
使用 Google Teachable Machine 进行图像分类入门
介绍
图像分类是通用计算机视觉领域中利润越来越丰厚的领域。越来越多的商业用例被发现,数据集也越来越多。这些用例涵盖农业、医疗保健以及许多其他垂直行业。一些图像数据集可以在kaggle 存储库中探索。
这一切都意味着对具备图像分类服务知识的从业人员的需求增加。为了弥补这一差距,已经开发了许多服务(主要是基于云的服务),以在开发图像分类机器学习 (ML) 模型方面为开发人员分担繁重的工作。其中一些服务(例如 Google 的Teachable Machine)为开发人员提供了一定程度的可配置性,而其他一些服务则通过 API 提供服务。其中包括Google 的 Cloud Vision、Imagga和IBM Watson等。
本指南将使用 Teachable Machine 在 Python 中构建一个简单的图像分类脚本。本指南假设您至少具有中级Python 知识、keras的应用知识以及用于图像分类的机器学习的初级知识。
谷歌可教机器
Google 的Teachable Machine是一个基于网络的资源,用于训练和开发用于图像分类、声音分类和全身姿势分类的 ML 模型。该资源允许您导出模型以在您的应用中使用,也可以将其发布到网上,Google 会免费托管该模型并提供网址。
示例应用程序
在本指南中,我们将考虑植物疾病分类的一个示例用例。考虑这样一个场景:您想要开发一款应用程序来帮助玉米种植者识别影响其玉米作物的疾病类型。
练习数据集
我们将使用 Kaggle 的免费数据集,可在此处找到。

玉米叶片上常见锈病的样本图像
生成图像分类模型
接下来的界面非常直观。您至少有两个类别,您可以打开网络摄像头并录制要分类的项目的照片或上传图片。
每个类都应在类占位符中正确标记。在某些情况下,可能会有两个以上的类。要添加更多类,请点击添加类按钮。
在玉米农民场景中,您将有四个类别:健康类别、北方叶枯病类别、普通锈病类别和灰斑病类别。
机器学习与数据输入一样好。因此,从植物疾病数据集的train/文件夹中上传尽可能多的每个类别的图像。确保图像和类别名称对应且正确。
上传训练图像并注释类别名称后,单击训练模型按钮并等待结果。您可以打开“高级”选项卡并根据自己的喜好调整学习率等参数,并判断这是否会提高模型的性能。
最后,通过单击预览按钮并上传测试图像来预览您的模型,以确认模型是否按预期运行。
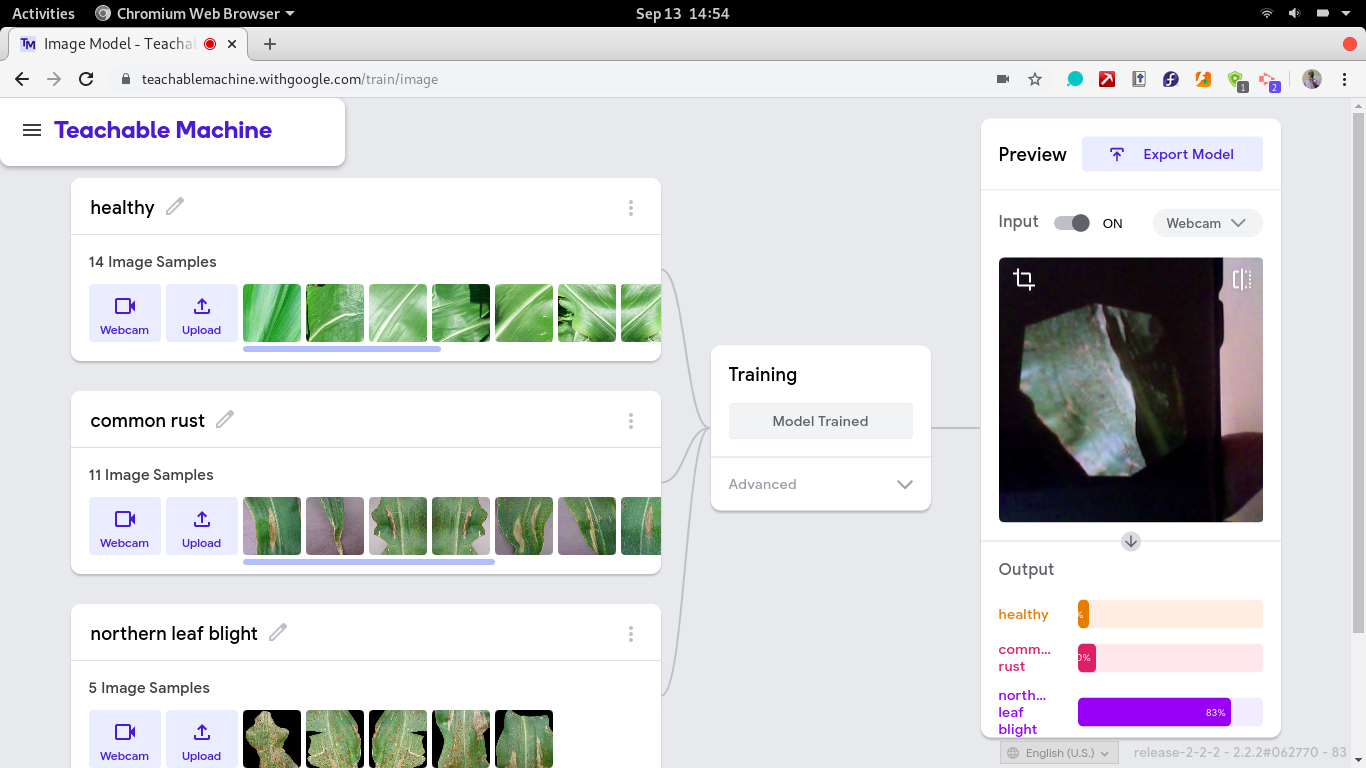
要在您的应用程序中使用该模型,您可以将其上传并在线托管,也可以下载模型权重。对于本指南,请下载模型权重文件。
Python 脚本
获得.h5格式的权重文件后,下一步就是开发一个脚本,该脚本将获取图像并使用模型预测图像所属的类别。以下是 Teachable Machine 团队提供的示例脚本。
import tensorflow.keras
from PIL import Image, ImageOps
import numpy as np
# Disable scientific notation for clarity
np.set_printoptions(suppress=True)
# Load the model
model = tensorflow.keras.models.load_model('keras_model.h5')
# Create the array of the right shape to feed into the keras model
# The 'length' or number of images you can put into the array is
# determined by the first position in the shape tuple, in this case 1.
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# Replace this with the path to your image
image = Image.open('test_photo.jpg')
#resize the image to a 224x224 with the same strategy as in TM2:
#resizing the image to be at least 224x224 and then cropping from the center
size = (224, 224)
image = ImageOps.fit(image, size, Image.ANTIALIAS)
#turn the image into a numpy array
image_array = np.asarray(image)
# display the resized image
image.show()
# Normalize the image
normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
# Load the image into the array
data[0] = normalized_image_array
# run the inference
prediction = model.predict(data)
print(prediction)
由于模型使用值进行预测,因此下载内容还包含一个文件,表示每个值代表什么。例如,0 可能代表类别 1,1 代表类别 2,依此类推。
结论
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~