
探索 Python 库:PyTorch
介绍
深度学习是机器学习和人工智能领域最热门的话题之一。本指南将向您介绍 PyTorch,这是 Facebook 推出的一款热门深度学习库。PyTorch 与 Google 推出的 TensorFlow 并列。PyTorch 和 TensorFlow 都有一个共同的目标:使用神经网络训练机器学习模型。但 PyTorch 为深度学习提供了一个 Pythonic 接口,而 TensorFlow 则非常低级,需要用户了解很多有关神经网络内部的知识。最近,Keras 项目成为 TensorFlow 的一部分,PyTorch 中的一些便利功能也可供 TensorFlow 用户使用。然而,Keras 的级别甚至比 PyTorch 更高。对于许多用户来说,PyTorch 可能是灵活性和快速开发之间训练机器学习模型的理想折衷方案。
PyTorch 中的网络
PyTorch 中的神经网络是一个继承自torch.nn.Module的类。网络的层在类初始化器中声明。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
这是来自 PyTorch 示例,为 MNIST 示例数据集定义了一个简单的网络。请注意,这些层仅在初始化程序中创建和配置。它们之间的连接留给前向方法。此方法获取输入(图像数据),将其通过网络向前推进,并返回预测。
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# ...
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
# ...
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
为了简洁起见,省略了多余的行。但你可以看到变量x在通过网络时始终保持预测的当前状态。这也是激活函数的引入方式。
熟悉 Keras 的人可能会对完成此任务所需的代码量感到震惊。Keras 中的许多单行调用在 PyTorch 中需要多行代码。但同样,PyTorch 为您提供了 Keras 所不具备的控制级别。另一方面,如果您使用较低级别的 TensorFlow API,PyTorch 所需的代码比完成相同任务所需的代码要少。
在 PyTorch 中训练模型
在训练 PyTorch 模型之前,必须从torch.utils.data模块中的DataLoader加载数据集。
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST(...))
在使用神经网络训练模型时,利用 GPU 通常会有所帮助。必须在 PyTorch 中明确启用 GPU。
device = torch.device("cuda" if use_cuda else "cpu")
然后在创建新网络时使用该设备。
model = Net().to(device)
实际训练需要优化器。
optimizer = torch.optim.Adadelta(...)
然后迭代DataLoader并训练模型。
for _, (data, target) in enumerate(train_loader):
必须将数据和目标传输至 GPU设备。
data, target = data.to(device), target.to(device)
对于每次通过,优化器梯度都会被清零。
optimizer.zero_grad()
从模型接收到数据的预测。这是调用前向方法的地方。
output = model(data)
功能模块提供了损失函数的实现。损失函数将预测输出与预期目标值进行比较。
loss = F.nll_loss(output, target)
接下来是反向传播步骤。
loss.backward()
最后,优化器更新模型。
optimizer.step()
在多次遍历训练数据后,可以使用类似的方法测试模型,但无需计算梯度。一旦模型足够准确,保存它就很简单了。
torch.save(model.state_dict(), 'mnist.pt')
显然,这比 Keras 所需的代码要多得多。Keras 中的等效代码可能只有一行。但使用 PyTorch 还有其他优势。
PyTorch 张量
PyTorch 中的数据存储在Tensor中。
x = torch.tensor([[2, 3], [5, 7]])
从概念上讲,张量是一个具有一些新技巧的多维列表。在数据科学界,这些通常是用numpy创建的。PyTorch 相对于 TensorFlow 的一个优势是能够在tensor和numpy.array之间无缝移动。
np_array_x = x.numpy()
您还可以轻松地从numpy.array创建张量。
import numpy as np
y = np.random.randint(0, 10, size=(2, 3))
tensor_y = torch.from_numpy(y)
动态计算图
在深度学习中,计算图类似于流程图。图表的节点可以表示操作,例如数学函数或变量。
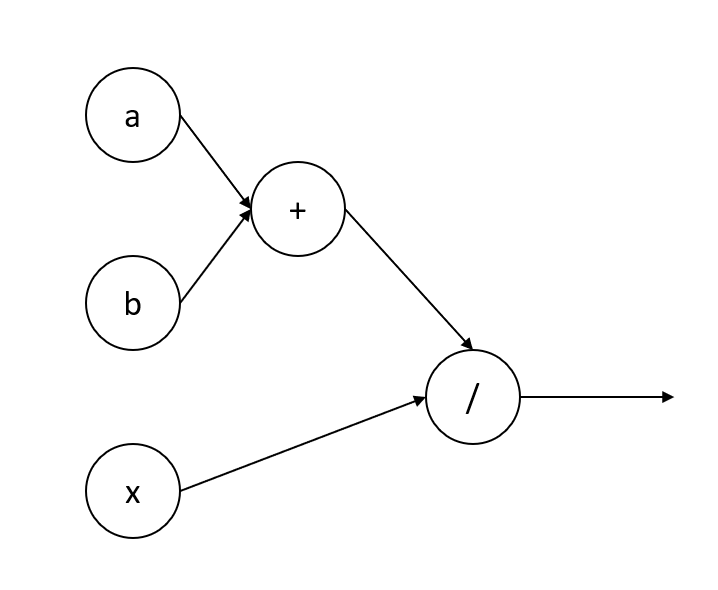
这里的计算图与函数(a + b) / x相同。在 PyTorch 中,计算图是在训练期间创建的。这样,图可以根据训练数据进行调整。静态计算图假设所有数据具有相同的大小和结构。传统上,TensorFlow 使用静态计算图。TensorFlow 2.0 添加了一些动态功能,但旧代码仍将使用静态图。
计算图由 PyTorch 中的autograd模块实现的自动微分技术创建。在网络的前向传播过程中,将创建计算图。这使得反向传播步骤成为一个简单的方法调用。可以通过在Tensor上调用方法require_grad_并传递True来开始跟踪,从而跟踪图中的操作。在训练期间调用后向方法时,将计算每个正在跟踪的操作的梯度。可以使用no_grad方法关闭整个图的跟踪以加快执行速度,例如在模型测试期间。
光网络
ONNX 是持久化机器学习模型的标准。PyTorch 支持将模型导出为 ONNX 格式。许多其他深度学习库(包括 TensorFlow)都可以导入 ONNX 模型。这样,您可以利用 PyTorch 中的训练模型功能,但在利用其他库的项目中使用这些模型。这对于迁移学习尤其重要。
TensorBoard
结论
PyTorch 非常适合那些不需要 TensorFlow 的复杂性,但需要比 Keras 更多的控制的项目。这并不意味着应该一直避免使用 Keras。研究和工业领域的专业人士都在使用 Keras。但 Keras 的假设并不适用于所有情况。PyTorch 允许您自定义神经网络以满足项目要求,同时仍可利用 Python 语言功能。谢谢阅读!
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~