

探索 Python 库:HTTPX
介绍
在 URL 中传递数据
假设您想从 Yahoo! 财经网站获取某公司的股票统计数据。关联的 URL 将是https://finance.yahoo.com/quote/ABXY/key-statistics?p=ABXY,其中“ABXY”是该公司的注册缩写。请注意,URL 由一个键值对组成,其中键为“p”,值为“ABXY”。因此,如果您想获取另一家公司的股票统计数据,只需将“ABXY”替换为您所需公司的注册缩写即可。
要实际学习这个概念,您可以获取 PS (NASDAQ: Pluralsight) 的股票统计数据。首先创建一个字典,如下所示:
eq = {'p': 'PS'}
最后,使用httpx.get方法并提供包含eq变量的完整 URL :
r = httpx.get('https://finance.yahoo.com/quote/'+eq['p']+'/key-statistics', params=eq)
您可以使用url属性查看结果 URL,如下所示:
print(r.url)
# https://finance.yahoo.com/quote/PS/key-statistics?p=PS
设置自定义标头
如果您想让客户端和服务器通过 HTTP 请求传递其他数据,可以使用 HTTPX 库设置自定义 HTTP 标头。例如,考虑 YouTube,其标头可以按如下所示提取:
url = 'https://youtube.com'
r = httpx.get(url)
print(r.headers)
上述代码的结果是以下 YouTube 标题:
Headers([('x-frame-options', 'SAMEORIGIN'), ('strict-transport-security', 'max-age=31536000'), ('expires', 'Tue, 27 Apr 1971 19:44:06 GMT'), ('x-content-type-options', 'nosniff'), ('content-encoding', 'gzip'), ('p3p', 'CP="This is not a P3P policy! See http://support.google.com/accounts/answer/151657?hl=en-GB for more info."'), ('content-type', 'text/html; charset=utf-8'), ('cache-control', 'no-cache'), ('date', 'Sat, 27 Jun 2020 07:17:08 GMT'), ('server', 'YouTube Frontend Proxy'), ('x-xss-protection', '0'), ('set-cookie', 'YSC=QxCnrEi_49U; path=/; domain=.youtube.com; secure; httponly; samesite=None'), ('set-cookie', 'VISITOR_INFO1_LIVE=L4qLJ2-3U18; path=/; domain=.youtube.com; secure; expires=Thu, 24-Dec-2020 07:17:08 GMT; httponly; samesite=None'), ('set-cookie', 'GPS=1; path=/; domain=.youtube.com; expires=Sat, 27-Jun-2020 07:47:08 GMT'), ('alt-svc', 'h3-27=":443"; ma=2592000,h3-25=":443"; ma=2592000,h3-T050=":443"; ma=2592000,h3-Q050=":443"; ma=2592000,h3-Q046=":443"; ma=2592000,h3-Q043=":443"; ma=2592000,quic=":443"; ma=2592000; v="46,43"'), ('transfer-encoding', 'chunked')])
注意,内容编码标头的默认值是gzip。如果你想使用其他替代方案(例如br ) ,该怎么办?
要更新标题的值,请将新值存储在字典中,并将字典传递给get方法的headers参数,如下所示:
headers = {'accept-encoding': 'br'}
print(httpx.get(url, headers=headers).headers) # The updated content encoding is br
更新后的标题如下所示:
Headers([
...
('content-encoding', 'br'),
...
访问不同形式的数据
您可以使用 HTTPX 库来获取文本、图像和 JSON 数据。在本节中,您将学习如何获取大小不一的文本和图像数据。对于较大的数据,您可以执行流式传输,本节将进一步解释这一点。
1. 获取文本数据
假设您想从包含不超过 5-10 行文本的网页中获取 HTML 格式的数据,如图所示:
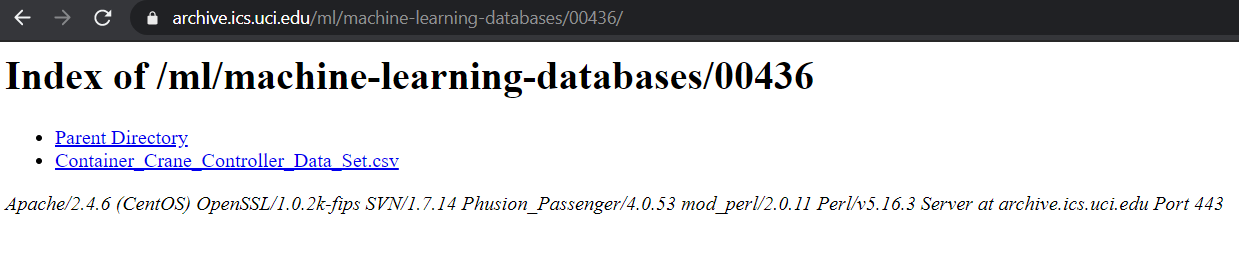
资料来源:Dua, D. 和 Graff, C. (2019)。UCI 机器学习存储库。加利福尼亚州欧文市:加利福尼亚大学信息与计算机科学学院。
为此,请在httpx.get方法内传递 URL,然后使用文本属性,如下所示:
# https://archive.ics.uci.edu/ml/datasets/Container+Crane+Controller+Data+Set
fetch = httpx.get('https://archive.ics.uci.edu/ml/machine-learning-databases/00436/')
print(fetch.text)
输出:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<html>
<head>
<title>Index of /ml/machine-learning-databases/00436</title>
</head>
<body>
<h1>Index of /ml/machine-learning-databases/00436</h1>
<ul><li><a href="/ml/machine-learning-databases/"> Parent Directory</a></li>
<li><a href="Container_Crane_Controller_Data_Set.csv"> Container_Crane_Controller_Data_Set.csv</a></li>
</ul>
<address>Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips SVN/1.7.14 Phusion_Passenger/4.0.53 mod_perl/2.0.11 Perl/v5.16.3 Server at archive.ics.uci.edu Port 443</address>
</body></html>
2. 流式文本数据
要获取大量文本数据,您可以执行流式传输,即一次获取有限量的数据,直到到达页面末尾。为了理解这个主题,假设您想从 Wikipedia 页面中提取有关捉鬼敢死队的所有文本数据。为此,您可以在嵌套在httpx.stream方法中的for循环内逐行获取数据,如下所示:
with httpx.stream("GET", "https://en.wikipedia.org/wiki/Ghostbusters") as r:
count = 0
for line in r.iter_lines():
# print(line)
count += 1
print(count)
# 1166
在上面的代码中,print(line)语句被注释掉了。您可以取消注释并观察其输出流。最后一行print(count)描述了流期间提取的总行数 (1166)。
3.获取图像数据
获取图像数据的过程与获取文本数据的过程类似。但是,唯一的区别在于在 Python 环境中获取数据后如何读取它。假设您需要从 Pixabay 网站获取企鹅图像。为此,请在 httpx.get 方法中传递图像 URL ,然后使用PIL和io方法读取和显示数据,如下所示:
from PIL import Image
from io import BytesIO
# https://pixabay.com/photos/penguin-figure-christmas-santa-hat-1843544/
g = httpx.get('https://cdn.pixabay.com/photo/2016/11/20/19/02/penguin-1843544_1280.jpg')
Image.open(BytesIO(g.content)).show()

4. 流图像数据
您可以使用httpx.stream方法来获取大型图像数据。与流式传输文本数据的唯一区别是,这次for循环会遍历iter_bytes,如下所示:
with httpx.stream("GET", "https://cdn.pixabay.com/photo/2016/11/20/19/02/penguin-1843544_1280.jpg") as r:
for data in r.iter_bytes():
print(data)
发布不同形式的数据
HTTPX 可用于在网页上的表单内发布数据。在本节中,您将了解如何将文本和文件数据上传到网页。
1. 上传文本数据
假设您想使用 HTTPX 在网页上输入“Hello, World!”。输入区域将如下所示,颜色为绿色:
为此,请使用post方法并提供数据参数中的信息,如下所示:
data = {'htmlString': 'Hello, World!'}
# Locate a correct node, for me it is "htmlString"
r = httpx.post("<URL>", data=data)
print(str(r.content).replace('\\n','').replace('\\t','').replace('\\r',''))
上述代码生成 HTML 输出。由于输出太大,下面给出的是格式正确的网页,其中所需框中包含“Hello, World!”字符串:

2.上传文件
很多网站都需要你上传文件到他们的服务器。下面就是一个绿色方框中突出显示的例子:
要上传完整文件而不是仅仅编写字符串,您可以使用post方法的files参数。假设您的驱动器上存储了一个 HTML 文件upload.html。您可以使用给定的代码将其上传到此网页:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!




































请先 登录后发表评论 ~