
机器学习中的集成方法:Bagging 与 Boosting
介绍
集成方法*是一种将来自多个基础机器学习 (ML) 模型的决策结合起来以找到预测模型以实现最佳结果的技术。请考虑下图中描绘的盲人和大象的寓言。盲人各自从自己的角度描述大象。他们的描述都是正确的,但不完整。如果他们聚在一起讨论并结合他们的描述,他们对大象的理解将更加准确和现实。
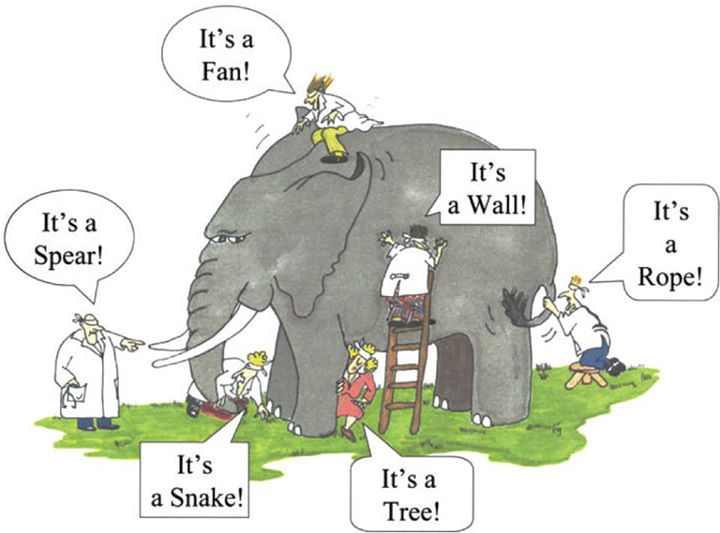
集成方法的主要原理是将弱学习器和强学习器结合起来,形成强大而多功能的学习器。
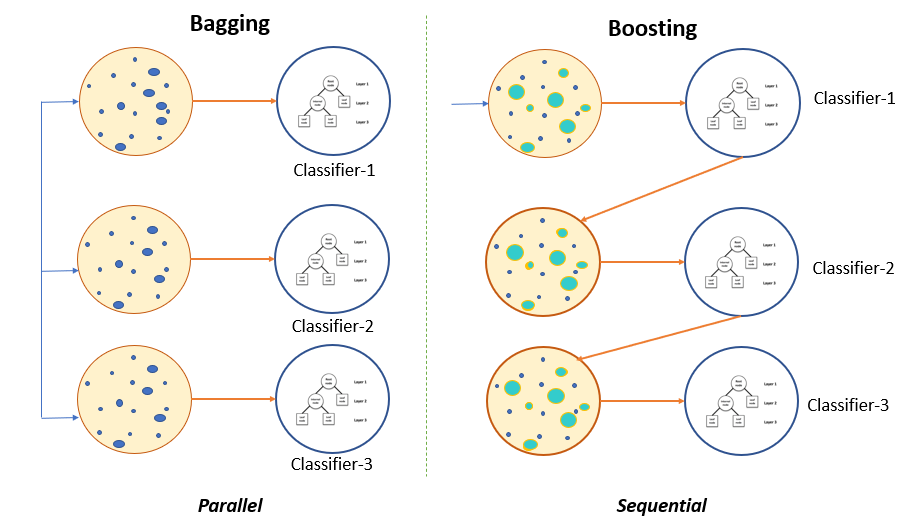
本指南将向您介绍集成学习的两种主要方法:bagging和boosting。 bagging 是并行集成,而 boosting 是顺序集成。
本指南将使用sci-kit 学习数据集库中的 Iris 数据集。
但首先,让我们讨论一下引导和决策树,这两者对于集成方法都至关重要。
引导
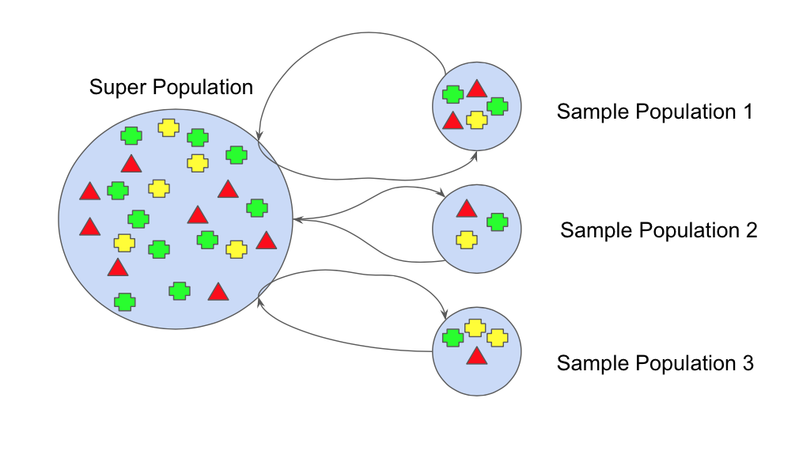
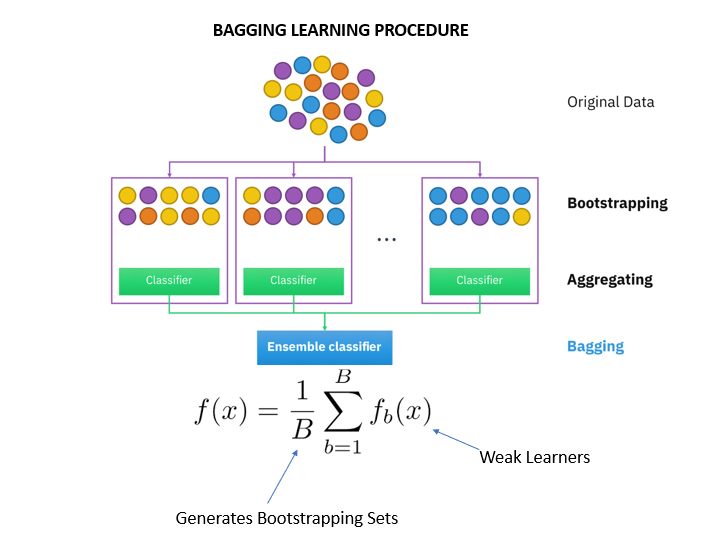
引导法是指从整个数据集中创建多个小的数据子集。这些数据子集被随机采样和替换。样本的替换称为重采样。
子集的每个部分将具有相同的概率。它将改变数据集的平均值和标准差,使模型更加稳健。集成方法中的基础学习器和分类器将映射到这些子集上。
决策树
在机器学习中,决策树对基于决策的分析问题影响巨大。它们涵盖分类和回归。顾名思义,它们使用包含节点和叶子的树状模型。
下面的决策树确定一个人是否健康。
在上图中,模型的根位于顶部 — 这是一棵倒置的树!这里,条件是内部节点,结果是叶节点。
请注意,决策树包含多个严格顺序的 if-else 语句,这使得模型不够灵活。这会导致过度拟合,即当函数与数据拟合得太好时发生的情况。这意味着模型仅在训练过的数据上准确。如果训练数据或新数据有轻微变化,模型就会失效。
使用一棵决策树可能会有问题,而且可能不够稳定;但是,使用多棵决策树并组合它们的结果会很好。在预测模型中组合多个分类器称为集成。集成方法的简单规则是通过减少方差来减少误差。
集成技术
在本节中,您将了解包括 bagging 和 boosting 在内的集成技术。
装袋
术语“bagging”源于单词B ootstrap Agg regator。

它将基础学习器(分类器)拟合到从原始数据集(引导)中获取的每个随机子集上。由于并行集成,训练集中的所有分类器彼此独立,因此每个模型将继承略有不同的特征。
接下来,bagging 将所有学习者的结果结合起来,并通过平均他们的输出来添加(汇总)他们的预测以得到最终结果。
随机森林(RF)算法可以解决决策树的过拟合问题。随机森林是决策树的集合。它构建一个由许多随机决策树组成的森林。
RF和Bagging的过程几乎相同。RF只从子集中选择最好的特征来分裂节点。
多样化的结果减少了方差,从而给出了平稳的预测。
提升
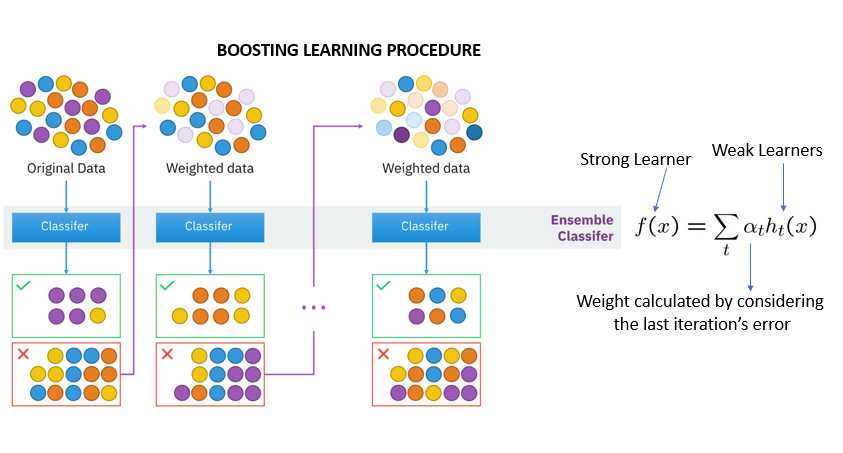
增强技术遵循顺序。一个基础学习器的输出将被输入到另一个基础学习器。如果一个基础分类器被错误分类(红色框),其权重将会增加(过加权),下一个基础学习器将进行更正确的分类。
下一个合乎逻辑的步骤是结合分类器来预测结果。
梯度下降增强、AdaBoost 和 XGbooost 是增强方法的一些扩展。
梯度提升可最大限度地减少损失,但在迭代中增加了梯度优化,而自适应提升(AdaBoost) 会针对每个新的预测变量调整权重实例。
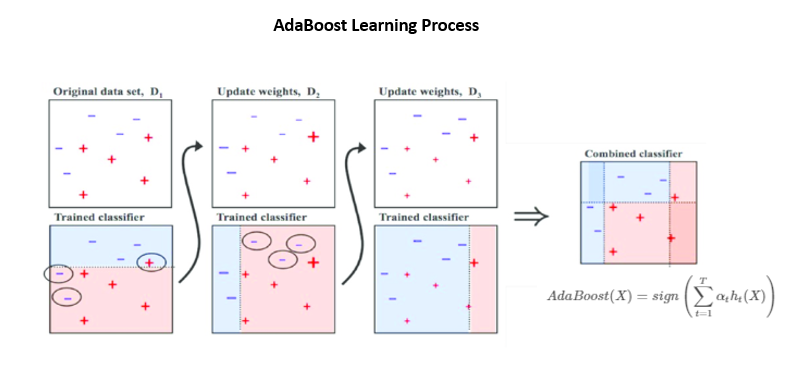
实际上,增强(或任何其他集成方法)都会降低模型过度拟合的可能性。
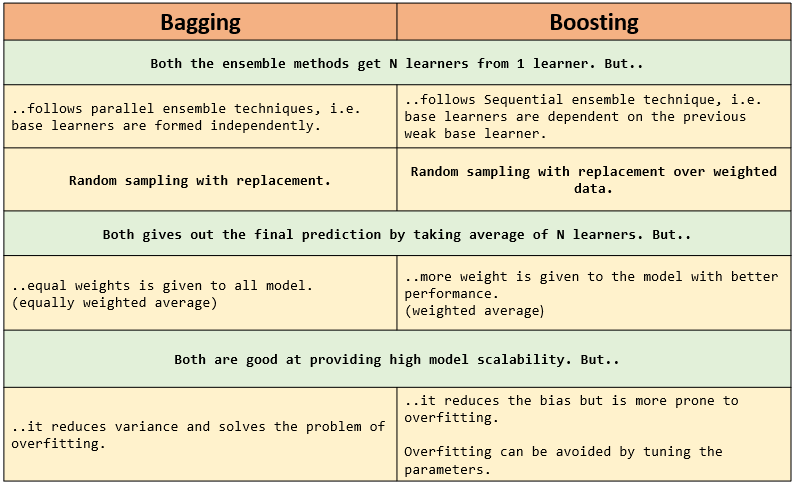
比较 Bagging 和 Boosting
下表显示了集成方法之间的相似点和不同点。
是时候实现代码了。
代码实现
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, BaggingClassifier, GradientBoostingClassifier,AdaBoostClassifier
from sklearn import datasets # import inbuild datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.metrics import confusion_matrix
从 ski-kit 学习数据集加载 Iris 数据。
iris = datasets.load_iris()
X = iris.data
y = iris.target
下一步是使用保留方法将数据集分成 70% 用于训练,30% 用于测试。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
决策树
初始化分数,因为它将帮助您检查模型是否过度拟合。实现任何分类器模型的标准过程是调用分类器函数,在训练数据和目标数据上拟合分类器,最后在 X_test 上预测结果。
score=[]
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)

classifier.score(X_train, y_train),classifier.score(X_test, y_test)
(1.0, 0.9777777777777777)
嗯,测试分数看起来不错,但是1.0 的分数表明模型过度拟合!
集成模型来救援!
装袋:随机森林
rf = RandomForestClassifier(n_estimators=100)
bag_clf = BaggingClassifier(base_estimator=rf, n_estimators=100,
bootstrap=True, n_jobs=-1,
random_state=42)
bag_clf.fit(X_train, y_train)
bag_clf.score(X_train,y_train),bag_clf.score(X_test,y_test)
(0.9904761904761905, 0.9777777777777777)
准确率在 98% 左右,而且模型解决了过拟合的问题。太棒了!
在预测物种之前,让我们先检查一下增强算法。
提升:梯度提升
Sci-kit learn 的梯度提升默认只使用决策树。因此,它也被称为梯度提升决策树。
gb = GradientBoostingClassifier(n_estimators=100).fit(X_train, y_train)
gb.fit(X_train, y_train)
gb.score (X_test,y_test),gb.score (X_train,y_train)
(0.9333333333333333, 1.0)
它过度拟合了!与决策树一样。让我们用 AdaBoost 检
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































{kind=link}
请先 登录后发表评论 ~