
构建你的第一个图像分类实验
介绍
掌握神经网络、TensorFlow和图像分类的相关知识是任何数据科学家必备的工具,即使对于应用领域不属于计算机视觉领域的数据科学家也是如此。事实上,卷积神经网络 (CNN)技术已在语音识别、恶意软件检测甚至气候理解等领域得到应用。本指南将通过一个有趣的猫狗分类入门项目,帮助您以闪电般的速度掌握这些工具的使用方法,然后为您指明成为图像分类专家的后续步骤。
本指南的代码可在Github上找到。
访问数据集
如果你还没有注册 Kaggle,请前往Kaggle并创建一个帐户。打开你的帐户设置,然后单击“创建新 API 令牌”:

这将下载一个 Kaggle API json 文件,您需要将其放置在~/.kaggle/kaggle.json(或者,对于典型的 Windows 设置,放置在C:\Users\<Windows-username>\.kaggle\kaggle.json)。
Kaggle API 是一种访问数据集的便捷方式。有关 Kaggle API 的更多信息,请参阅Kaggle API Github 页面。
如果您的环境缺少 Kaggle pip 库,请通过运行以下命令进行安装:
pip install kaggle
现在,您可以使用 Kaggle API。在您的环境中,运行:
kaggle competitions download -c dogs-vs-cats
这将下载“狗与猫”数据集。
接下来,您将解压缩数据集,并为了清晰起见,删除不需要的数据。
!unzip train.zip
!mv train data
!rm test1.zip sampleSubmission.csv train.zip
您现在拥有一个由猫和狗图像组成的数据集。
探索数据
接下来,您将进行一些数据探索。设置指向数据集位置的变量。
DATASET_LOCATION = "data"
收集数据集的标签和文件名。
import os
filenames = os.listdir(DATASET_LOCATION)
classes = []
for filename in filenames:
image_class = filename.split(".")[0]
if image_class == "dog":
classes.append(1)
else:
classes.append(0)
将数据集读入 pandas 数据框以方便访问。
import pandas as pd
df = pd.DataFrame({"filename": filenames, "category": classes})
df["category"] = df["category"].replace({0: "cat", 1: "dog"})
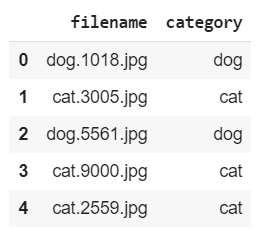
您可以看到现在有了文件的标签:
df.head()
此外,您可以看到数据集是平衡的,包含 12,500 张猫和狗的图像,每张图像:
df.category.value_counts()

以下代码块将显示一个随机图像:
import random
from keras.preprocessing.image import load_img
import matplotlib.pyplot as plt
sample1 = random.choice(filenames)
image1 = load_img(DATASET_LOCATION + "/" + sample1)
plt.imshow(image1)

以下是预览另一个数据点的代码:
sample2 = random.choice(filenames)
image2 = load_img(DATASET_LOCATION + "/" + sample2)
plt.imshow(image2)

图像的尺寸不一致:
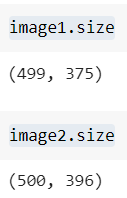
这很重要,因为对于标准神经网络分类器,输入的大小必须相同。幸运的是,这不是问题,因为您将把所有图像重新缩放为相同大小。指定所需的大小:
IMAGE_WIDTH = 64
IMAGE_HEIGHT = 64
IMAGE_SIZE = (IMAGE_WIDTH, IMAGE_HEIGHT)
INPUT_SHAPE = (IMAGE_WIDTH, IMAGE_HEIGHT, 1)
现在您已经很好地了解了数据集的组成。
实例化卷积神经网络 (CNN) 分类器
接下来,您将指定用于对图像进行分类的神经网络的架构。您将使用的架构是一个简单的标准 CNN,旨在作为起点。实现 CNN 的库称为Keras,它是一个高级 API,可以在后台使用较低级别的神经网络库,例如 TensorFlow。
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=INPUT_SHAPE))
model.add(Conv2D(64, (3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(2, activation="softmax"))
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=["accuracy"],
)
该模型由卷积层、最大池化层、密集层和 dropout 层组成。它使用分类交叉熵作为损失函数,并使用 Adadelta 作为优化器。
预处理数据集
为了在数据上训练模型,并能够在训练时评估其性能,将数据集分为训练集和测试集:
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size=0.20, random_state=42)
Keras 还提供了非常方便的方法来执行数据增强和从目录读取图像。数据增强是一个使用现有数据生成新数据的过程。例如,您可以获取现有图像并将其翻转以创建另一个数据点。这就是 ImageDataGenerator允许您执行的操作。
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rotation_range=15,
rescale=1.0 / 255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
)
flow_from_dataframe方法可以有效地读取和预处理目录的文件。
BATCH_SIZE = 16
train_generator = train_datagen.flow_from_dataframe(
train_df,
DATASET_LOCATION,
x_col="filename",
y_col="category",
target_size=IMAGE_SIZE,
class_mode="categorical",
batch_size=BATCH_SIZE,
color_mode="grayscale",
)

为测试图像创建类似的生成器

为了说明目的,为单个图像创建一个生成器并显示相应的增强数据。
example_df = train_df.sample(n=1)
example_generator = train_datagen.flow_from_dataframe(
example_df,
DATASET_LOCATION,
x_col="filename",
y_col="category",
target_size=IMAGE_SIZE,
class_mode="categorical",
color_mode="grayscale",
)

绘制增强数据。
plt.figure(figsize=(12, 12))
for i in range(0, 15):
plt.subplot(5, 3, i + 1)
for X_batch, Y_batch in example_generator:
image = X_batch[0]
image = image.reshape(IMAGE_SIZE)
plt.imshow(image)
break
plt.tight_layout()
plt.show()
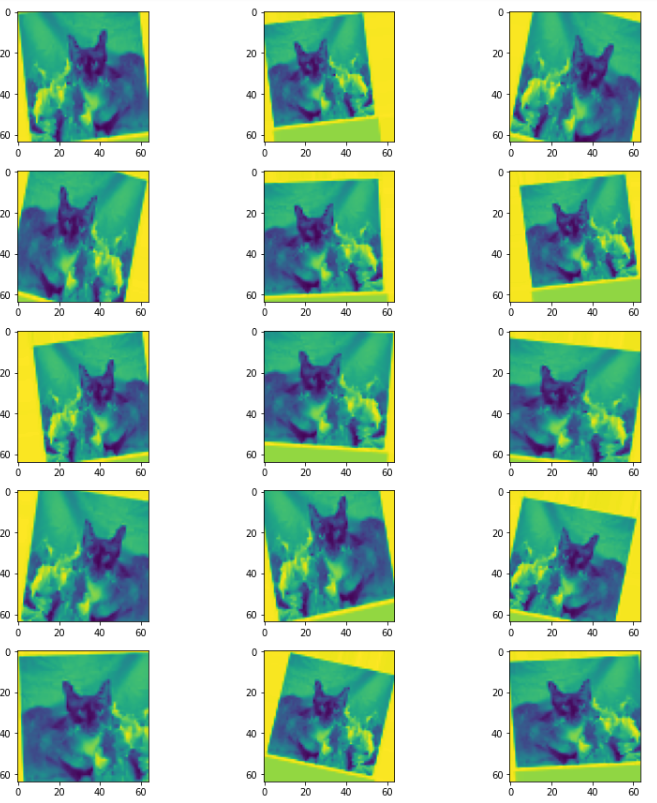
请注意,在整个过程中,您都对数据进行了灰度处理。这样做的目的是减少数据的大小,从而减少相应的计算负担。现在,您已经设置了训练管道的数据预处理部分。
使用 GPU 训练 CNN
如果您可以使用GPU,现在是时候启用它了。 GPU 可以加速大多数深度学习计算(即具有多层的神经网络的计算)。 如果您使用的是 Google Colab 笔记本,请点击运行时,然后点击<font style=
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!

















请先 登录后发表评论 ~