
在 Power BI 中实现聚类
介绍
聚类是一种无监督机器学习算法,通过将数据划分为簇来寻找数据中的模式。这些簇的创建方式使得簇内的点是同质的,而簇之间的点是异质的。聚类通常用于市场细分和营销分析的多个领域。
在本指南中,您将学习如何在 Power BI Desktop 中实现聚类。您将实现两种类型的聚类:双变量和多变量。
数据
在本指南中,您将使用多年来银行贷款发放的虚构数据集。该数据包含 3000 个观测值和 17 个变量。您可以在此处下载数据集。主要变量如下所述:
- 日期:贷款发放日期。
- 收入:申请人的年收入(以美元计)。
- Loan_disbursed:银行发放的贷款金额(以美元计)。
- 年龄:申请人的年龄。
- 性别:申请人是女性(F)还是男性(M)。
- Interest_rate:发放贷款的年利率,以百分比表示。
- 目的: 贷款目的。
- Weeknum:一年中的周数。
- Outstanding_debt:贷款发放前申请人的未偿还债务(以美元计)。
首先加载数据。
加载数据
打开 Power BI Desktop 后,将显示以下输出。
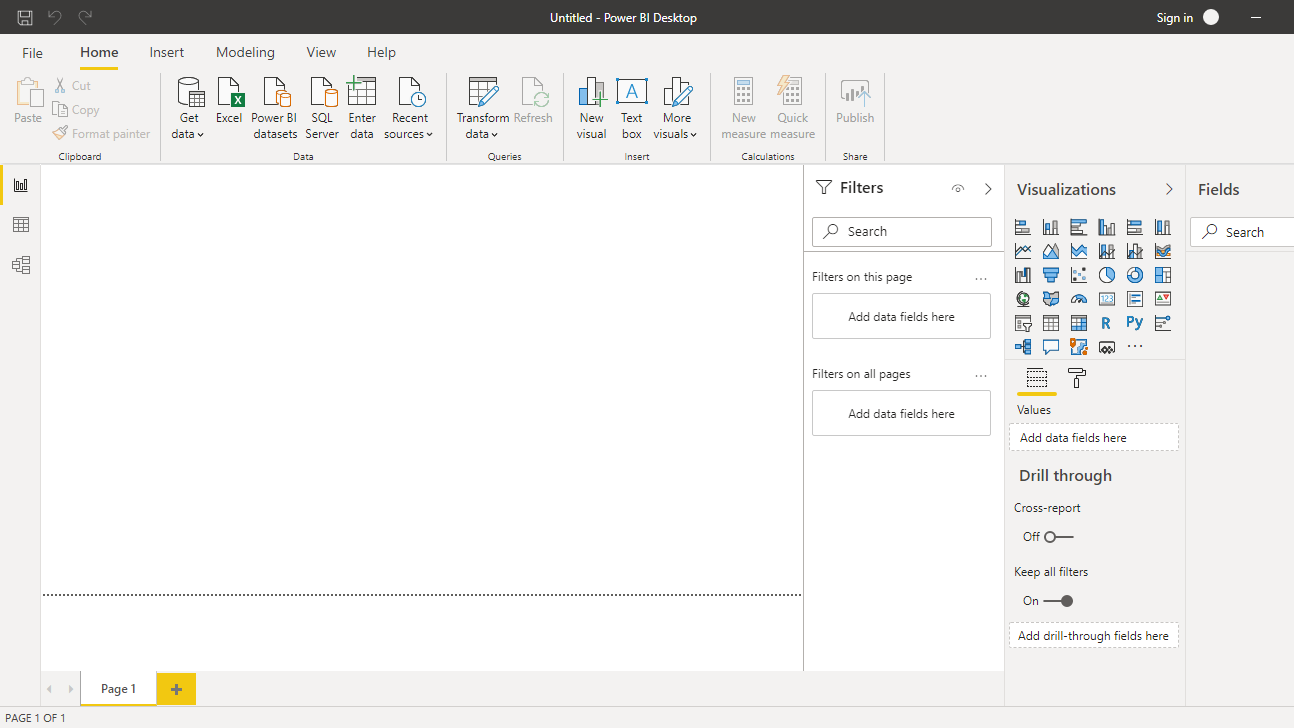
单击获取数据并从选项中选择Excel 。
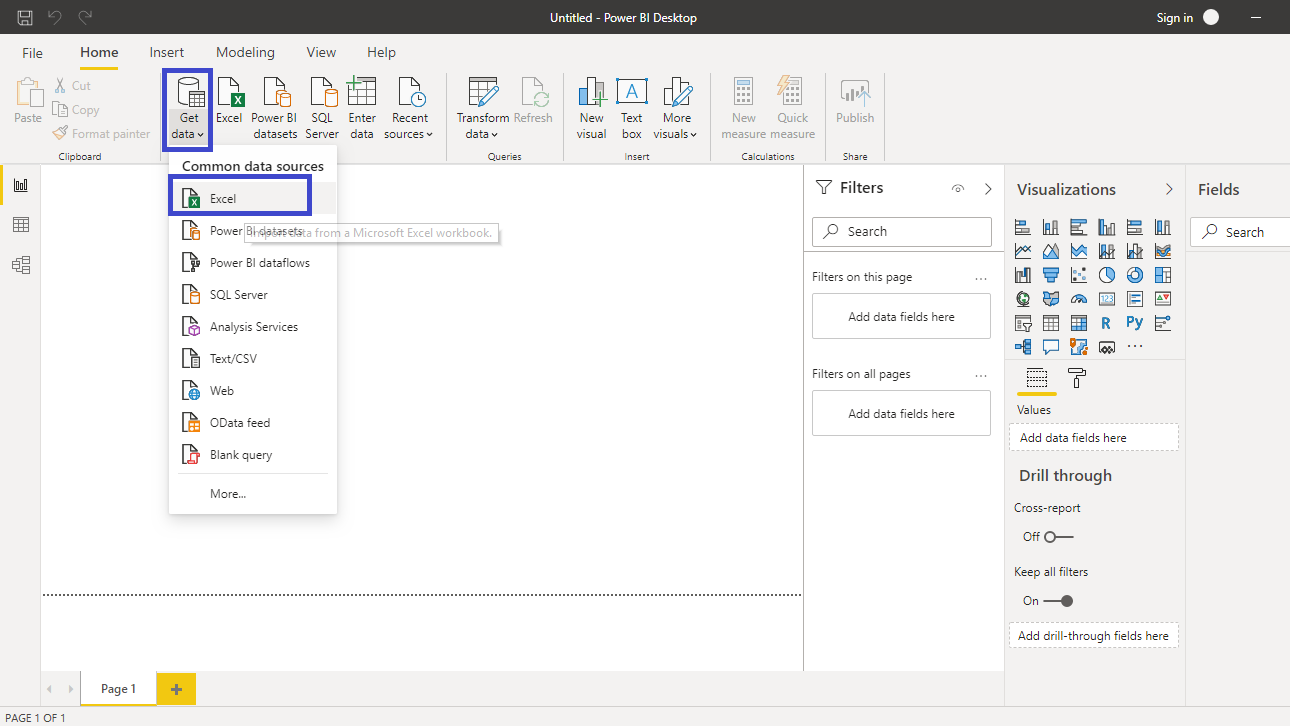
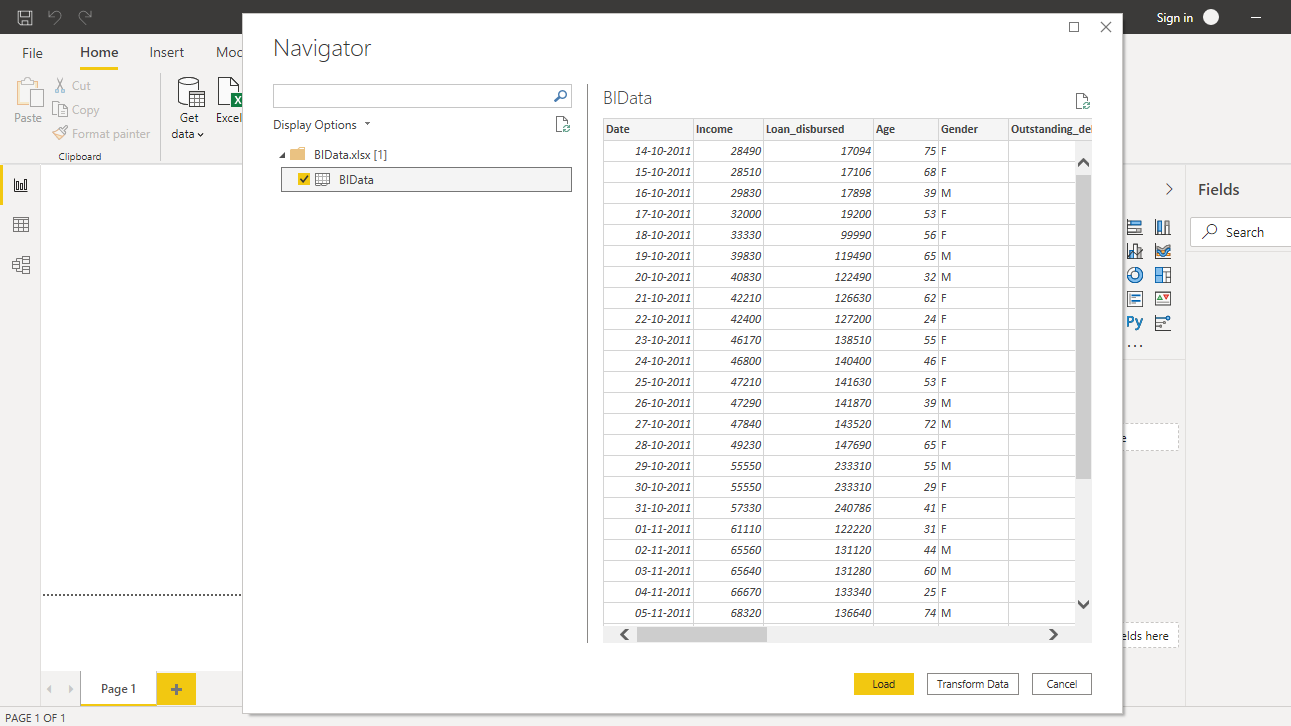
浏览到文件的位置并选择它。文件的名称是BIdata.xlsx,您将加载的工作表是BIData工作表。将显示数据预览,一旦您确信您正在加载正确的文件,请单击“加载”。
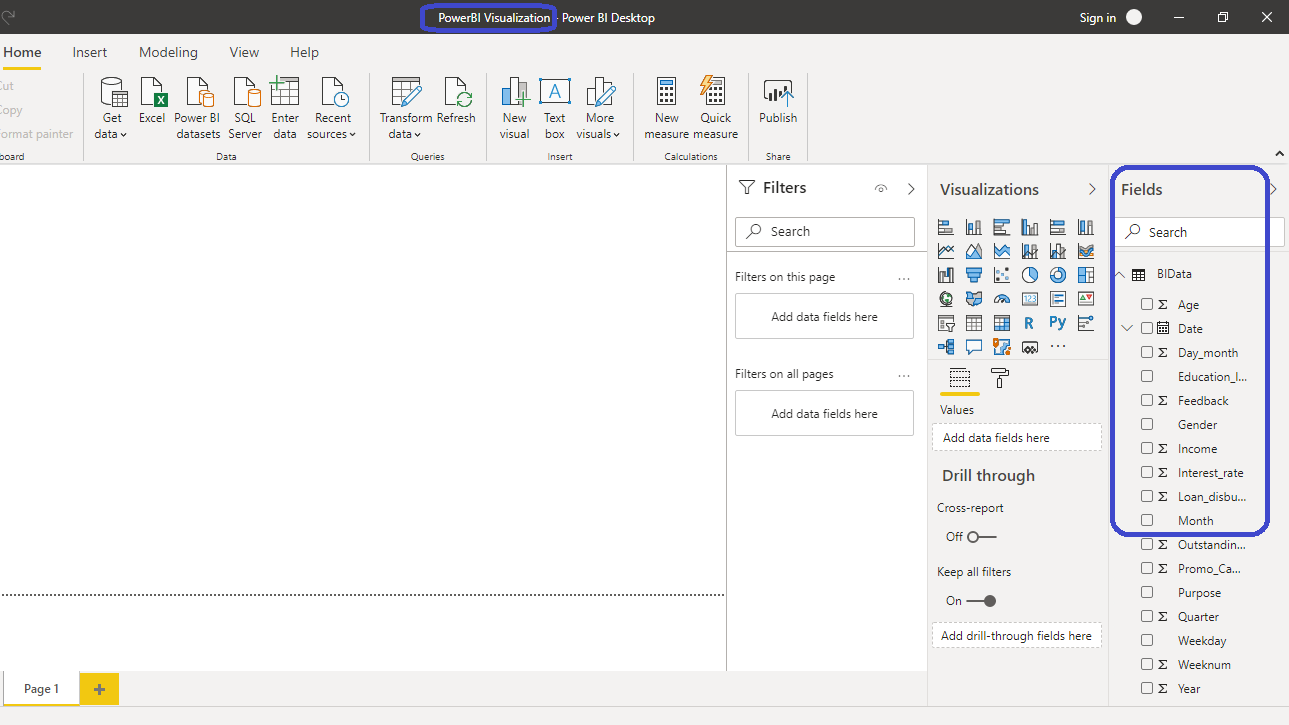
您已加载文件,可以保存仪表板。它被命名为PowerBI Visualization。“字段”窗格包含数据的变量。
双变量聚类
双变量聚类是指当您有两个定量变量时在数据中查找聚类的技术。用于聚类的两个变量是Income和Loan_disbursed 。要实现双变量聚类,散点图是一种强大的可视化图。您可以在“可视化”窗格中找到它。
单击上面显示的图表,它将在画布上创建一个图表框。目前还未显示任何内容,因为您尚未添加所需的可视化参数。这些参数已添加到“可视化”窗格下的选项中。
您可以在画布上调整图表的大小。您还可以使用箭头>符号折叠窗格中的“过滤器”选项。
下一步是填写Fields选项下的可视化参数,如下所示。将变量Income拖到X Axis字段,将Loan_disbursed拖到Y Axis字段。您还需要在Details字段中提供一个变量,以显示针对该变量的散点图。将Weeknum变量拖到Details字段。
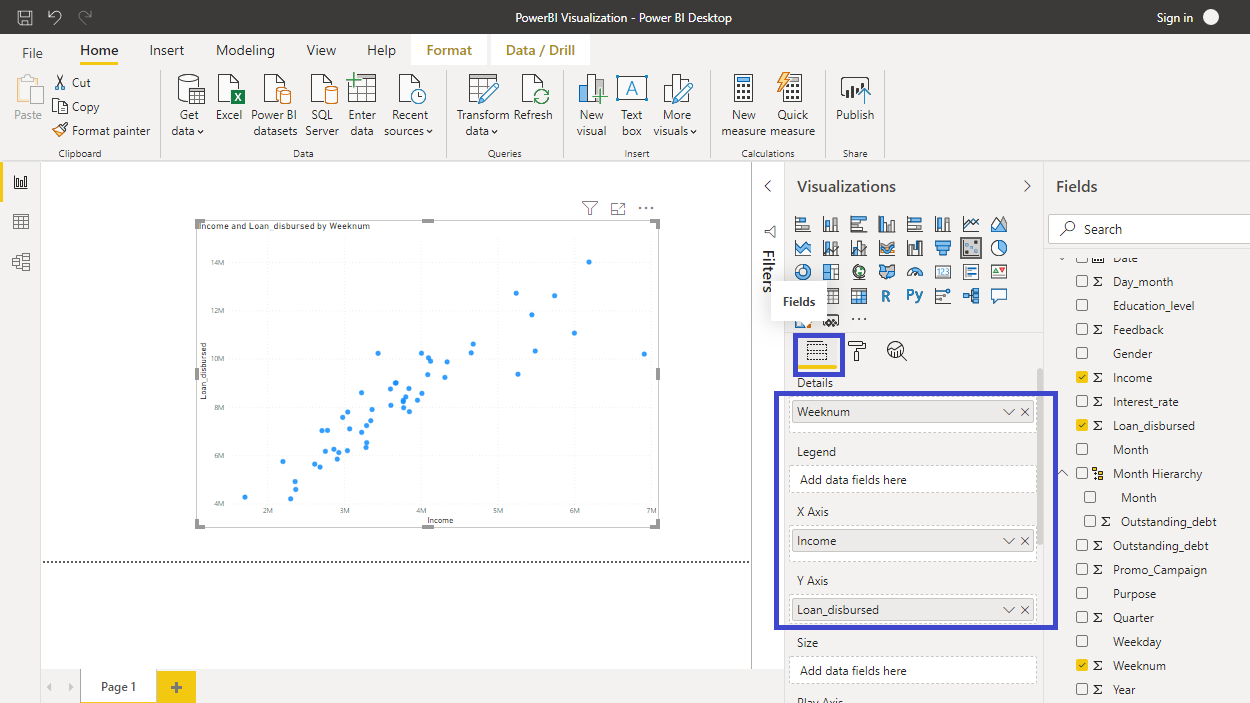
散点图创建完毕,下一步是创建聚类。右键单击下面显示的三个点...,您将可以选择自动查找聚类。
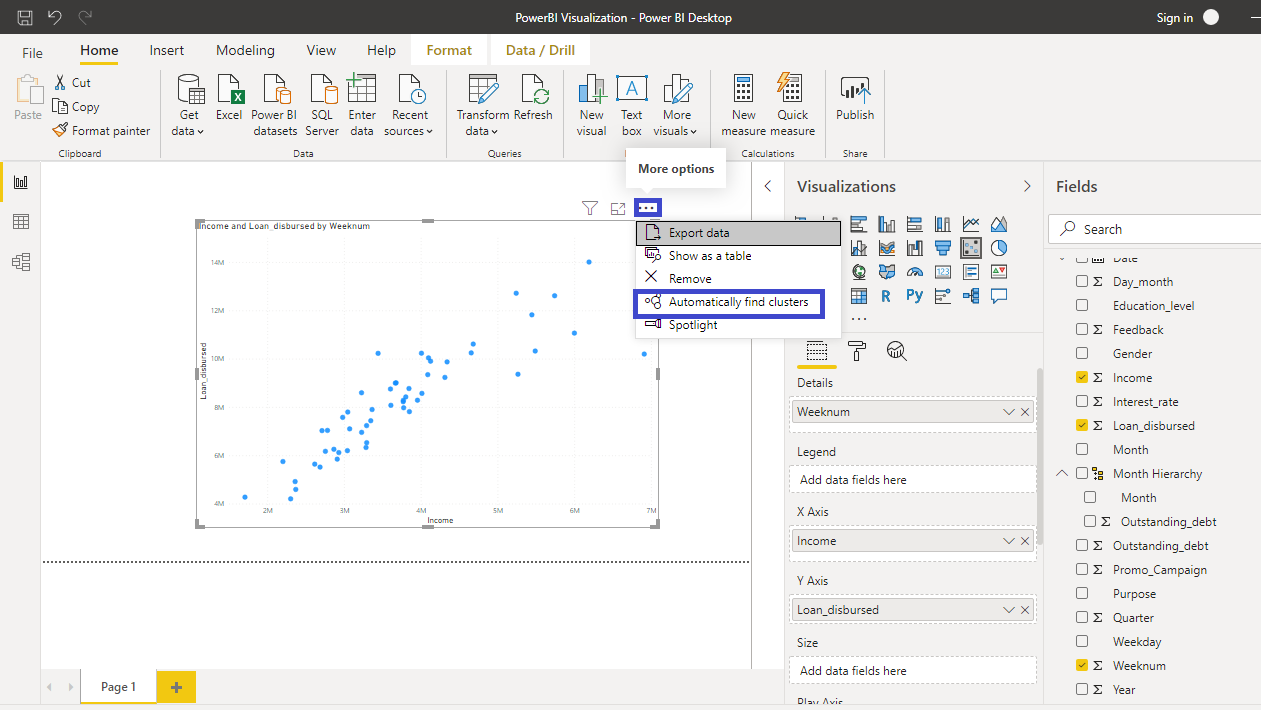
上述步骤将创建一个选择簇数量的选项。您也可以选择保持自动,但在本例中,您将簇数量设置为 4。
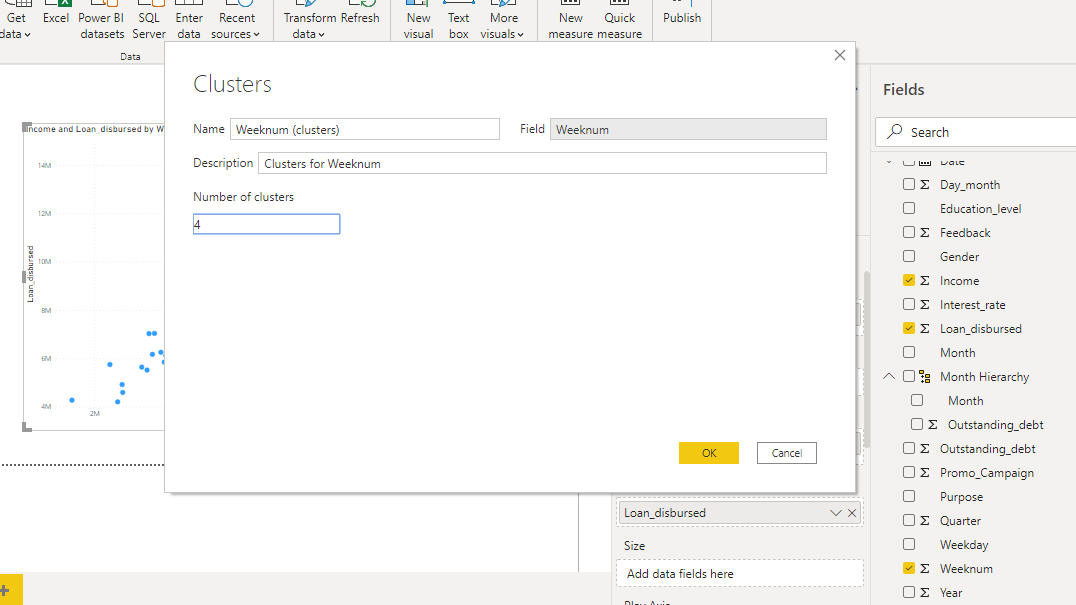
点击确定,Power BI 将在后台工作,创建四个聚类并将其添加到双变量散点图中。您可以通过不同的聚类颜色看到聚类点的区分。
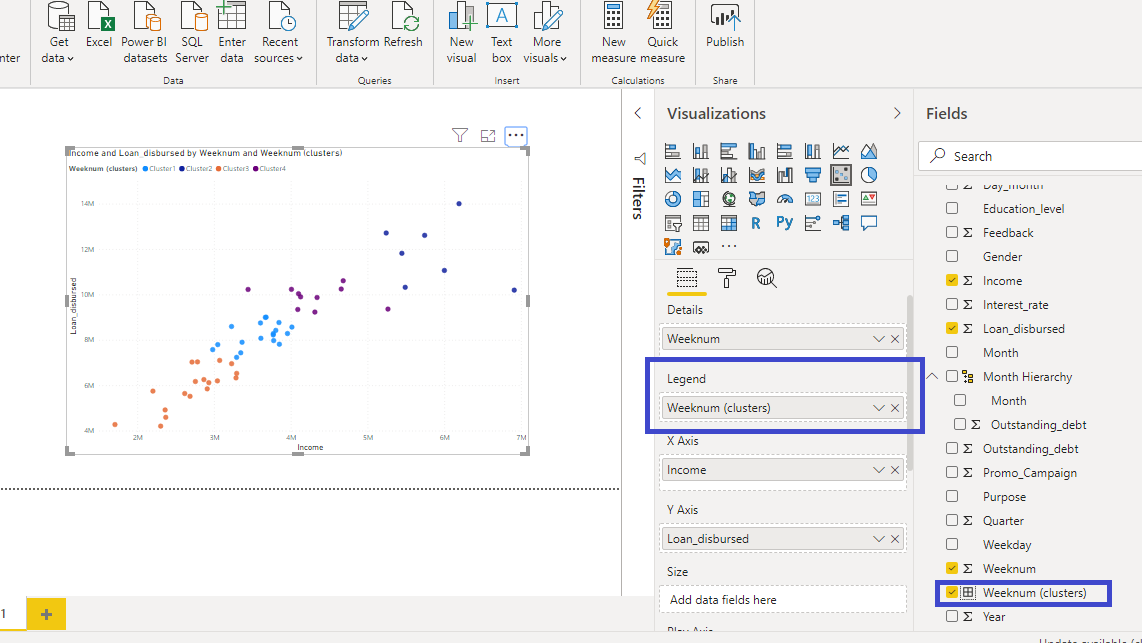
在上面的输出中,你可以看到 Power BI 创建了一个新变量Weeknum (clusters),并将其放置在Legend字段中。这使你可以灵活地以与原始数据集中的任何其他变量相同的方式使用此新变量。
多元聚类
在上一节中,您已对两个变量实施了聚类。在商业智能和分析中,您经常需要考虑多个变量进行聚类。在这种情况下,您可以扩展上述分析并包含多个变量。为此,首先调整散点图的大小以腾出空间进行多变量聚类,然后单击“可视化”窗格下的“表格”。
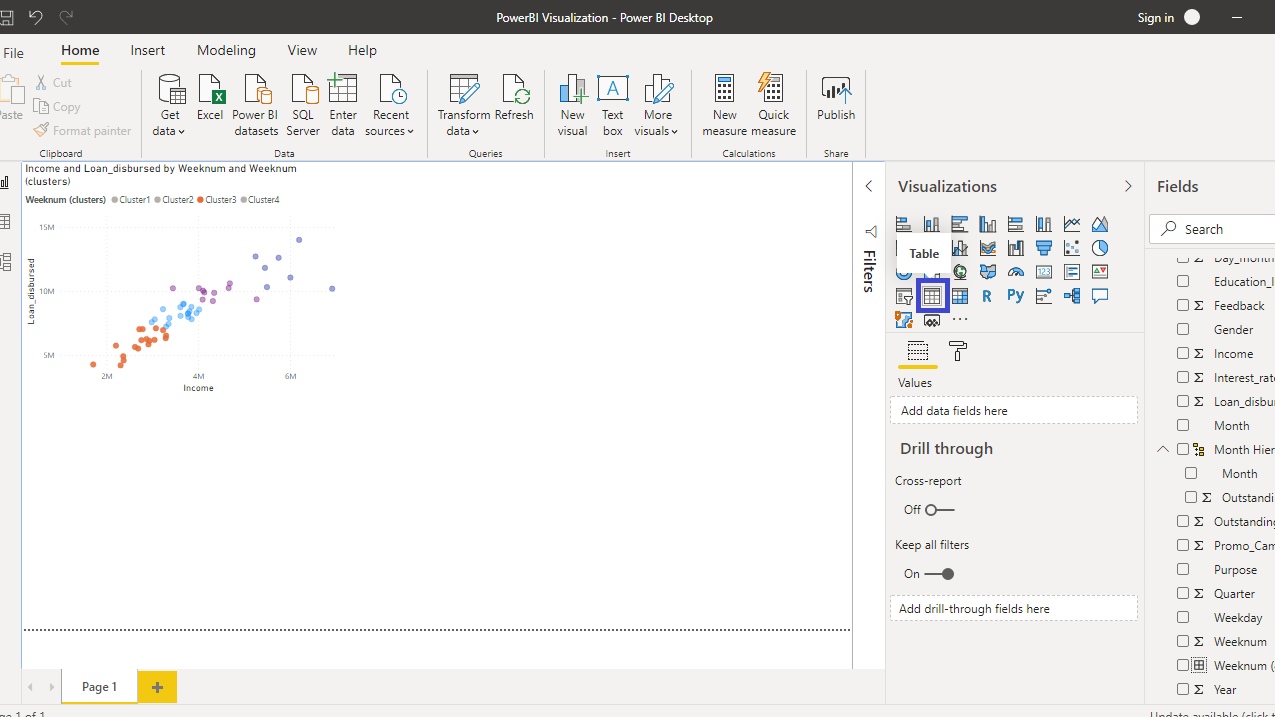
单击上面显示的表格图,它将在画布上创建一个表格。由于您尚未添加所需的可视化参数,因此尚未显示任何内容。
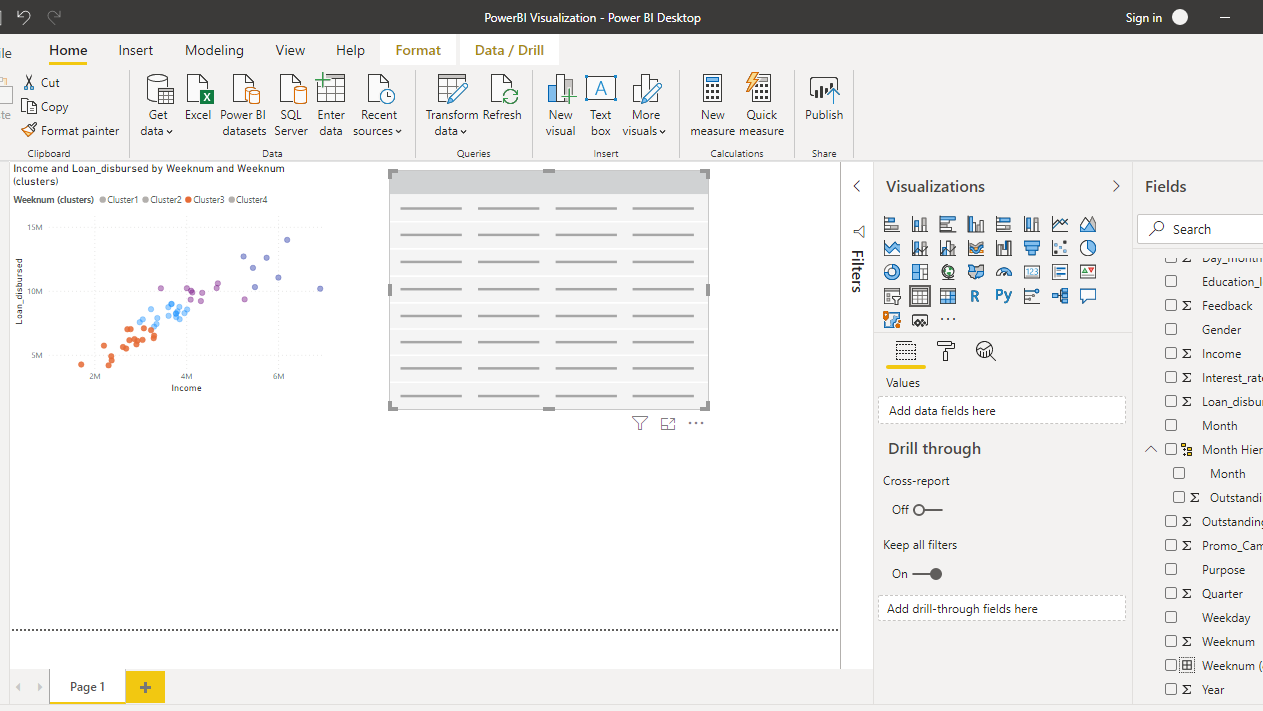
在Values字段下,如下所示,拖动变量Weeknum、Income、Loan_disbursed、Interest_rate、Age和Outstanding_debt。这将生成下表。
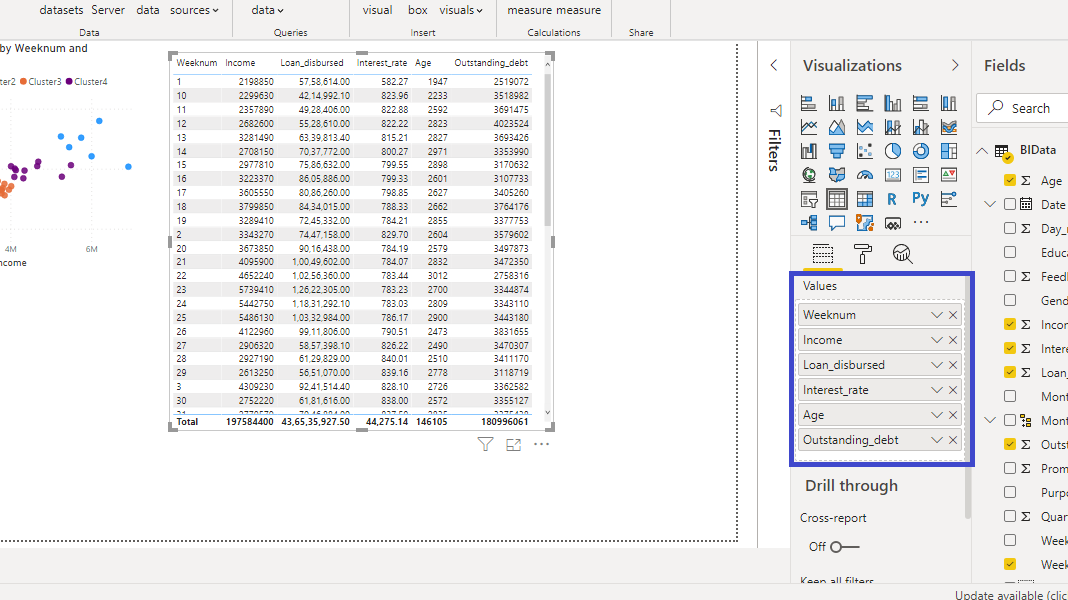
下一步是创建集群。为此,像以前一样右键单击三个点,然后选择“自动查找集群”。
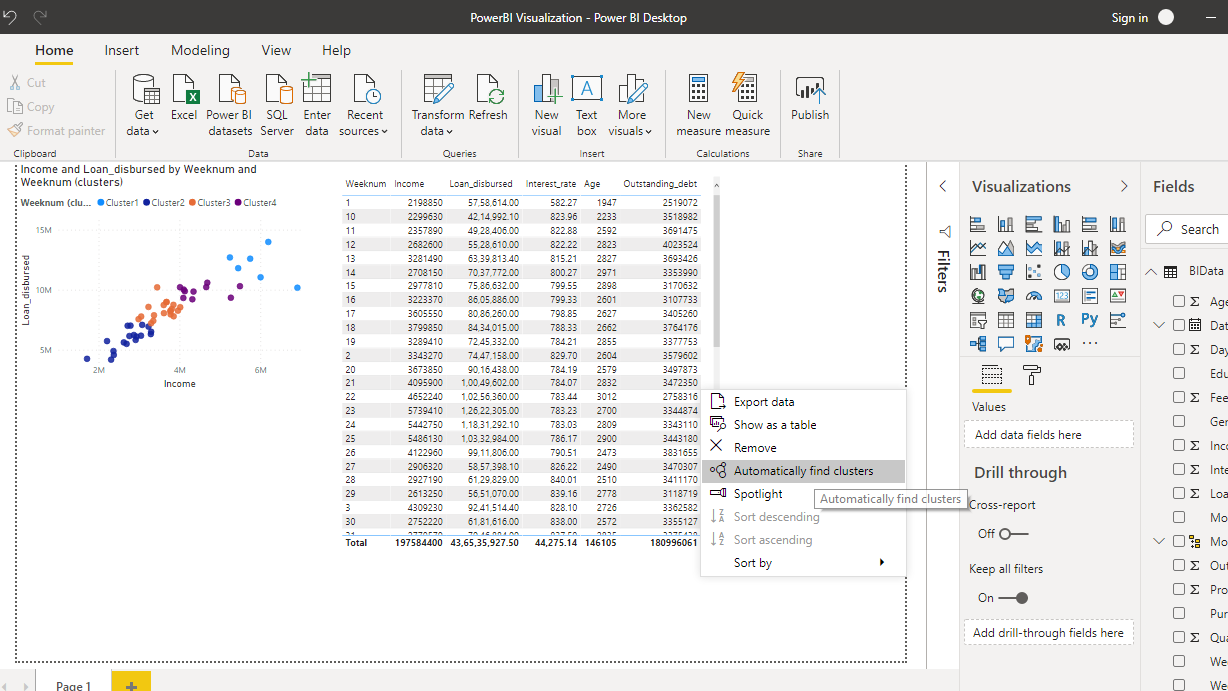
在生成的选项窗格中,将其命名为“多元聚类”。将“聚类数”值设置为“自动”。
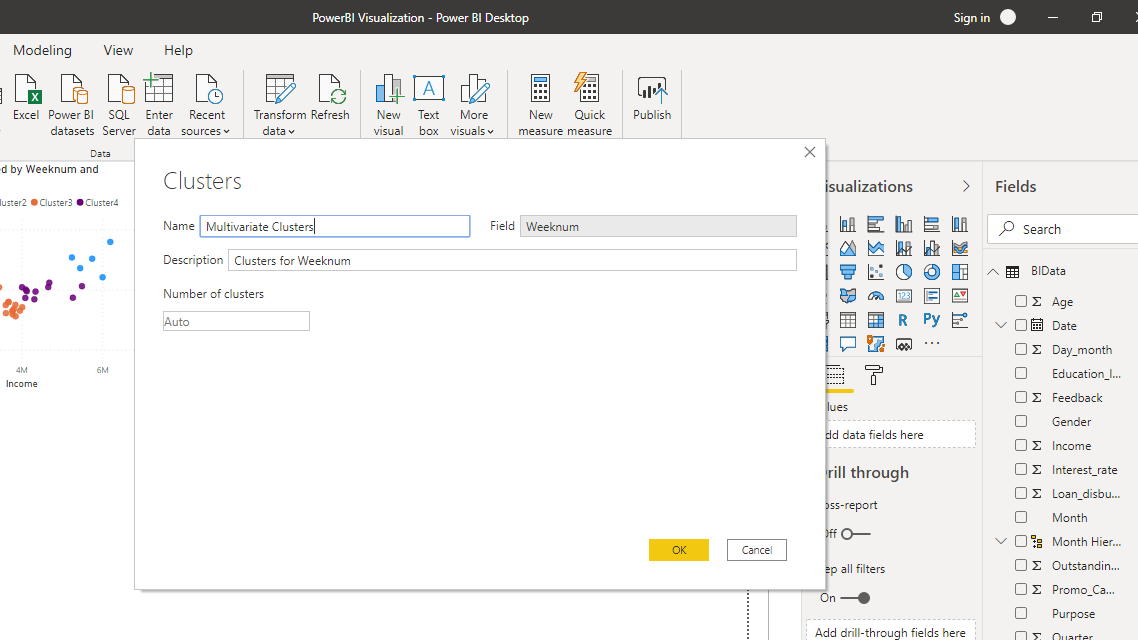
单击“确定”将创建一个多元聚类变量并将其添加到表中。它还将将其添加到“值”字段。
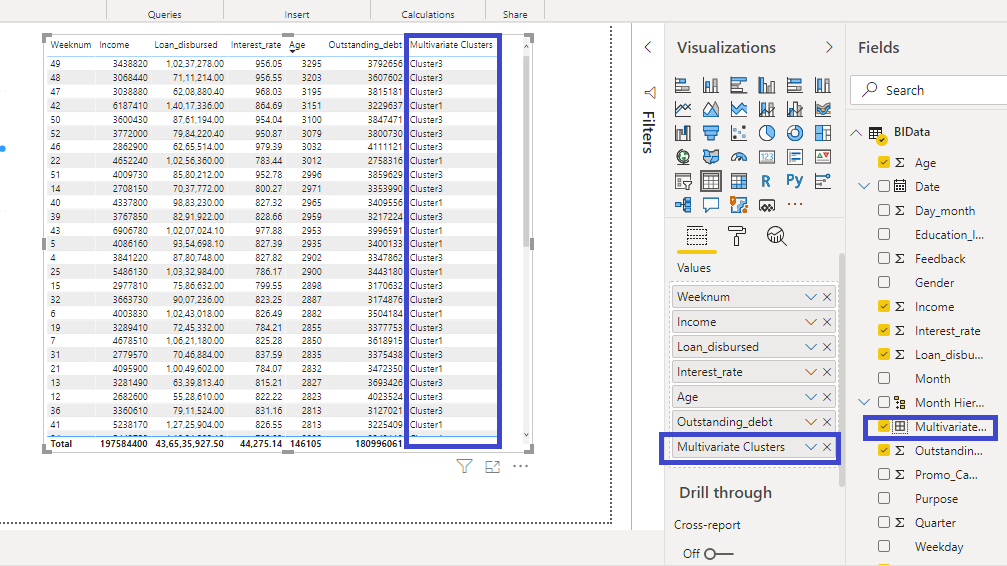
您可以像分析原始数据集中的任何其他变量一样更好地分析聚类。例如,您可以单击“表格图表”选项,这将在画布中创建一个表格。
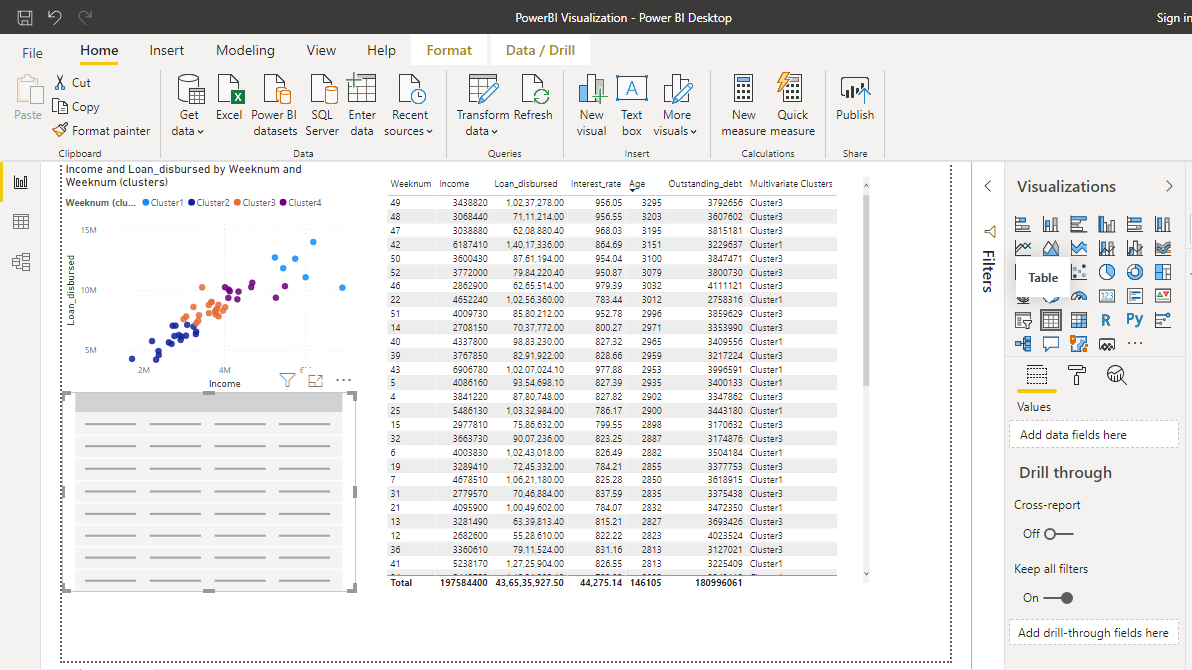
单击图表,然后在“值”下,将“多元聚类”<font style="vertical-alig
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!

















请先 登录后发表评论 ~