
使用 Databricks 的分析解决方案
介绍
Databricks 是由 Apache Spark 提供支持的统一分析解决方案,它通过强大、协作且完全托管的机器学习平台简化了数据科学。主要分析解决方案包括以下内容:
协作数据科学:通过为数据科学和机器学习模型提供协作环境来简化和加速数据科学。
可靠的数据工程:针对批处理和流式工作负载的大规模数据处理。
生产机器学习:标准化从实验到生产的机器学习生命周期。
在本指南中,您将学习如何使用 Databricks 中的笔记本进行机器学习。以下部分将指导您完成使用 Databricks 构建机器学习模型的五个步骤。
第一步:登录Databricks
第一步是转到此链接并单击页面右上角的“尝试 Databricks” 。
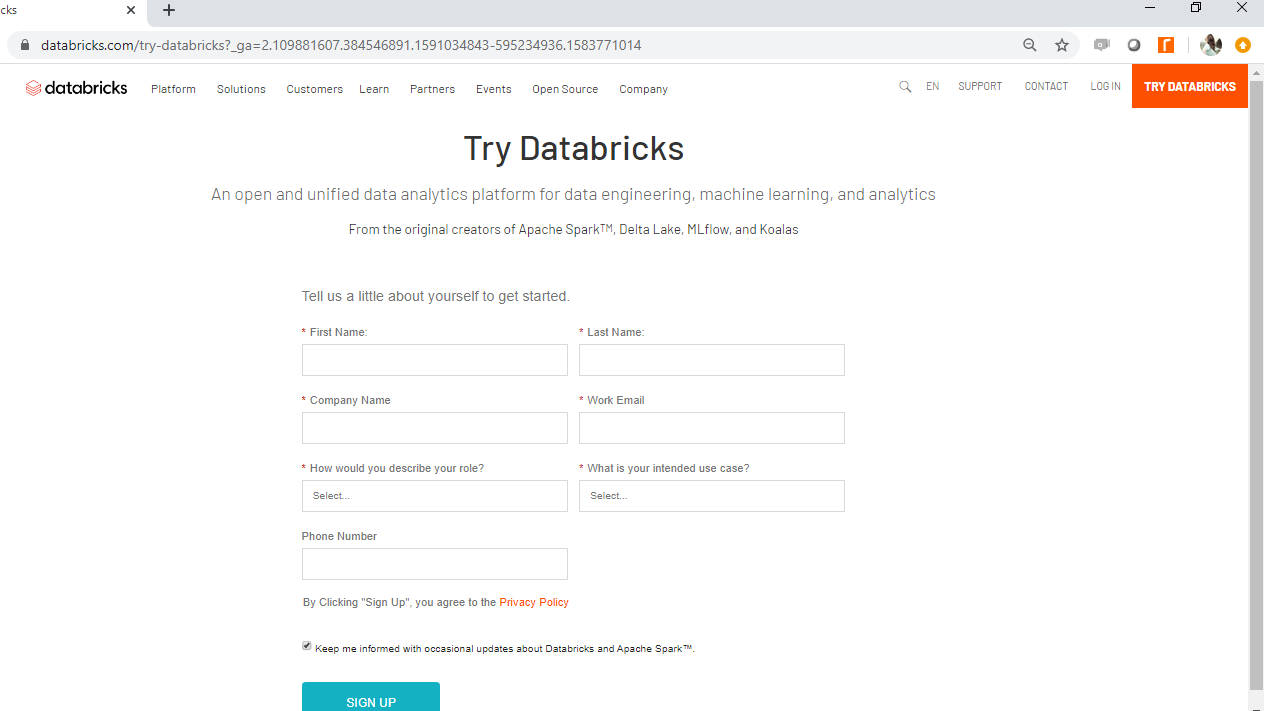
一旦您提供详细信息,它将带您进入以下页面。
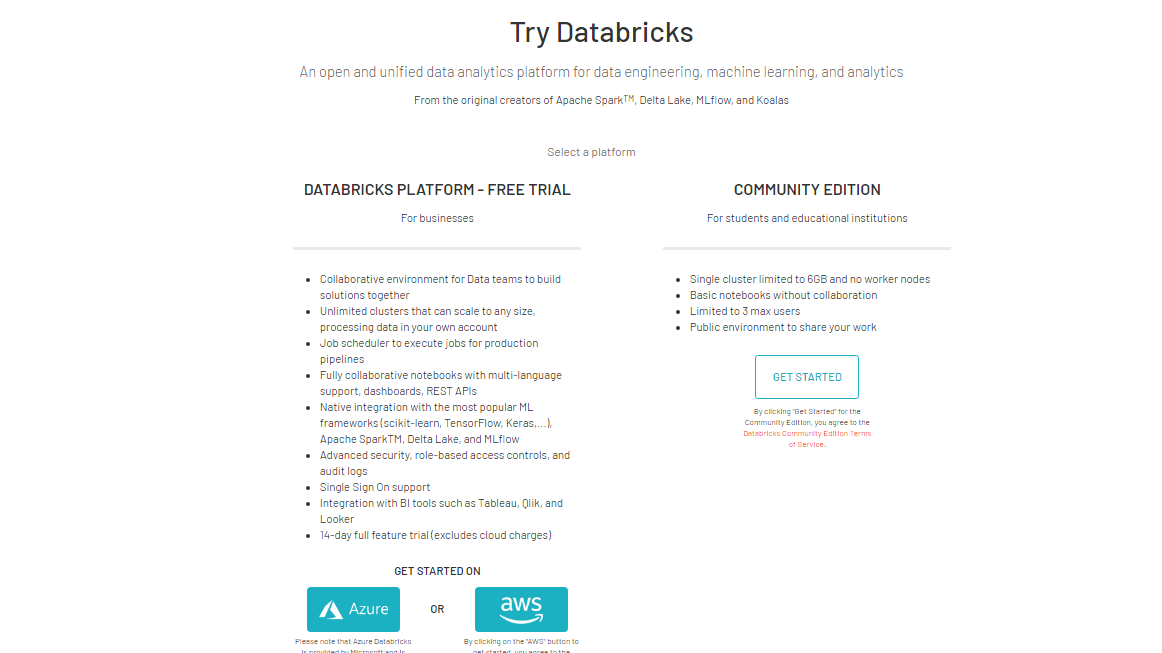
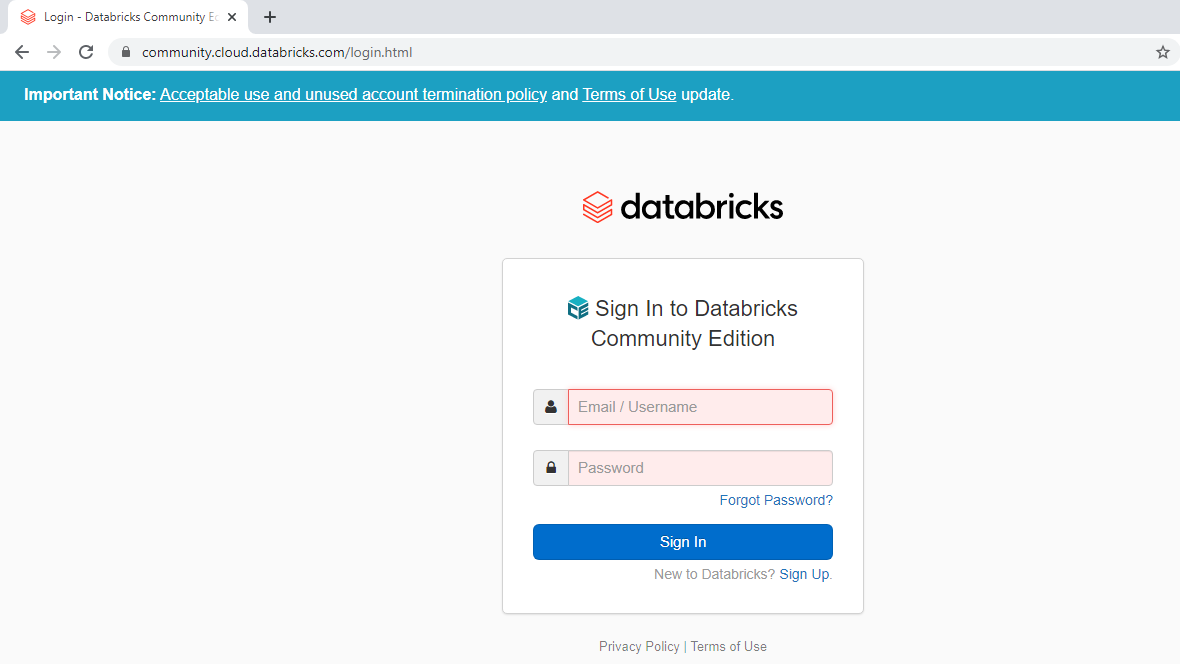
您可以选择 Azure 或 AWS 等云平台。本指南将使用 Databricks 的社区版。单击社区版选项下的“开始使用”选项卡并完成注册程序。这将使您的帐户准备就绪,之后您可以使用登录凭据登录帐户。
第二步:导入数据
登录您的账户后,您将看到以下 Databricks 页面。
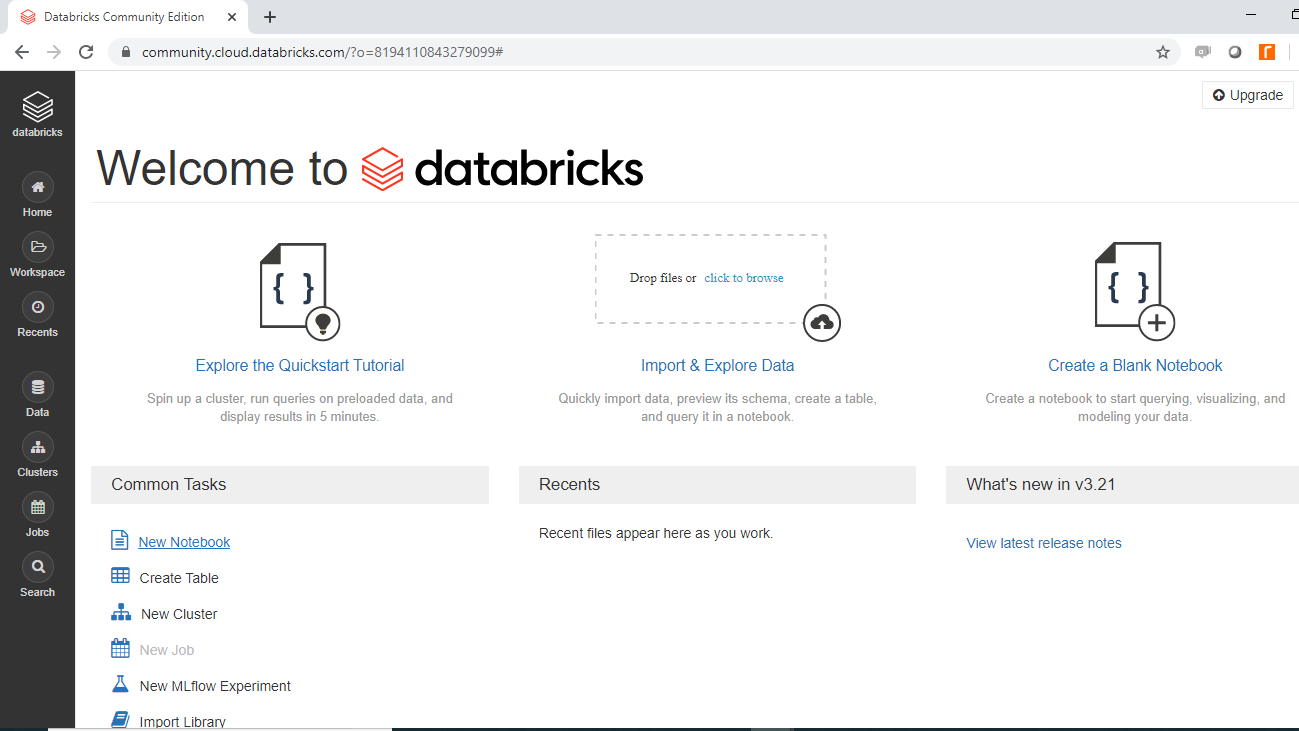
点击导入和浏览数据以导入数据。您将从本地系统上传数据文件Data_db.csv,一旦成功,将显示以下输出。
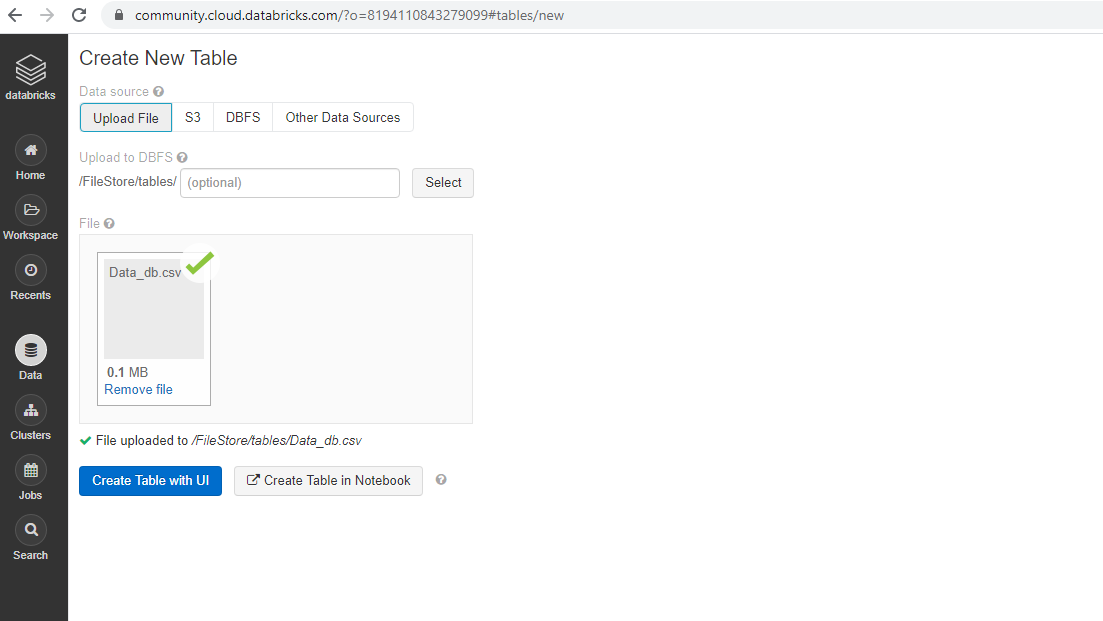
在上面的输出中,您可以看到文件的路径“文件已上传到 /FileStore/tables/Data_db.csv”。您稍后将使用此链接。
数据
本指南将使用一个虚构的贷款申请人数据集,其中包含 3000 个观测值和 7 个变量,如下所述:
收入:申请人的年收入(美元)
Loan_amount:提交申请的贷款金额(美元)
Credit_rating:申请人的信用评分是良好 ( 1 ) 还是不良 ( 0 )
Loan_approval:贷款申请是否被批准 ( 1 ) 或未批准 ( 0 )。这是目标变量。
年龄:申请人的年龄(岁)
Outstanding_debt:申请人之前贷款中当前未偿还的债务(以美元计)。
Interest_rate:银行向申请人收取的利率。
第三步:创建集群
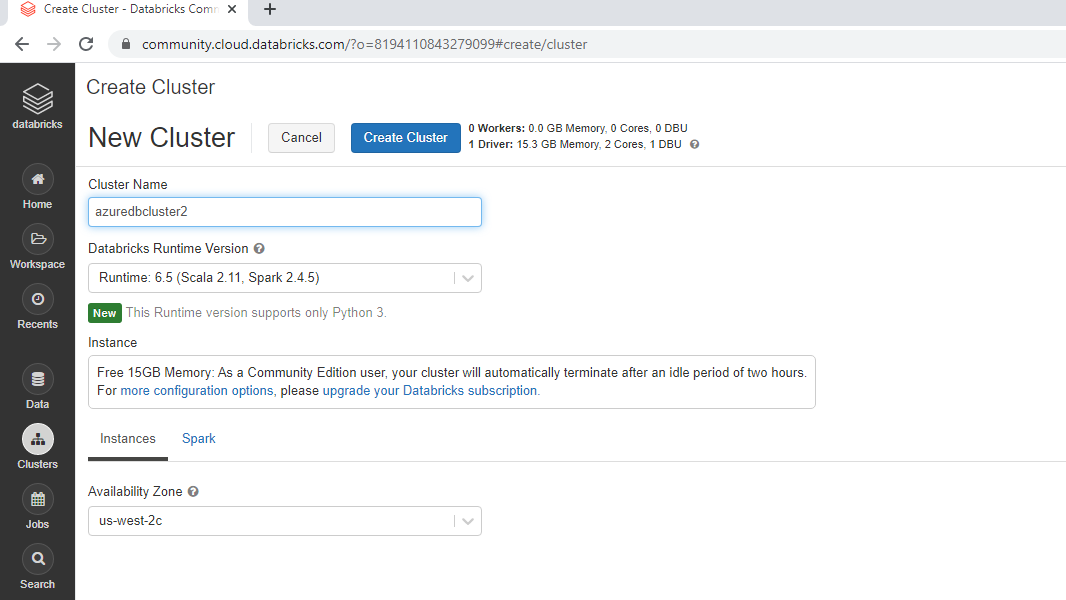
再次返回 Databricks 工作区并单击“常见任务”下的“新建集群”。
这将打开一个窗口,您可以在其中命名集群并将其余选项保留为默认值。单击“创建集群”以创建名为“azuredbcluster2”的集群。
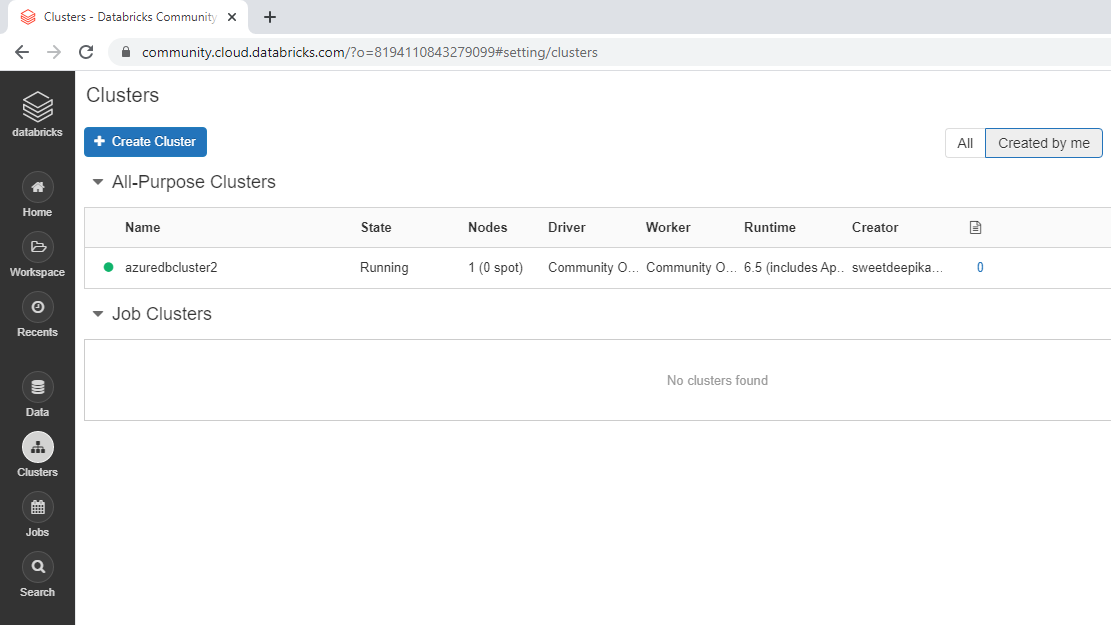
集群创建完成后会弹出如下界面,集群名称前面有绿色圆圈表示集群创建成功。
第四步:启动笔记本
再次返回欢迎页面并单击常见任务下的新建笔记本。
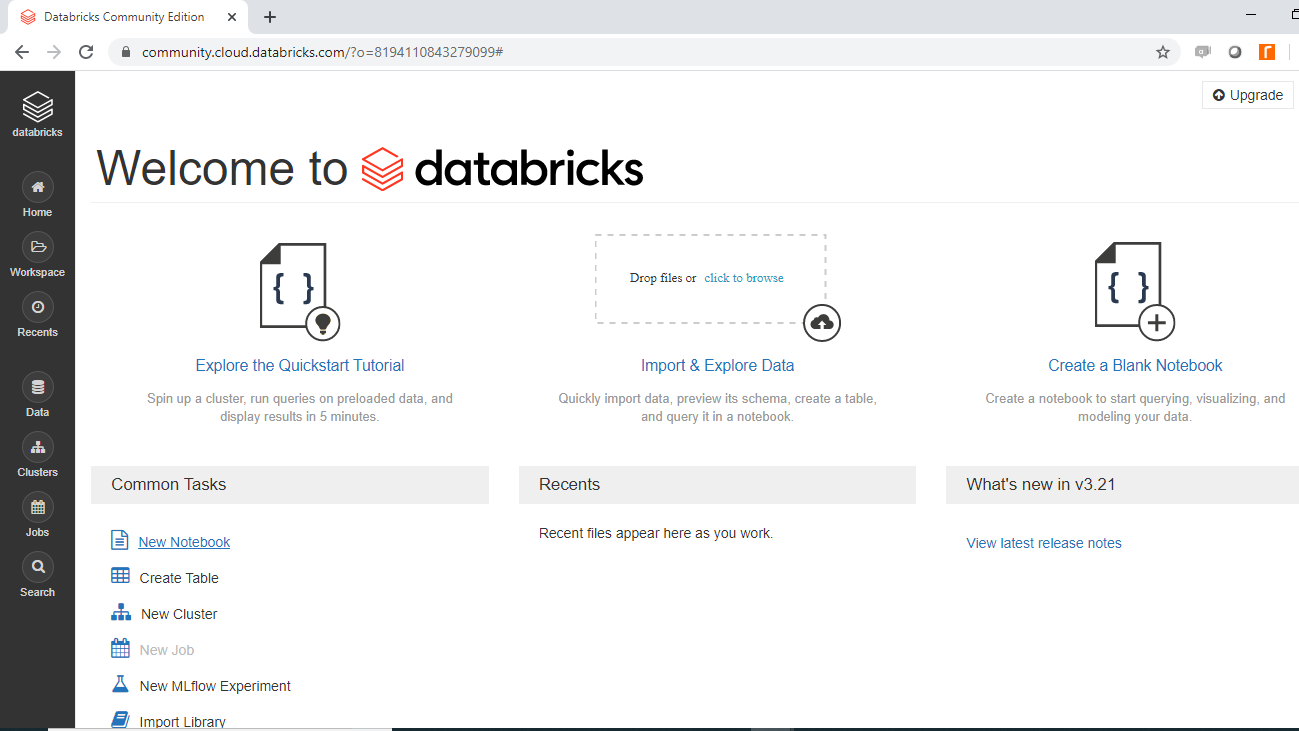
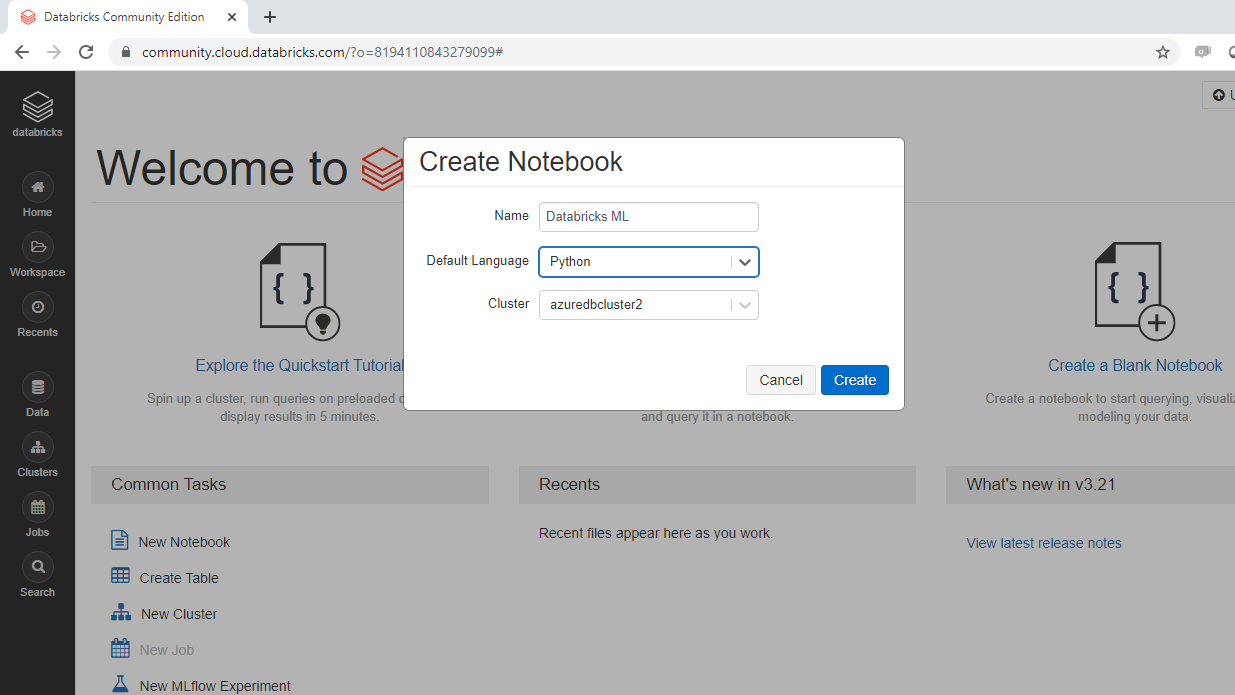
将打开以下弹出窗口,您可以填写所需的输入。在本例中,您将笔记本命名为“Databricks ML”。
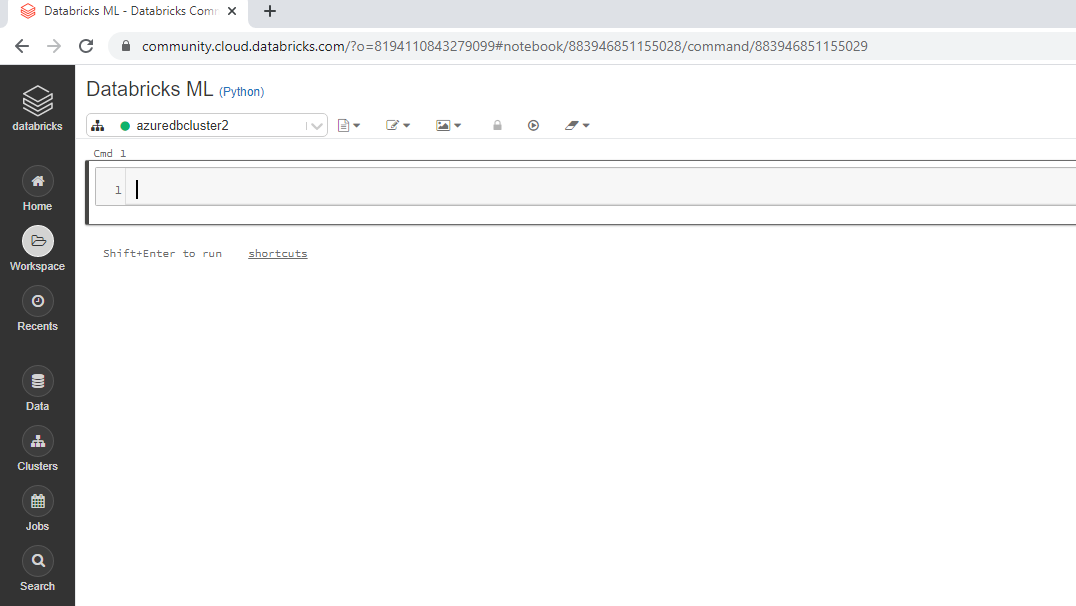
一旦创建笔记本,它将显示以下输出。
第五步:建立机器学习模型
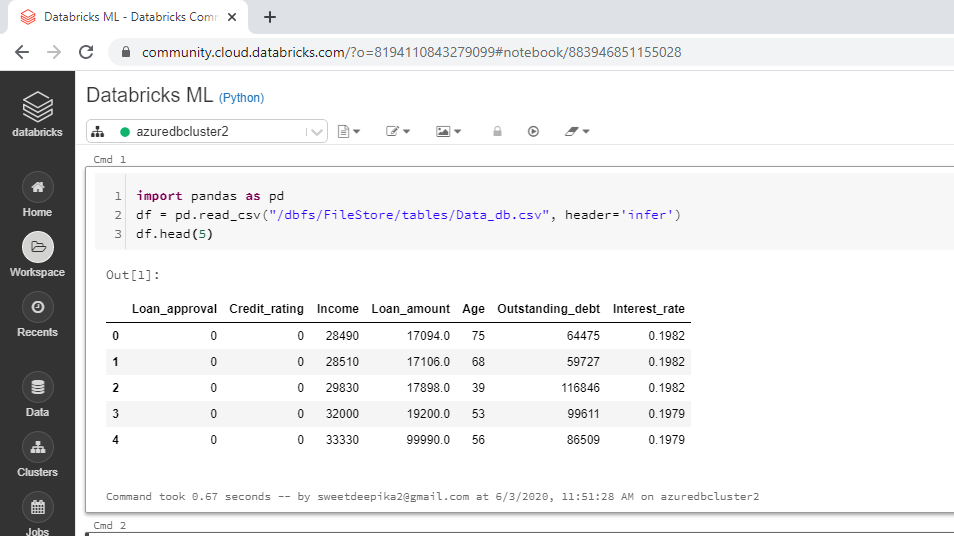
第一步是加载数据,可以使用下面的代码完成。
import pandas as pd
df = pd.read_csv("/dbfs/FileStore/tables/Data_db.csv", header='infer')
df.head(5)
笔记本视图与输出一起显示在下面。
下一步是加载其他所需的库和模块。
# Import other required libraries
import sklearn
import numpy as np
# Import necessary modules
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
另外,创建构建和评估机器学习模型所需的训练和测试数组。
# Create arrays for the features and the response variable
y = df['Loan_approval'].values
X = df.drop('Loan_approval', axis=1).values
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state=42)
X_train.shape, X_test.shape
笔记本视图与输出一起显示在下面。
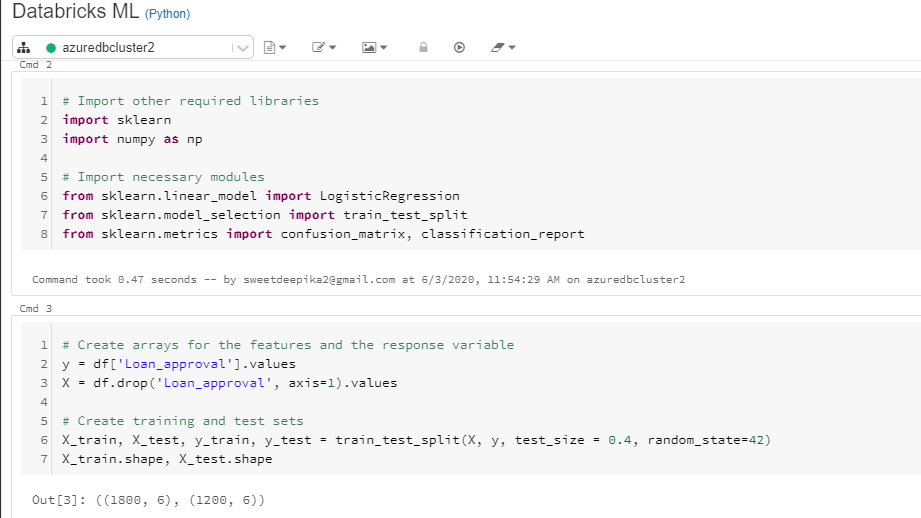
从上面的输出中,你可以看到训练数据中有 1800 个观测值,测试数据中有 1200 个观测值。
接下来,创建逻辑回归分类器logreg,并使分类器适合训练数据。
# Create the classifier: logreg
logreg = LogisticRegression()
# Fit the classifier to the training data
logreg.fit(X_train, y_train)
上述代码将生成下面的笔记本视图中显示的输出。
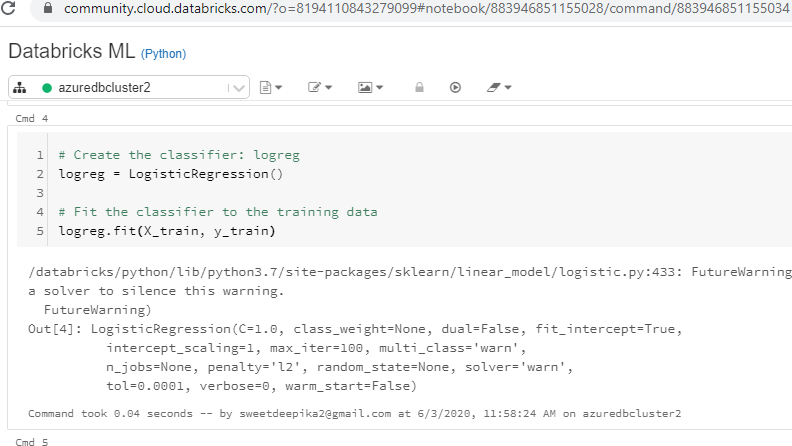
您已经训练了模型,下一步是根据测试数据进行预测并打印评估指标。这可以通过以下代码完成。
# Predict the labels of the test set: y_pred
y_pred = logreg.predict(X_test)
# Compute and print the confusion matrix and classification report
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
上述代码将生成下面的笔记本视图中显示的输出。
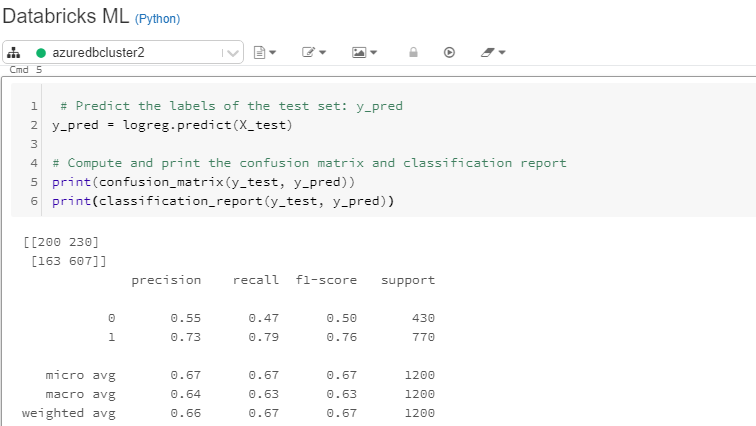
上面的输出显示模型准确率为 67.25%,敏感度为 79%。可以通过进行交叉验证、特征分析和特征工程,当然还可以尝试更高级的机器学习算法,进一步改进模型。要了解有关这些和其他 Python 技术的更多信息,请参阅指南末尾提供的链接。
结论
在本指南中,您了解了流行的统一分析平台 Databricks。您还学习了如何使用 Databricks 笔记本构建和评估机器学习模型。
要了解有关使用 Python 进行数据科学和机器学习的更多信息,请参阅以下指南。
<a href="https://www-pluralsight-com.translate.goog/resources/blog/guides/preparing-data-modeling-scikit-learn?_x_tr_sl=en&_x_tr_tl=zh-CN&_x_tr_hl=zh-CN&_x_tr_pt
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~