
探索 Python 库:Imbalanced-learn
介绍
作为处理现实世界数据的数据科学家,在您的职业生涯中,您将面临构建不平衡数据机器学习模型的挑战。您需要对许多问题做出明智的决策,从选择正确的指标到确保您的模型在小类上得到充分的训练。为了帮助您克服这些挑战,构建一个准确且信息丰富的模型,本指南将向您介绍不平衡学习库并向您展示其最受欢迎的三个用例。
不平衡学习库概述
解决不平衡数据最有前景的方法之一是使用重采样技术。方便的是,Python 不平衡学习库提供了大量重采样技术和实现,包括最有用的三种:SMOTE、ADASYN和平衡随机森林。
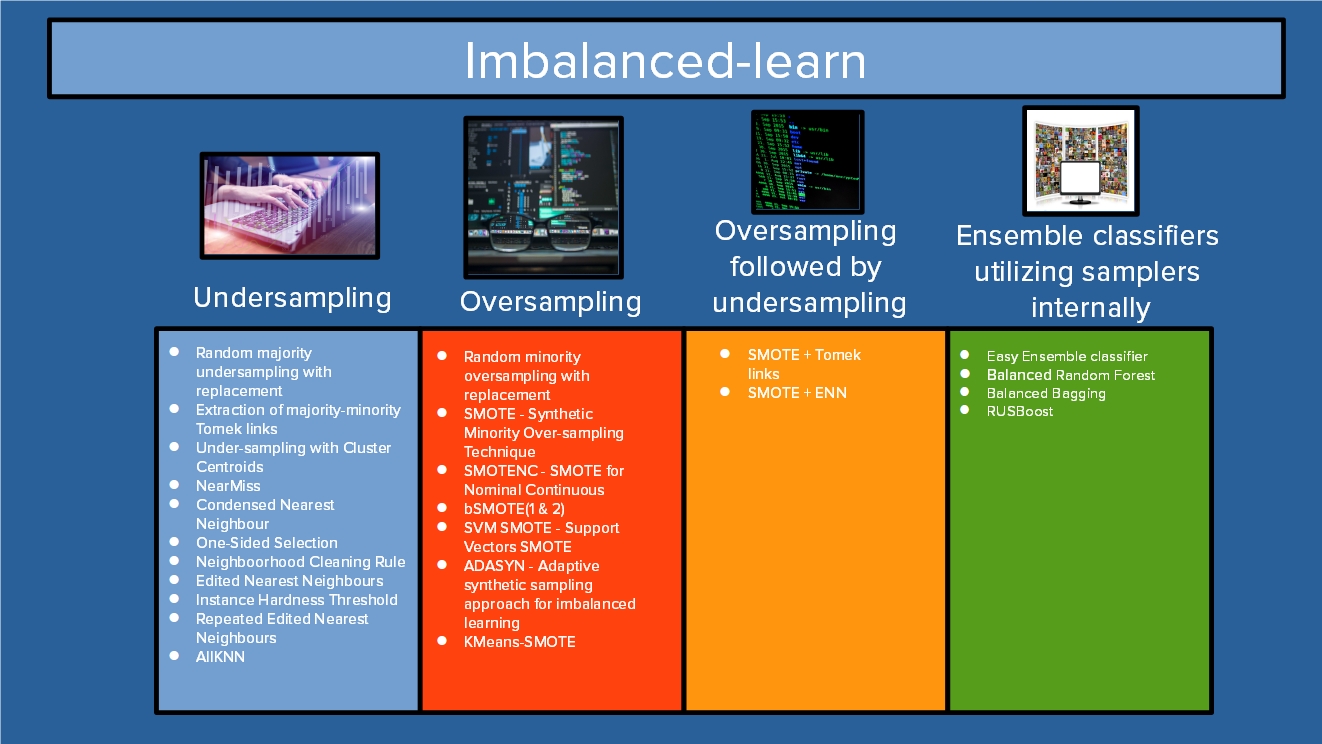
开始使用 irreparabled-learn 并不困难,即使对于职业生涯头几年的数据科学家来说,该软件包也很容易理解。
安装
只需运行:
pip install -U imbalanced-learn
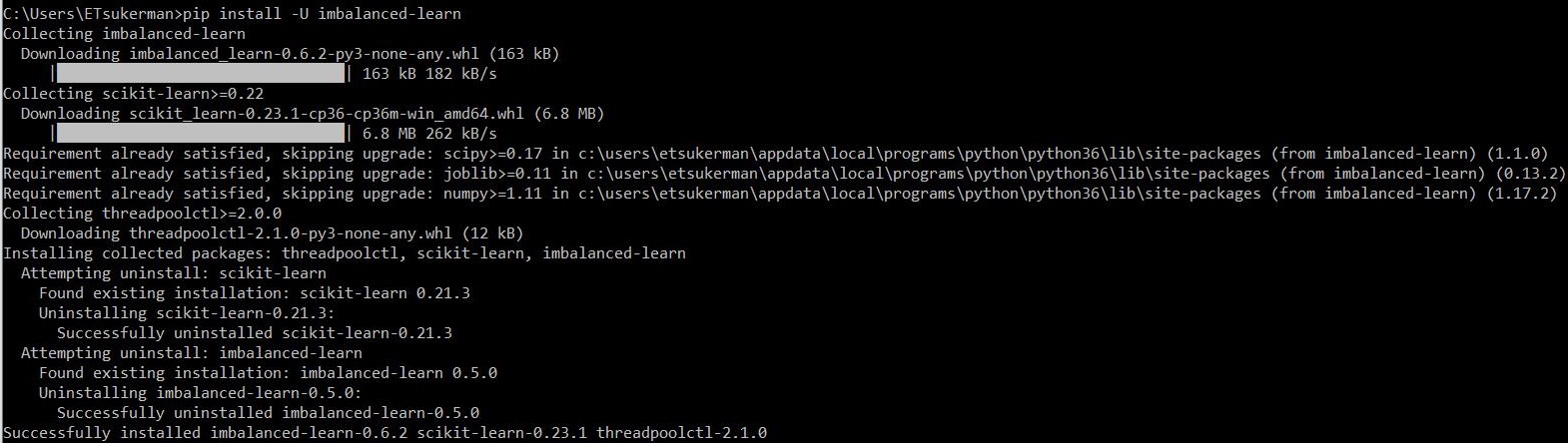
就这样!Imbalanced-learn 已安装并可供使用。
对于本指南的其余部分,代码可在https://github.com/emmanueltsukerman/imbalanced-learn-tutorial上找到。
用例 1:SMOTE
SMOTE 代表“合成少数类过采样技术”,是最常用的重采样技术之一。从高层次上讲,要进行过采样,请从少数类中选择一个样本(称为 S),然后选择它的一个邻居 N。然后在 S 和 N 之间的线段上选择一个随机点。这个随机的新点就是您使用 SMOTE 创建的合成样本。反复重复此操作,您可以创建越来越多的新样本来平衡类别不平衡。
现在您将了解如何使用 irreparated-learn 的 SMOTE 实现。为了说明这一点,您将使用信用卡欺诈检测数据集,该数据集位于https://www.kaggle.com/mlg-ulb/creditcardfraud。
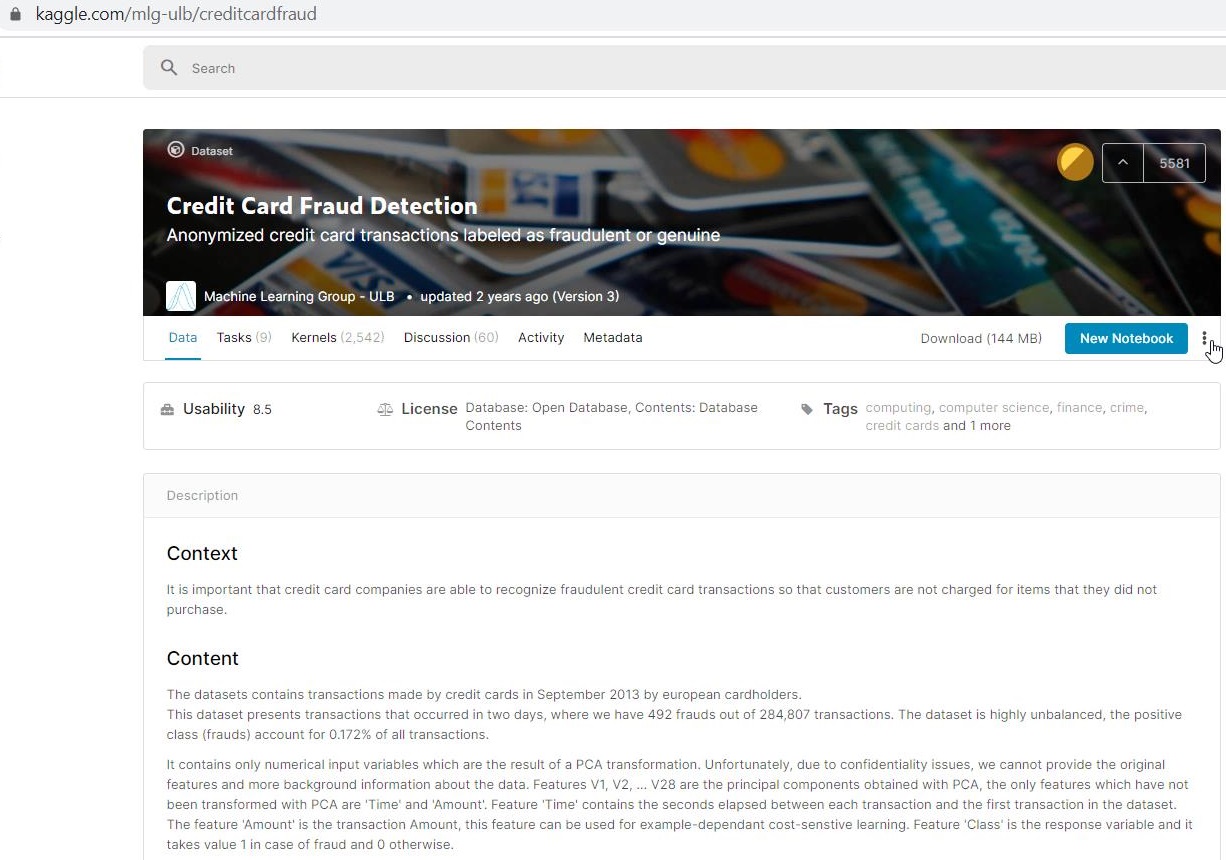
该数据集高度不平衡,因此它将作为一个很好的演示集。
下载数据集后,你可以看到它包含 28 个匿名特征以及时间、数量和类别。
import pandas as pd
df = pd.read_csv("creditcard.csv")
df.head()

将特征放入数组X中,将标签放入数组y中。
X = df.drop('Class', axis=1)
y = df['Class']
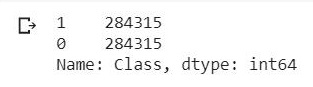
现在您将通过 SMOTE 对小类进行过采样,以便数据集中的两个类保持平衡。
from imblearn.over_sampling import SMOTE
X_smote, y_smote = SMOTE().fit_sample(X, y)
您可以看到类别现在是平衡的:
X_smote = pd.DataFrame(X_smote)
y_smote = pd.DataFrame(y_smote)
y_smote.iloc[:, 0].value_counts()
创建训练测试分组:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_smote, y_smote, test_size=0.2, random_state=0
)
import numpy as np
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
然后训练并测试一个简单的分类器:
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf.fit(X_train, y_train)
最后看性能:
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = clf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")
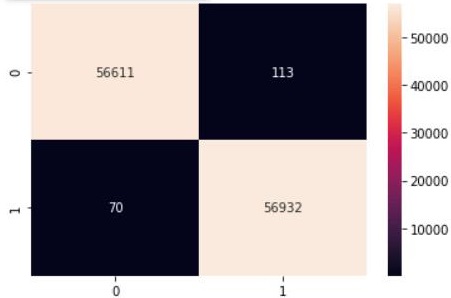
如您所见,通过利用 SMOTE,我们确保分类器产生相对平衡的分类,而不是不成功的模型,其中分类器可能会将所有样本归类为属于多数类别。
用例 2:ADASYN
ADASYN 借鉴了 SMOTE 的思想并在此基础上进行改进。具体来说,ADASYN 选择少数样本 S,这样“更难分类”的少数样本更有可能被选中。这使得分类器有更多机会学习棘手的实例。ADASYN 的代码与 SMOTE 的代码完全类似,只是你只需将“SMOTE”一词替换为“ADASYN”。
from imblearn.over_sampling import ADASYN
X_adasyn, y_adasyn = ADASYN().fit_sample(X, y)
<snip>
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = clf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")
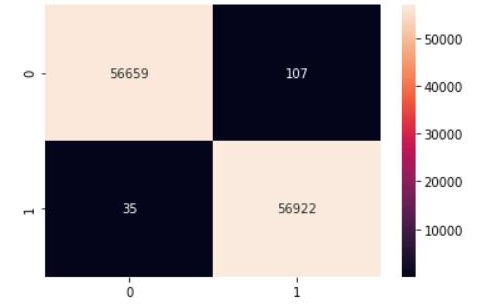
用例 3:平衡随机森林
BalancedRandomForestClassifier与 SMOTE 和 ADASYN 的不同之处在于它不是一种重采样方法,而是一种在训练过程中内部采用重采样的分类器。有关更多信息,请参阅Breinman 等人的《使用随机森林学习不平衡数据》。
实例化分类器:
from imblearn.ensemble import BalancedRandomForestClassifier
brf = BalancedRandomForestClassifier(n_estimators=100, random_state=0)
然后将数据集分为训练和测试:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
然后拟合并预测:
brf.fit(X_train, y_train)
y_pred = brf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")
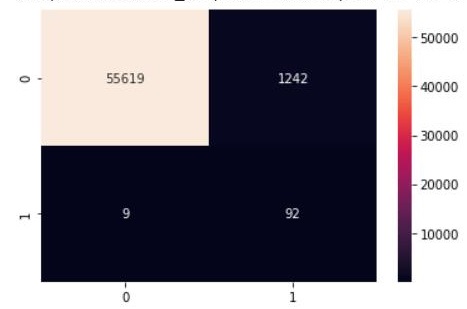
结论
对于数据科学家来说,能够自信地解决不平衡数据问题是一项很棒的技能。不平衡学习库为您提供了正确的工具。若要深入了解该库,我推荐您阅读写得很好的不平衡学习官方文档,网址为https://imbalanced-learn.readthedocs.io/en/stable/。祝您学习愉快!
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~