

神经机器翻译的编码器和解码器
介绍
世界上有 7,000 多种语言。然而,全球使用最广泛的语言只有 23 种,包括英语、普通话、印地语和西班牙语。随着世界联系越来越紧密,语言翻译成为沟通桥梁。

Sequence2Sequence (seq2seq) 建模的强大功能
使用 seq2seq 建模可以解决多种任务,包括文本摘要、语音识别、图像和视频字幕以及问答。它还可以用于基因组学中的 DNA 序列建模。seq2seq 模型有两个部分:编码器和解码器。两者独立工作,然后组合在一起形成一个巨大的神经网络模型。
该架构能够处理可变长度的输入和输出序列。下图显示了 RNN 模型的类型及其用例。
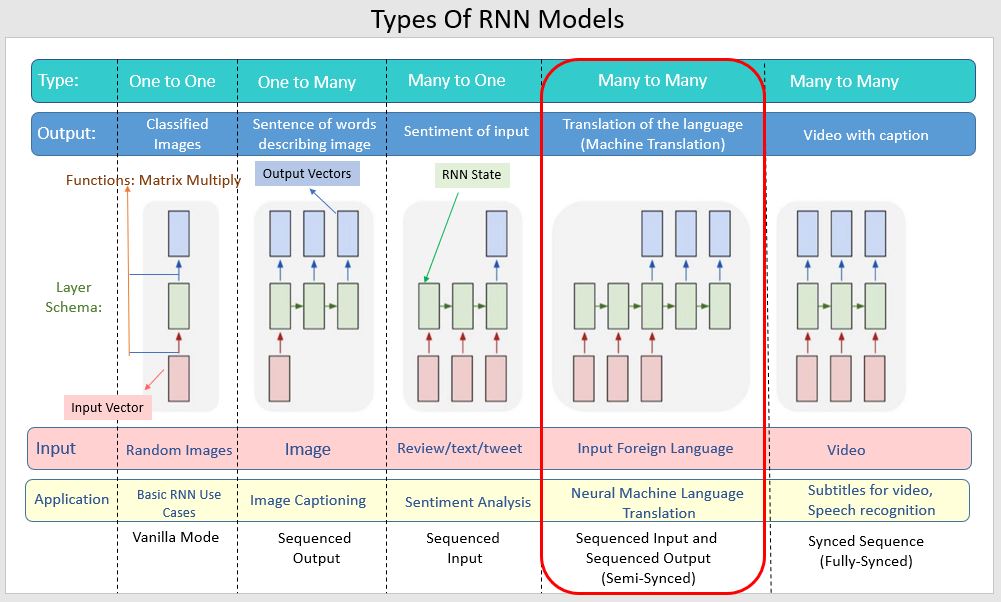
编码器和解码器
以下部分将深入介绍编码器-解码器。
编码器
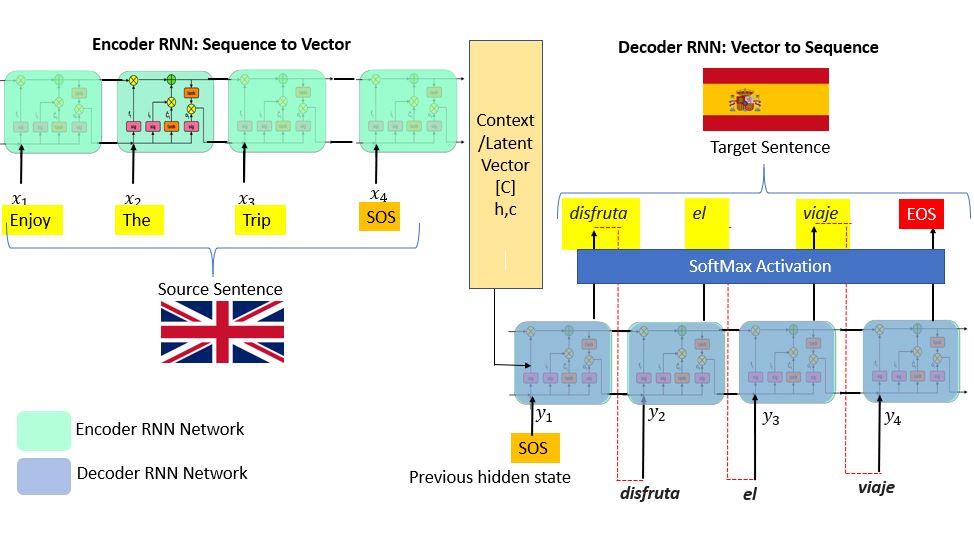
编码器位于输入端;它理解序列并降低输入序列的维度。该序列具有固定大小,称为上下文向量。此上下文向量充当解码器的输入,解码器在到达末尾标记时生成输出序列。因此,您可以将这些 seq2seq 模型称为编码器-解码器模型。
该架构可以处理可变长度的输入和输出序列。
解码器
如果您将 LSTM 用于编码器,请将相同的 LSTM 用于解码器。但它比编码器网络稍微复杂一些。您可以说解码器处于“感知状态”。它知道您到目前为止生成了哪些单词以及之前的隐藏状态是什么。解码器的第一层通过使用来自编码器网络的上下文向量“C”来初始化以生成输出。然后在开始时应用一个特殊标记来指示输出生成。它在最后应用一个类似的标记。第一个输出字是通过运行堆叠的 LSTM 层生成的。SoftMax激活函数适用于最后一层。它的工作是在网络中引入非线性。现在这个字通过剩余的层并重复生成序列。
多种因素都决定着编码器-解码器模型的准确率能否提高。优化器、交叉熵损失、学习率等超参数在提高模型性能方面发挥着重要作用。
导入库并加载数据集。
本示例将介绍Keras中 seq2seq 建模的简单实现。我建议在 GPU 上运行该模型。您可以利用Google Colab 的免费 GPU 功能。
转到编辑,然后转到笔记本设置,进行更改,然后保存。
首先安装你的驱动器:
from google.colab import drive
drive.mount('/content/drive')
复制并粘贴验证码,然后按回车键。
设置环境、安装库并定义参数:
import tensorflow as tf
from tensorflow import keras
from keras.layers import *
from keras.models import *
from keras.utils import *
from keras.initializers import *
from keras.optimizers import *
定义参数并设置您之前在驱动器上下载的spa.txt文件的路径。定义批处理大小、训练的时期、编码器的 LSTM 潜在维数以及样本数量。
batch_size = 64
epochs = 100
latent_dim = 256
num_samples = 10000
# set the data_path accordingly
data_path = "/content/drive/My Drive/spa.txt"
相应地更改data_path。
预处理
您不需要进行深入的文本预处理步骤。但如果您想了解有关噪声和文本预处理的更多信息,请参阅本《文本处理的重要性》指南。您可以使用标记化;它的工作是将输入的句子转换为整数序列。为此,请使用 Keras 的Tokenizer()类传递数据。
接下来,对数据进行矢量化。它将读取每一行并向其附加一个列表。前三行如下。
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, "r", encoding="utf-8") as f:
lines = f.read().split("\n")
此示例将参数设置为 10,000 个样本。下面代码的前两行将把英文文本放入 input_text 中,把西班牙语文本放入target_text中。
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text, _ = line.split("\t")
############### A ###############
target_text = "\t" + target_text + "\n"
input_texts.append(input_text)
target_texts.append(target_text)
############### B ###############
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
print(input_characters)
print(target_characters)
下一步是使用字符开头的制表符 ( \t ) 和字符结尾的\n来定义序列字符的开始和结束。
除了英语和西班牙语文本,您还需要它们的单位字符列表。相应的列表输出如下。
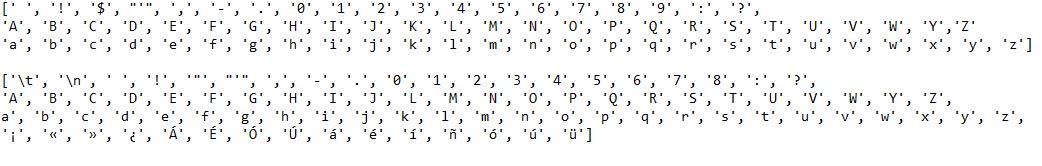
定义参数。它们在构建模型和特征工程时很重要。
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print("No.of samples:", len(input_texts))
print("No.of unique input tokens:", num_encoder_tokens)
print("No.of unique output tokens:", num_decoder_tokens)
print("Maximum seq length for inputs:", max_encoder_seq_length)
print("Maximum seq length for outputs:", max_decoder_seq_length)

现在您有了字符列表,请执行索引映射来输入并定位它。
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
print(input_token_index)
print(target_token_index)

请注意,每个字符现在都与一个整数值相关联。
有关预处理的更多详细信息,请参阅Keras 文档。
特征工程
为了生成特征向量,我们使用了 on-hot 编码。将 3D numpy 数组转换为存储 one-hot 编码。为了生成特征的变量,我们使用了coder_input_data、decoder_input_data、decoder_target_data。encoder_input_data 和coder_input_data分别包含英语和西班牙语句子的one -hot 向量化。
第一个维度input_texts表示样本文本的数量(本例中为 10,000)。第二个维度max_encoder_seq_length(英语)和max_decoder_seq_length(西班牙语)是样本中最长的编码器/解码器序列长度。第三个维度num_encoder_tokens(英语)和num_decoder_tokens(西班牙语)包含input_charaters和output_characters中的独特字符。
解码器目标数据与解码器输入数据类似,唯一不同之处在于解码器目标数据偏移一个时间戳。解码器目标数据[:, t, :]与解码器输入数据[:, t + 1, :]相同。
现在一切都已设置好,建立模型并将上述变量和特征向量放入适当的编码器-解码器模型中。
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype="float32"
)
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.0
encoder_input_data[i, t + 1 :, input_token_index[" "]] = 1.0
for t, char in enumerate(target_text):
decoder_input_data[i, t, target_token_index[char]] = 1.0
if t > 0:
decoder_target_data[i, t - 1, target_token_index[char]] = 1.0
decoder_input_data[i, t + 1 :, target_token_index[" "]] = 1.0
decoder_target_data[i, t:, target_token_index[" "]] = 1.0
结论
<font style="vertical-align:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!




































请先 登录后发表评论 ~