
Fork/Join 框架简介
介绍
硬件每天都在变得越来越快。
随着多核处理器和 GPU 使我们能够使用并行编程模型,并行计算平台和NVIDIA 的 CUDA等 API 的普及度不断上升。
在 Java 中,fork/join 框架通过将任务拆分为更小的任务并使用可用的 CPU 内核来处理它们,从而提供对并行编程的支持。
事实上,Java 8 的并行流和方法Arrays#parallelSort在底层使用 fork/join 框架来执行并行任务。
在本指南中,您将了解 fork/join 框架背后的概念和类、如何使用框架的内部类以及何时可以提高性能。
作为参考,您可以在此GitHub 存储库上找到该演示的源代码。
fork/join 框架如何工作?
并行是指同时执行两个或多个任务。
然而,由于并行性可以被认为是一种并发模型,它常常与并发本身的概念混淆。
并发是指在重叠的时间段内执行两个或多个不一定同时执行的任务。
有一篇博客文章介绍了并行性和并发性之间的差异,其中有基于Joe Armstrong 的绘画的精彩插图。
以下是我绘制的这些图画的动画版本:

并发:2 个队列,1 个自动售货机

并行:2 个队列、2 台自动售货机
这篇文章继续指出了这两个概念之间的区别,特别是在谈论事件处理系统(如在供应商机器示例中)和计算系统(展示送礼的示例)时。
就我们的目的而言,只要理解以下几点就足够了:在某些问题中,并发是问题的一部分;而在另一些问题中,并发不是问题的一部分,但诸如并行之类的东西可以成为解决方案的一部分(例如,通过加快处理时间)。然而,与此同时,并行本身也会带来问题。
fork/join框架旨在加速可分为其他较小子任务的任务的执行,并行执行它们,然后将其结果合并为一个任务。
因此,子任务之间必须相互独立,操作必须无状态,这使得该框架并不是解决所有问题的最佳方案。
框架采用分而治之的原则,将任务递归地划分为更小的子任务,直到达到给定的阈值。这是分叉部分。
然后,各个子任务被独立处理,如果它们返回结果,则所有结果将递归组合成单个结果。这是连接部分。
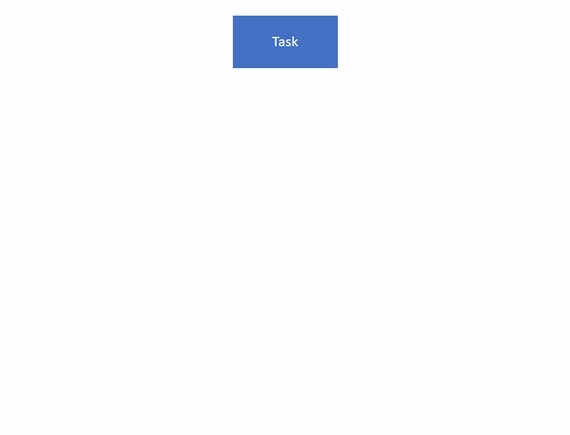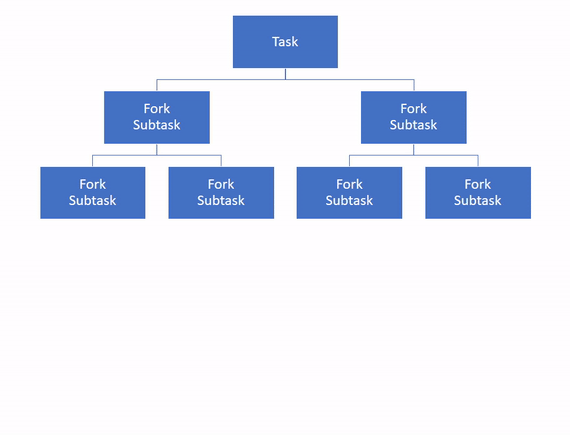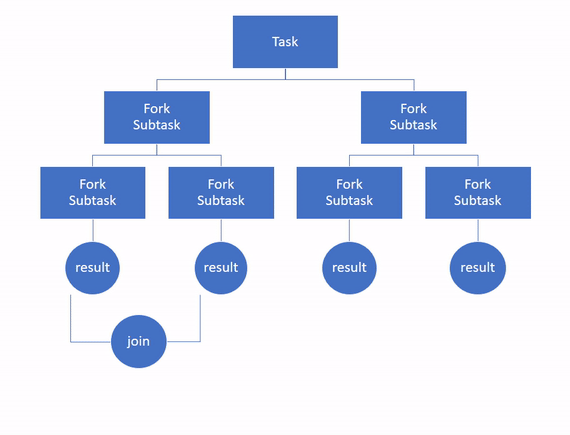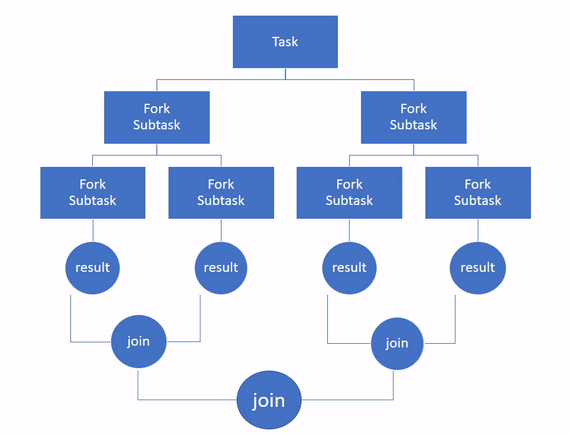
为了并行执行任务,该框架使用线程池,默认情况下线程数等于 Java 虚拟机 (JVM) 可用的处理器数。
每个线程都有自己的双端队列(deque)来存储将要执行的任务。
双端队列是一种支持从前端(头)或后端(尾)添加或删除元素的队列。这允许两件事:
- 一个线程每次只能执行一个任务(位于其双端队列头部的任务)。
- 实施工作窃取算法来平衡线程的工作量。
使用工作窃取算法,没有任务可处理的线程可以从其他仍然繁忙的线程中窃取任务(通过从其双端队列尾部删除任务)。
当需要处理多项任务或一项任务分为多项子任务时,这种方法可以通过增加吞吐量来提高处理效率。
了解框架类
fork/join 框架有两个主要类,ForkJoinPool和ForkJoinTask。
ForkJoinPool是ExecutorService接口的一个实现。一般来说,执行器提供了一种比普通线程更简单的方法来管理并发任务。此实现的主要特点是前面提到的工作窃取算法。
所有应用程序都可以使用一个通用的ForkJoinPool实例,您可以使用静态方法commonPool()获取它:
ForkJoinPool commonPool = ForkJoinPool.commonPool();
任何未明确提交给特定池的任务(如并行流使用的池)都会使用公共池。根据类文档,使用公共池通常可以减少资源使用量,因为其线程在未使用期间会缓慢回收,并在后续使用时恢复。
您还可以使用以下构造函数之一创建自己的ForkJoinPool实例:
ForkJoinPool()
ForkJoinPool(int parallelism)
ForkJoinPool(int parallelism,
ForkJoinPool.ForkJoinWorkerThreadFactory factory,
Thread.UncaughtExceptionHandler handler,
boolean asyncMode
)
还有另一个构造函数,其中包含更多需要配置的参数,但大多数情况下,您会使用上述构造函数之一。
第一个版本是推荐的方法,因为它创建的实例的线程数等于方法Runtime.getRuntime().availableProcessors()返回的数量,并使用所有其他参数的默认值。
在其他版本中,您可以指定并行级别、用于创建新线程的工厂、由于执行任务时引发不可恢复的错误而终止的内部工作线程的处理程序,以及建议用于工作线程仅处理事件样式异步任务的应用程序的标志。
就像ExecutorService执行Runnable或Callable的实现一样,ForkJoinPool类调用ForkJoinTask类型的任务,您必须通过扩展其两个子类之一来实现它:
- RecursiveAction,表示不会产生返回值的任务,例如Runnable。
- RecursiveTask,表示产生返回值的任务,就像Callable一样。
这些类包含compute()方法,该方法将负责直接解决问题或通过并行执行任务。大多数情况下,此方法是根据以下伪代码实现的:
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
ForkJoinTask子类还包含以下方法:
首先,你必须决定问题何时足够小,可以直接解决。这充当基准情况。大任务被递归地分成较小的任务,直到达到基准情况。
每次划分任务时,都调用fork()方法将第一个子任务放入当前线程的双端队列中,然后对第二个子任务调用compute()方法进行递归处理。
最后,要获取第一个子任务的结果,您需要对第一个子任务调用join()方法。这应该是最后一步,因为join()将阻止下一个程序的处理,直到返回结果为止。
因此,调用方法的顺序很重要。如果您没有在join ()之前调用fork () ,则不会有任何结果可检索。如果您在compute( )之前调用join( ) ,则程序的执行方式将像在一个线程中执行一样,您将浪费时间。
如果遵循正确的顺序,当第二个子任务递归计算值时,第一个子任务可以被另一个线程窃取来处理它。这样,当最终调用join()时,结果已经准备好,或者您不必等待很长时间才能获得它。
您还可以调用方法invokeAll(ForkJoinTask<?>...tasks)以正确的顺序分叉和加入任务。
最后,要向线程池提交任务,可以使用execute(ForkJoinTask<?> task),如下所示:
forkJoinPool.execute(recursiveAction);
recursiveAction.join();
// Or
forkJoinPool.execute(recursiveTask);
Object result = recursiveTask.join();
或者,使用submit(ForkJoinTask task)方法(它与execute方法的唯一区别在于它返回已提交的任务):
forkJoinPool.execute(recursiveAction).join();
// Or if a value is returned
Object result = forkJoinPool.execute(recursiveTask).join();
但是,您通常会使用invoke(ForkJoinTask task)来执行给定的任务,并在完成后返回其结果:
forkJoinPool.invoke(recursiveAction);
// Or if a value is returned
Object result = forkJoinPool.invoke(recursiveTask);
现在让我们回顾一个例子来更好地掌握这个框架。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!

















请先 登录后发表评论 ~