如下。
数据:包含不完整数据的数据框或矩阵。缺失值编码为NA。
m:多重插补的次数。默认值为五。
method:指定数据中每列要使用的插补方法。在本例中,您使用预测均值匹配 (PMM) 作为插补方法。
maxit:给出迭代次数的标量。默认值为 5。
上述参数传递给插补函数。
imputed_data <- mice(dat,m=5,maxit=50,meth='pmm',seed=500)
summary(imputed_data)
输出:
Class: mids
Number of multiple imputations: 5
Imputation methods:
Is_graduate Income Loan_amount Credit_score approval_status
"" "pmm" "pmm" "pmm" ""
Age Investment Purpose
"pmm" "" "pmm"
PredictorMatrix:
Is_graduate Income Loan_amount Credit_score approval_status Age
Is_graduate 0 1 1 1 1 1
Income 1 0 1 1 1 1
Loan_amount 1 1 0 1 1 1
Credit_score 1 1 1 0 1 1
approval_status 1 1 1 1 0 1
Age 1 1 1 1 1 0
Investment Purpose
Is_graduate 1 1
Income 1 1
Loan_amount 1 1
Credit_score 1 1
approval_status 1 1
Age 1 1
如果您想查看特定变量的估算数据(例如变量目的),您可以使用以下代码来实现。
imputed_data$imp$Purpose
输出:
1 2 3 4 5
9 Travel Education Travel Personal Travel
10 Education Home Home Home Home
11 Home Personal Home Home Travel
12 Home Home Travel Home Home
13 Education Education Travel Travel Home
588 Travel Others Travel Travel Personal
589 Travel Travel Personal Personal Personal
590 Travel Travel Travel Travel Personal
591 Travel Personal Travel Travel Others
592 Travel Personal Travel Travel Education
593 Home Education Personal Travel Education
594 Home Home Home Home Home
595 Personal Education Travel Travel Education
596 Travel Travel Travel Travel Home
597 Personal Travel Travel Travel Home
598 Home Education Travel Travel Education
599 Others Personal Personal Travel Personal
600 Others Travel Travel Travel Travel
上述输出显示,对于Purpose变量中的 18 个缺失值,有五组可用的插补。
下一步是使用以下代码完成对整个数据的缺失值插补。缺失值将被替换为五个插补数据集中的第一个数据集中的值,由第二个参数中的值 1 表示。
completeddata1 <- complete(imputed_data,1)
summary(completeddata1)
输出:
Is_graduate Income Loan_amount Credit_score
No :130 Min. : 3000 Min. : 6000 Not _satisfactory:129
Yes:470 1st Qu.: 38498 1st Qu.:112973 Satisfactory :471
Median : 50835 Median :134385
Mean : 65819 Mean :146552
3rd Qu.: 76040 3rd Qu.:168715
Max. :277770 Max. :466660
approval_status Age Investment Purpose
No :190 Min. :22.00 Min. : 2100 Education: 96
Yes:410 1st Qu.:35.00 1st Qu.: 16678 Home :137
Median :50.00 Median : 26439 Others : 66
Mean :49.18 Mean : 34442 Personal :176
3rd Qu.:61.25 3rd Qu.: 35000 Travel :125
Max. :76.00 Max. :190422
新数据的摘要显示没有任何缺失值,表明缺失值插补已完成。您可以继续使用新数据进行模型构建,以检查插补数据的模型性能。
使用插补数据建立模型
下面的代码行创建数据分区,在训练数据集上构建随机森林算法,并在测试数据集上评估模型。
# Create Data Partition
set.seed(100)
trainRowNumbers <- createDataPartition(completeddata1$approval_status, p=0.7, list=FALSE)
train <- completeddata1[trainRowNumbers,]
test <- completeddata1[-trainRowNumbers,]
# Build Random Forest Algorithm
control1 <- tra免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~