
正常运行时间与可用性:如何衡量和提高可靠性
在衡量应用程序的可靠性时,我们通常使用正常运行时间。正常运行时间是指服务正常运行的时间。它通常以百分比表示。但是,为了改善用户体验,必须关注可用性,包括用户体验组件。
在本文中,我将阐明可用性和正常运行时间之间的区别,并指出衡量可靠性的正确方法。
想要了解如何通过提高系统的可观察性来提高其可靠性?请阅读我的文章“ SRE:如何通过提高系统的可观察性来提高其可靠性” 。
什么是正常运行时间?
正常运行时间是指应用程序在一段时间内正常运行的时间。这很简单。例如,如果您的应用程序在过去 30 天内没有任何中断,则可用性为 100%。如果有一天中断,则正常运行时间为 96.67%。正常运行时间通常表示为应用程序正常运行时间的百分比。
什么是可用性?
可用性是指应用程序正常运行以服务用户的时间百分比。请注意,要准确衡量可用性,我们必须包括用户体验组件。
许多组织只是使用正常运行时间来指代可用性。在这种情况下,计算可用性的公式如下:

您还可以使用考虑平均故障时间 (MTTF) 和平均修复时间 (MTTR) 的公式来衡量可用性。该公式如下。
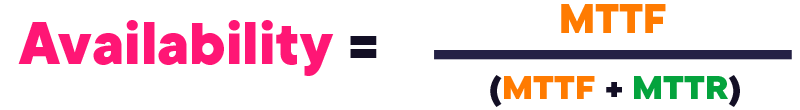
MTTF 是指故障发生前经过的平均时间。MTTR 是指系统在发生故障后恢复完全运行的平均时间。
从该公式中,您可以轻松得出几个观察结果:
首先,MTTR 越短,可用性越好,因为 MTTR 是分母。这就是为什么拥有必要的故障排除工具(包括可靠的端到端可观察性系统)对于更高的可用性至关重要。
其次,停机次数越少(故障频率越低),可用性就越高。例如,如果您的服务每天发生 5 分钟故障,则您的可用性可以按以下方式计算:
平均无故障时间= 24 小时
平均修复时间= 5 分钟
可用性= 24 / ( 24 + 5/60) = 99.65%
但是,如果您的应用程序每月出现一次持续 5 分钟的故障:
MTTF = 30 天 = 30 X 24 = 720 小时
平均修复时间= 5 分钟
可用性= 720 / ( 720 + 5/60 ) = 99.99%
现在您可以认识到减少停机频率和缩短维修时间的重要性。
可用性表
下表显示了在给定可用性目标的一段时间内您的应用程序不可用的时间量。

例如,对于 99.99% 的可用性(我对关键任务 Web 应用程序的建议),应用程序每年最多可以有 52.6 分钟的停机时间。
准确测量 MTTF 和 MTTR 可能具有挑战性。实际上,可以使用一组结合用户体验的明确定义的 SLO(服务级别目标)来测量可靠性。现在,让我们看看您需要测量什么来提高应用程序的可靠性。
我应该衡量哪些指标?
在可以使用监控工具测量的众多指标中,我们应该谨慎选择那些直接影响用户体验的指标。例如,虽然测量服务器的 CPU 利用率可以提供有价值的故障排除信息,但它不会揭示用户正在经历什么。更好的衡量指标是用户体验到的延迟(响应时间)。
在站点可靠性工程中,我们用来推导服务级别目标 (SLO) 的测量指标称为服务级别指标 (SLI)。我将根据以下应用类型提供良好 SLI 的建议:
SLI(服务水平指标)建议
1. Web 应用程序
这些应用程序具有 Web 浏览器界面,用户可以与之交互。Web 应用程序可能依赖一个或多个后端服务。Web 应用程序的一个示例是人们可以购买商品的在线电子商务网站。此类应用程序的 SLI 为:
在 Web 服务器或负载均衡器上测量的成功完成的 HTTP 请求数(HTTP 状态代码 200 系列)
在 Web 服务器或负载均衡器上测量的Web 请求的延迟(响应)时间(以毫秒为单位)
特定功能的响应时间(以毫秒为单位)。例如,将商品添加到购物车、完成购买、登录应用程序等。
2. API
这些通常是通过 API 提供特定功能的微服务。例如,身份验证服务可以对通过 Web 浏览器登录的用户进行身份验证。此类工作负载的 SLI 与 Web 应用程序的 SLI 类似。
在负载均衡器或 API 网关处测量的HTTP 500 错误(内部服务器错误)的数量
在负载均衡器或 API 网关处测量的成功完成的 HTTP 请求数(HTTP 状态代码 200 系列)
在负载均衡器或 API 网关处测量的API 请求的延迟(响应)时间(以毫秒为单位)
3. 后端应用程序
这些是处理数据的后端应用程序。一个典型的例子是文件传输应用程序,它在系统之间(通常是两家公司之间)移动文件。这里推荐的 SLI 是:
每天文件传输失败的次数
每个文件的失败记录百分比。如果适用,请考虑对失败类型进行分类。例如,失败可能是由于数据格式错误、目标不正确、数据验证检查等造成的。
数据的平均处理时间和 P95 处理时间(第 95 个百分位数)
4.桌面应用程序
这些是运行在用户桌面上的胖客户端应用程序。它们通常连接到后端系统来访问数据。这里推荐的 SLI 是:
应用程序启动时间: 以毫秒为单位
特定功能的延迟: 例如文件上传功能。
客户端错误的数量
缓存命中率:以百分比衡量
5.大数据处理
这些后端应用程序处理大量数据(每天数 TB),可能用于机器学习用例。它们也可以是解析、过滤和传输数据的数据管道。以下是这些类型应用程序的 SLI:
数据丢失,以记录的百分比衡量
重试失败的次数
数据解析失败
队列填充率(表示消息/记录开始排队)
6. 监控平台
这些是监控应用程序的可观察性平台。当然,我们需要测量这些系统的可靠性,以确保它们在需要时可用。以下是推荐的 SLI:
可用性:以用户可以查看指标并成功执行查询的时间百分比来衡量
搜索和仪表板加载的响应时间: 您应该使用合成探测器来测量它,以便将其与已知的响应时间进行比较。
数据新鲜度: 指标被纳入平台的速度
数据准确性: 同样,合成探测器可以帮助测量数据提取和检索的准确性。
结论
可靠性是任何成功应用的关键属性。要保持高水平的可靠性,必须始终测量正确的指标。虽然简单的正常运行时间指标可以提供一些可靠性的感觉,但要准确测量可靠性,必须测量直接影响用户体验的指标。为此,您必须定义与您的应用程序类型及其服务的特定功能相匹配的服务级别目标和服务级别指标。
想要了解有关 SRE 最佳实践的更多信息吗?
Pluralsight 提供了站点可靠性工程 (SRE) 基础知识学习路径,可教您有关 SRE 及其实施方法的所有知识。它涵盖了广泛的主题,从 SME 的基础知识以及如何将其纳入您的系统设计开始,到更高级的主题,例如如何管理 SRE 团队以及实施有效的事件响应和变更管理。
如果您喜欢这篇文章,我强烈建议您查看我的课程“实施站点可靠性工程 (SRE) 可靠性最佳实践”。祝您在实施可观察、可靠的系统的过程中好运!
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~