
NMT:使用 Keras 的编码器和解码器
介绍
本指南以神经机器翻译的编码器和解码器中涵盖的技能为基础,涵盖不同的 RNN 模型和 seq2seq 建模的强大功能。它还介绍了编码器和解码器模型在机器翻译中的作用;它们是两个独立的 RNN 模型,结合起来执行复杂的深度学习任务。
在本指南结束时,您将获得预处理的数据并提取构建模型所需的特征。
在本指南的这一部分中,您将使用这些数据以及 LSTM、编码器和解码器的概念来构建一个提供最佳翻译结果的网络。最后,这些结果将进一步用于构建一个简单的西班牙语学习代码,它将为您提供随机英语句子及其西班牙语翻译。
让我们开始建立模型。
建立模型
第一步是定义编码器的输入序列。由于这是字符级翻译,因此它会逐个字符地将输入插入编码器。现在您需要编码器的最终输出作为解码器的初始状态/输入。因此,对于编码器 LSTM 模型,return_state = True。通过此设置,您可以在输入序列末尾获得编码器的隐藏状态表示。state_h表示隐藏状态,state_c表示单元状态。
encoder_inputs = keras.Input(shape=(None, num_encoder_tokens))
encoder = keras.layers.LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
这会在解码器输入中设置解码器的初始状态。将从独热编码(解码器输入数据)中得到的第一个字符(即 SOS 或\t)与最终编码状态一起嵌入到解码器网络以获取第一个目标字符。
同样,LSTM return_sequences和return_state保持True,以便网络在每个时间步骤考虑解码器输出和两个解码器状态。该模型将一步一步地遍历网络的每一层,并在最后一层的输出处添加一个softmax激活函数。这将给出您的第一个输出词。它将这个单词反馈回来并预测完整的句子。
decoder_inputs = keras.Input(shape=(None, num_decoder_tokens))
decoder_lstm = keras.layers.LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = keras.layers.Dense(num_decoder_tokens, activation="softmax")
decoder_outputs = decoder_dense(decoder_outputs)
训练并保存模型
现在的目标是训练基于 LSTM 的基本 seq2seq 模型并预测coder_target_data,并通过设置优化器和学习率、衰减和 beta 值来编译模型。它计算损失和验证损失。准确度是性能矩阵。接下来,拟合模型,并将数据分成 80-20 的比例。最后,使用save()保存模型。
model = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer=Adam(lr=0.01, beta_1=0.9, beta_2=0.999, decay=0.001), loss='categorical_crossentropy', metrics=["accuracy"])
model.fit(
[encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
)
model.save("E2S")
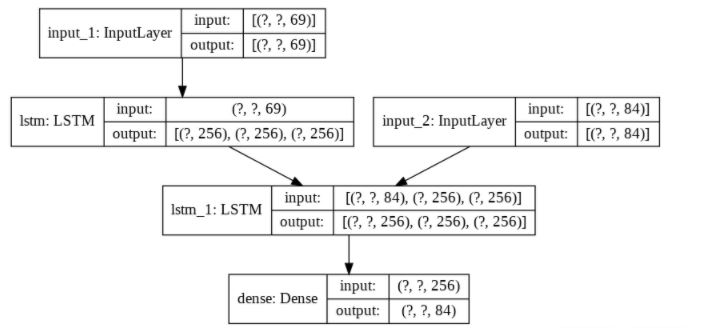
from keras.utils import plot_model
plot_model(model, to_file='modelsummary.png', show_shapes=True, show_layer_names=True)
print("shape encoder_input_data :",encoder_input_data.shape)
print("shape decoder_input_data :",decoder_input_data.shape)
print("shape decoder_target_data:",decoder_target_data.shape)

解码句子
最后,使用 Keras model()函数为coder_inputs(即输入张量)和编码器隐藏状态state_h_enc和state_c_enc作为输出张量创建模型。
encoder_inputs = model.input[0] # input_1
encoder_outputs, state_h_enc, state_c_enc = model.layers[2].output # lstm_1
encoder_states = [state_h_enc, state_c_enc]
encoder_model = keras.Model(encoder_inputs, encoder_states)
现在为解码器构建模型。
decoder_inputs = model.input[1] # input_2
decoder_state_input_h = keras.Input(shape=(latent_dim,), name="input_3")
decoder_state_input_c = keras.Input(shape=(latent_dim,), name="input_4")
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_lstm = model.layers[3]
decoder_outputs, state_h_dec, state_c_dec = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs
)
decoder_states = [state_h_dec, state_c_dec]
decoder_dense = model.layers[4]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = keras.Model(
[decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states
)
创建两个反向查找标记索引来解码序列以使其可读。
reverse_input_char_index = dict((i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i, char) for char, i in target_token_index.items())
接下来,创建一个名为decode_sequence的预测函数。生成长度为1的空序列后,模型应该知道何时开始和停止读取文本。在这种情况下,要读取文本,模型将检查\t。保持两个条件,要么达到句子的最大长度,要么找到停止字符\n。继续将目标序列更新一并更新状态。
def decode_sequence(input_seq):
states_value = encoder_model.predict(input_seq)
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, target_token_index["\t"]] = 1.0
stop_condition = False
decoded_sentence = ""
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
if sampled_char == "\n" or len(decoded_sentence) > max_decoder_seq_length:
stop_condition = True
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.0
states_value = [h, c]
return decoded_sentence
学习西班牙语
运行单元格时会出现一个随机句子。这些句子很基础。学习一门新外语总是能提升你的技能。此外,当你访问西班牙时,它也会很有帮助 :)
i = np.random.choice(len(input_texts))
input_seq = encoder_input_data[i:i+1]
translation = decode_sequence(input_seq)
print('-')
print('Input:', input_texts[i])
print('Translation:', translation)

使用谷歌翻译验证。
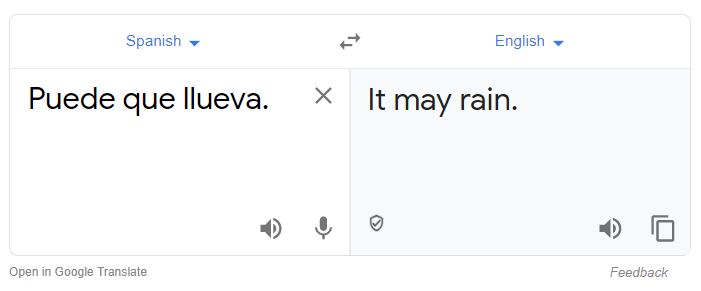
完美!!
结论
逐字符翻译准确无误。Seq2seq 模型可以处理可变长度的输入。编码器和解码器协同工作。编码器的 LSTM 权重会更新,以便学习文本的空间表示,而解码器的 LSTM 权重会给出语法正确的句子。任何项目的性能都取决于您选择的模型以及数据量和预处理。但超参数在深度学习问题中也起着重要作用。您也可以通过调整超参数或增加数据来提高此模型的准确性。
机器翻译也可以使用 GRU RNN 模型进行。它是 LSTM 的近亲,但状态较少。我建议您了解不同的 RNN 模型。您可以在此处了解有关 GRU 的更多信息,并学习了解这两个 RNN 之间的差异,然后选择能为您带来最佳结果的模型。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!

















请先 登录后发表评论 ~