
Redis 作为动态互连数据存储
介绍
“环境和记忆在人生中所有真正美味的食物中都扮演着重要的角色。”安东尼·波登,厨师
是的,我知道。他(安东尼)谈论的是餐饮,而我们谈论的是软件开发。但两者略有相似之处。有时,我们的数据在经过软件部分时会经过特定的转换,并根据非常特定的算法进行传递。这些数据的输出最终将成为我们的输出,或者说是“餐饮”。

每个计算步骤的输出可以是我们处理的最终输出,也可以是下一步处理的输入。
我们当前的处理步骤称为我们的状态。到目前为止我们计算的任何数据都是我们的状态数据。
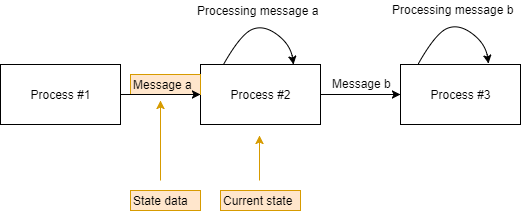
现在,状态数据可能会在当前处理状态下经过处理,每次使用不同的参数(即当前日期和时间、用户 ID)。这些参数称为上下文。消息包含其上下文或包含有关如何解析上下文的提示是很常见的。如果上下文在消息内部传递,则没有真正的“解析”步骤。
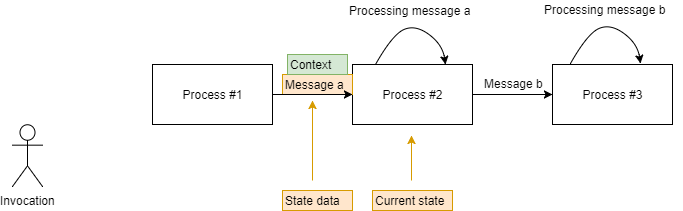
每个处理状态可能都需要访问传递给它的数据的上下文,以实现其设计目的。
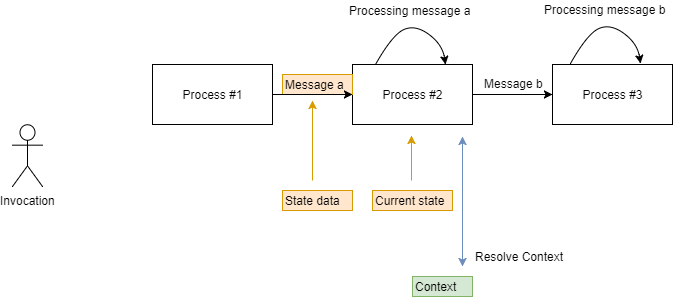
因此,上下文解析是正在运行的软件组件接收与其即将执行的计算相关的上下文的过程。
在一些常见情况下,例如 Web 应用程序,该上下文可能是每个用户建立的会话(当用户登录我们的系统时),或者它可以包含有关传递给我们的信息的任何元数据。
如今,使用软件系统的方式与几年前大不相同。各种软件组件可能会随着时间的推移改变我们的环境。这些组件需要访问共享资源,以便它们可以同时引用和使用(读取/写入)它们所需的环境。
Redis提供了这样的功能。
那么...什么是 Redis?
Redis 最初由 Salvatore Sanfilippo 创建,被命名为“Redis”以反映其最初的目的,即提供“远程字典服务器”。它最初于 2010 年在GitHub上发布,此后经历了许多新版本。
在本指南中,我将提供 Redis 的鸟瞰图,在我看来,它不仅仅是一个远程字典服务器。
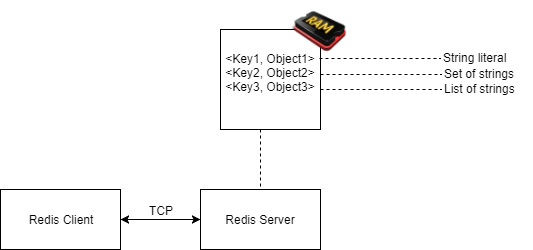
您(Redis 使用者)将在您的应用程序中托管Redis 客户端。该客户端会将向其发出的任何请求传达给Redis 服务器(或多个服务器,当部署为集群时)。此通信将通过简单而高效的协议(即TCP )进行。
我们传递给 Redis 的请求主要是<Key, Object>形式的 CRUD(创建、读取、更新、删除)操作,其中 Object 可以采用任何受支持的数据类型的形式,例如字符串、列表、有序列表或集合。
例如,为了演示,以下信息被持久化到 Redis 中(我使用托管在 docker 上的开源Redis commander 用户界面):
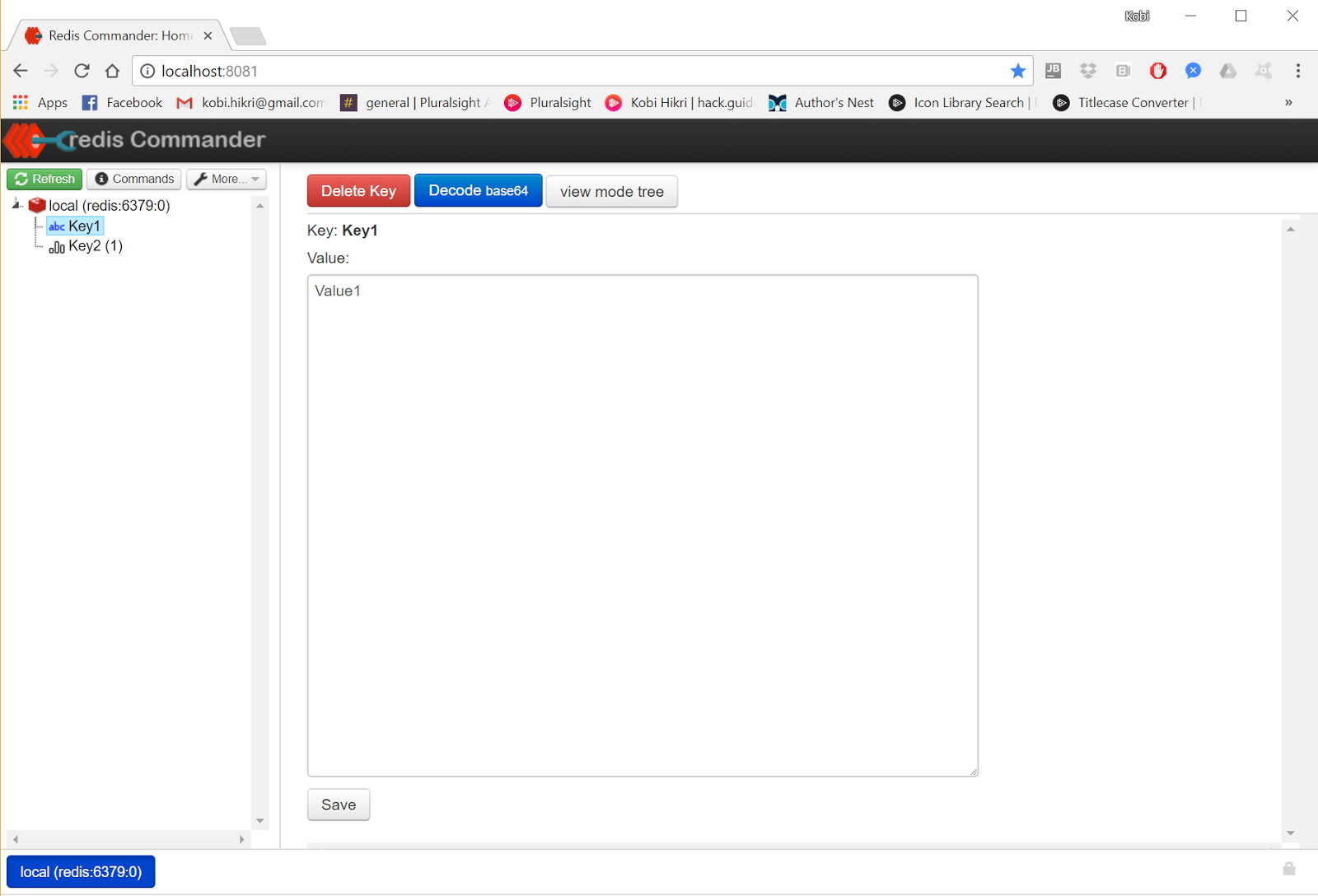
在上图中,您可以看到一个简单的键值对。下一个屏幕截图显示了与同一键关联的值列表。
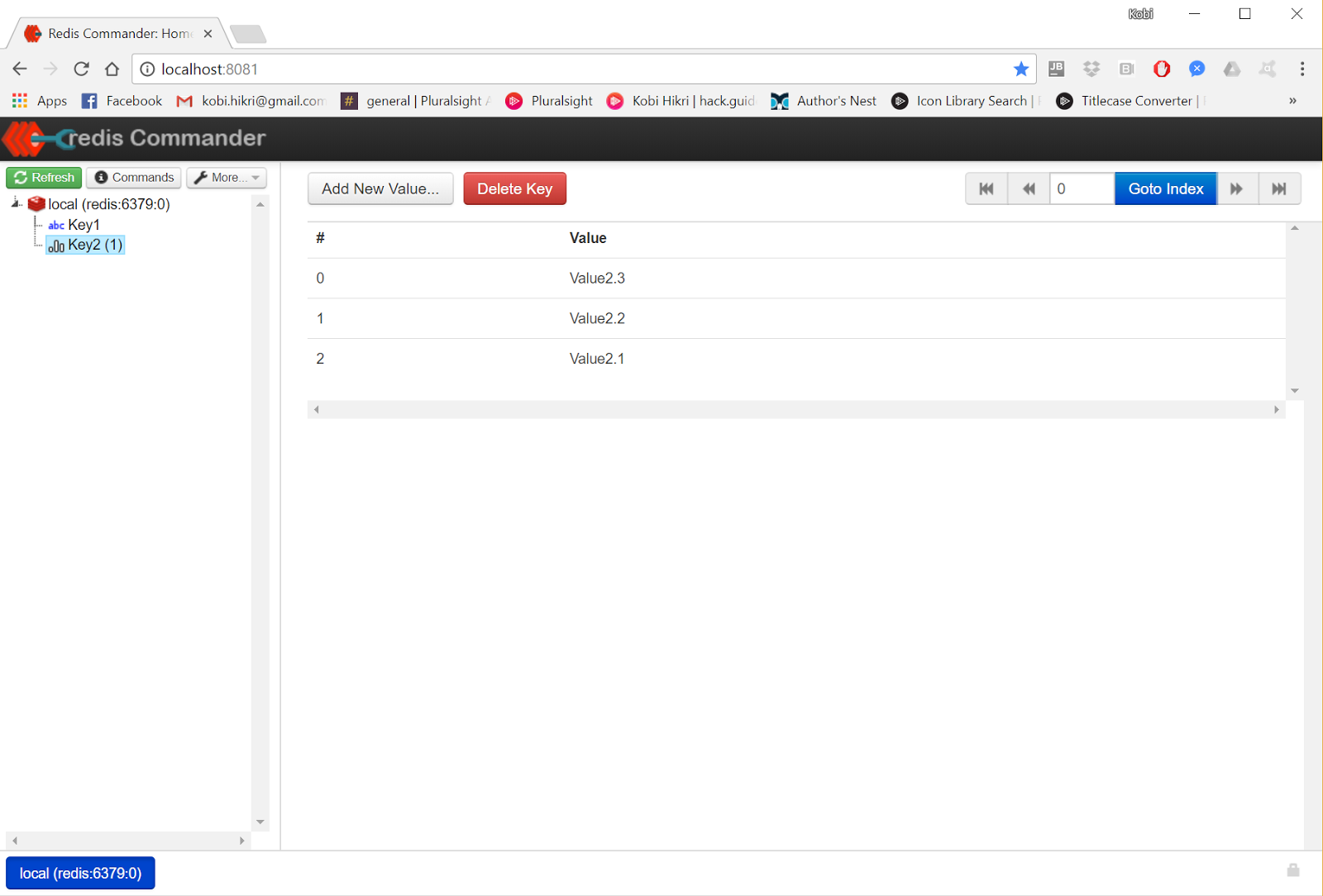
我们可以选择为存储在 Redis 中的任何键定义过期时间。此过期时间将精确到毫秒(版本 >= 2.6)。过期的键(及其值)一旦过期,就会自动被删除。
值得注意的是,Redis 作为集中式缓存/数据存储/同步数据提供程序的有趣之处在于它的速度非常快,主要是因为所有数据都保存在内存中。默认情况下,Redis 还会将所有数据保存到非易失性存储中,这是可以配置的设置,它还支持复制和高可用性——尽管本文不会深入讨论这些功能。
让我们观察一些用例并查看一些代码以更好地理解这项技术。
使用 Redis 作为同步缓存机制
Redis 通常用作分布式缓存。我们的应用程序中有多个进程,因此 Redis 可以作为所有进程(可选地跨多台机器)的“中心参考点”。
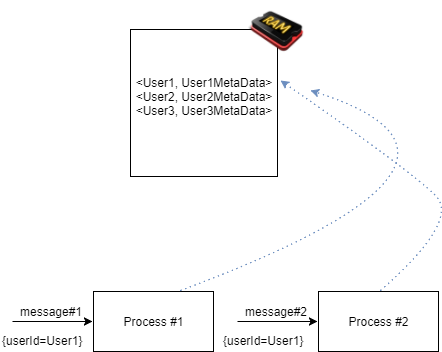
拥有系统数据的集中、单一表示使我们能够安全地实现我们的逻辑,“知道”在每个输入消息的任何给定时间点,“查看”特定信息(例如上下文)的所有进程都将“看到”相同的信息。
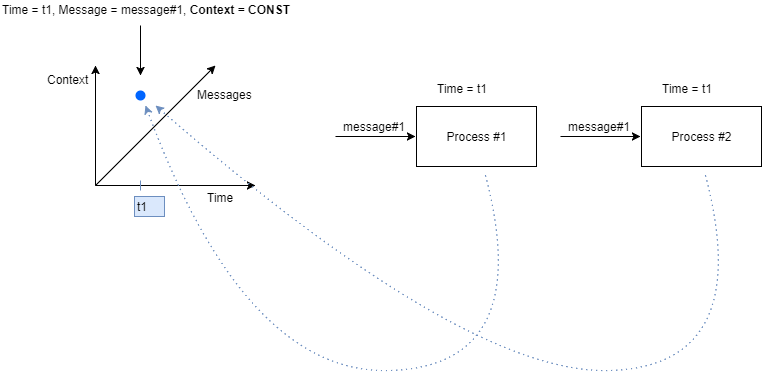
在上图中,我们可以看到两个进程同时接收到输入消息 #1。两个进程都从 Redis 请求消息上下文,并将接收完全相同的上下文!
还可能出现不同的情况。可能的情况是,一个进程的输出是另一个进程的输入。在这种情况下,时间t1和t2将不同(t2 > t1),从而导致每个进程的上下文可能不同。
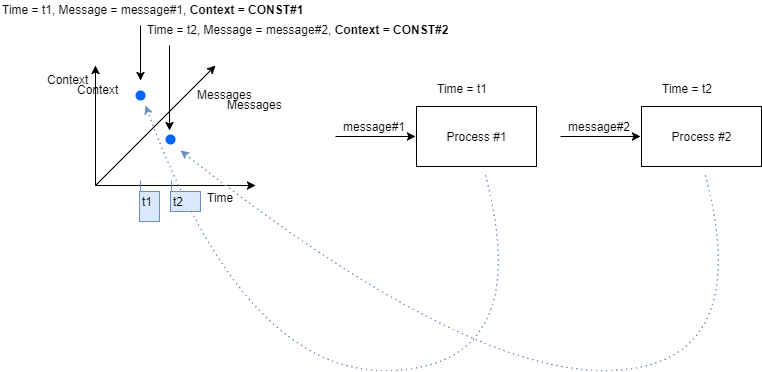
例如,假设我们的计算从用户登录系统开始。在用户执行任何其他操作之前,我们已经“知道”有关该用户的一些信息(即姓名、登录位置和系统中的历史活动)。
其中一些信息可能会在我们的计算中使用,可能由不同的进程(托管在不同的机器上)使用。
在这种情况下,我们可能会明智地将上下文信息缓存在内存中,并将其快速提供给任何消费进程。
这确实很有帮助。只要我们能确保我们的数据正确同步即可。
还记得在给定时间点上我们的上下文只有一个表示吗?好吧,看来,在处理并发系统时,确保这一点并不是一件简单的任务。多个进程可能同时访问相同的数据。有些进程可能会尝试修改它。
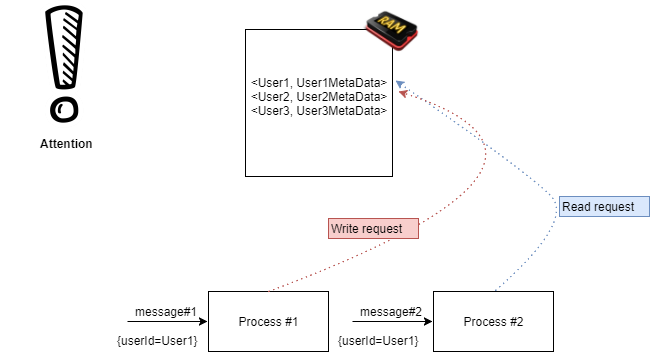
让我们看看 Redis 如何帮助我们处理并发数据消费。
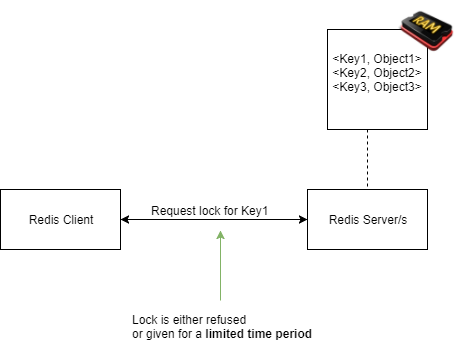
您可以使用的分布式锁定机制
Redis 支持并提倡使用Redlock 算法,以实现资源的分布式锁定。该算法很有趣,因为它为锁定概念提供了一种无死锁的方法。
现在,如果您学习过计算机科学,您可能知道,在您的应用程序中出现关键部分 - 在我们的例子中,即访问我们锁定数据的代码 - 本质上存在死锁的可能性。
那么 Redis 团队如何声称他们的方法没有死锁呢?
因为“无死锁”这个概念是指整体上获取锁和释放锁的过程。
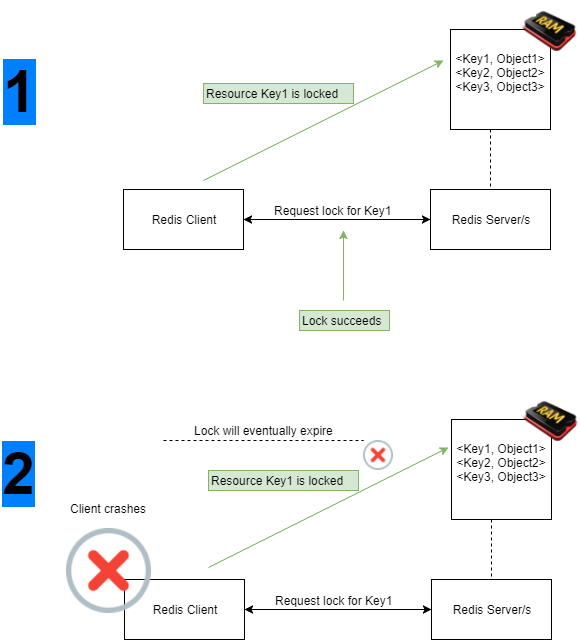
确实,如果特定客户端获得了锁,那么尝试使用该数据的其他客户端就会被阻止。
但是,使用 Redlock 算法,可以保证该锁最终被释放,从而使算法不会出现死锁。
每个成功的锁定操作都有一个超时时间,即使锁定客户端崩溃而没有正常释放锁定的资源,该超时时间也会到期。
上下文交互实现示例
下面是一些 Python 示例代码,演示了一个进程如何写入上下文,而另一个进程如何尝试从上下文中读取:
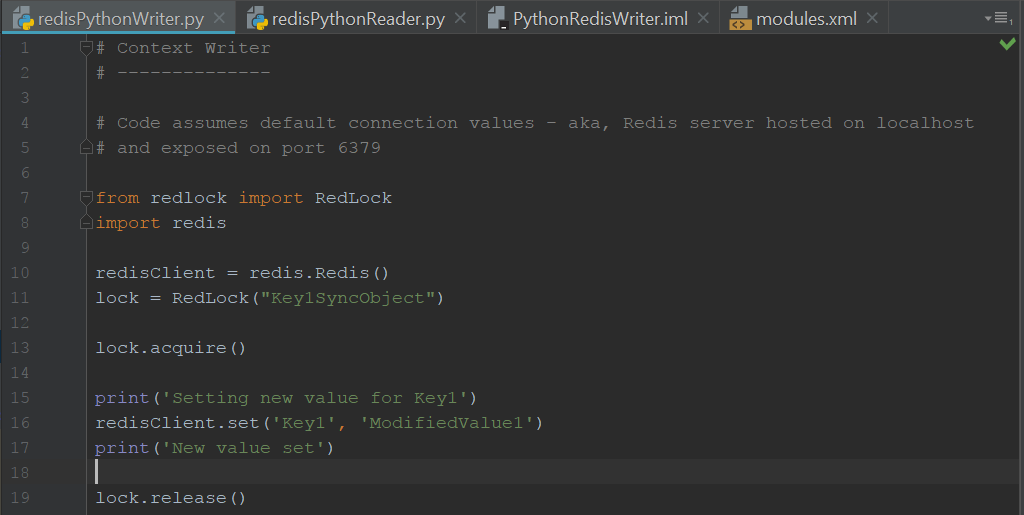
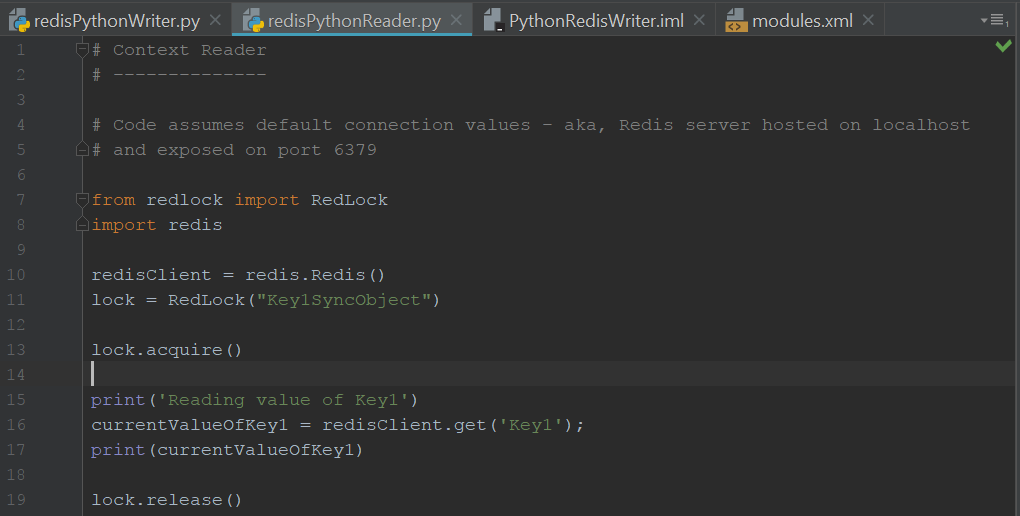
很简单,对吧?
请注意,我们获取锁的请求可能会在特定时间点被拒绝。然后,请求锁的客户端有责任执行重试。
一些 Redlock 实现嵌入了重试机制:
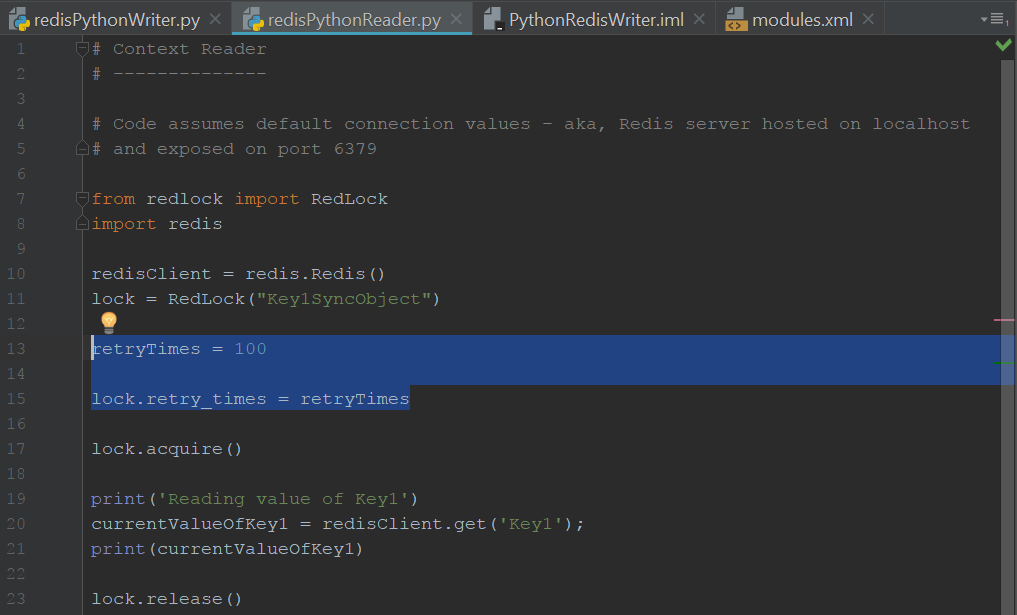
太棒了。现在我们已经学会了如何在并发消费者尝试访问或修改分布式缓存时安全地访问它。
现在让我们看一下另一个有趣的 Redis 用例。
使用 Redis 进行进程间通信
假设我们希望我们的进程与“外部世界”进行通信。我们需要访问进程间通信机制。
Redis已经内置了非常简单且高效的发布者/订阅者进程间通信抽象。
通过这种抽象,我们可以将我们的流程与关于“谁”生产或消费任何特定消息的任何知识分离。
那么,进程只负责处理到达其“门”的消息。
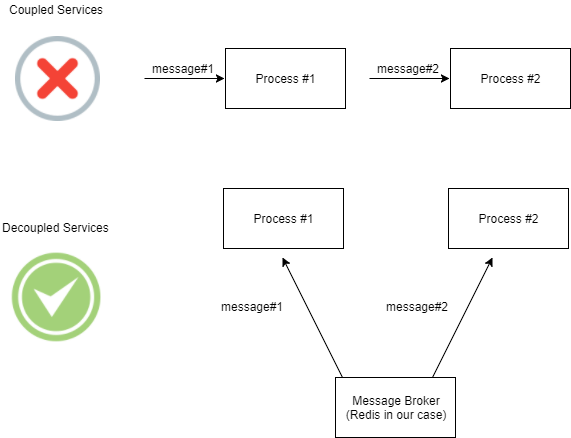
让我们看看如何使用 Redis 实现这种机制。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~