
LSTM 与 RNN 中的 GRU 单元
介绍
门控循环单元 (GRU) 由Cho 等人于 2014 年提出,用于解决标准循环神经网络 (RNN)面临的梯度消失问题。GRU 具有许多与长短期记忆 (LSTM) 相同的属性。两种算法都使用门控机制来控制记忆过程。
有趣的是,GRU 比 LSTM 复杂度低,计算速度也快得多。在本指南中,您将使用比特币历史数据集,追踪 60 天的趋势以预测第 61 天的价格。如果您还不具备 LSTM 的基本知识,我建议您阅读《理解 LSTM》以简要了解该模型。
格鲁乌
什么使得 GRU 比传统 RNN 更特别且更有效?
GRU 支持门控和隐藏状态来控制信息流。为了解决 RNN 中出现的问题,GRU 使用了两个门:更新门和重置门。
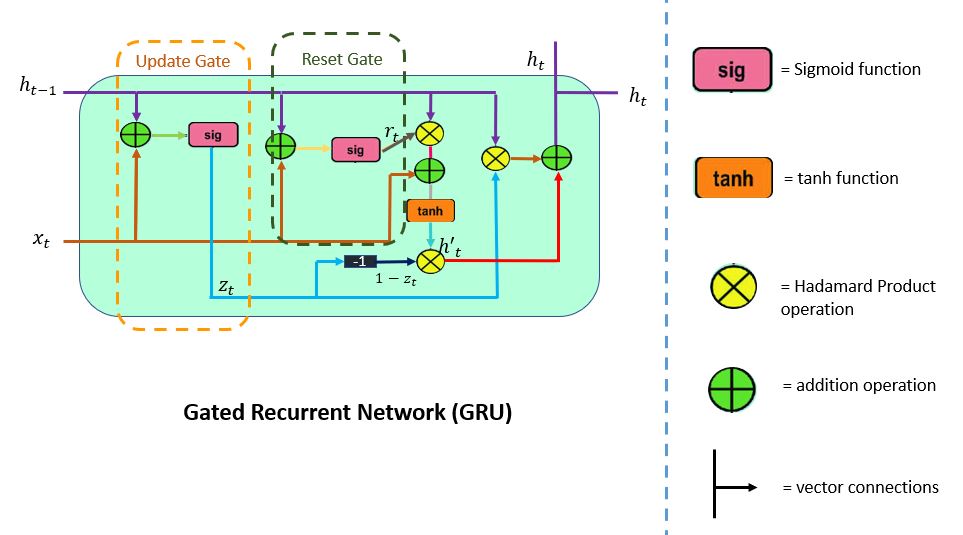
您可以将它们视为可以执行凸组合的两个向量条目 (0,1)。这些组合决定了哪些隐藏状态信息应该在需要时更新(传递)或重置隐藏状态。同样,网络学会跳过不相关的临时观察。
LSTM 由三个门组成:输入门、遗忘门和输出门。与 LSTM 不同,GRU 没有输出门,而是将输入和遗忘门合并为一个更新门。
让我们了解有关更新和重置门的更多信息。
更新门
更新门 (z_t) 负责确定需要传递到下一个状态的先前信息量(先前的时间步骤)。它是一个重要的单元。下图显示了更新门的布置。
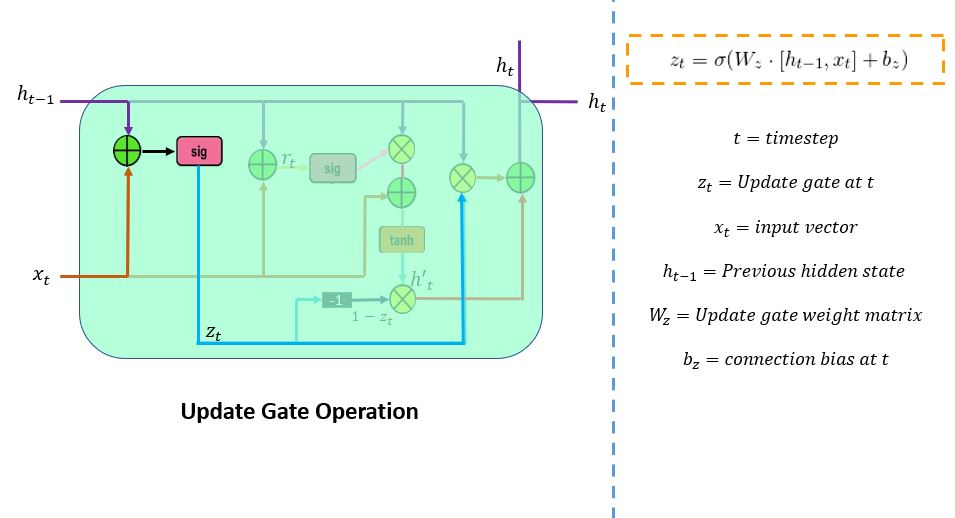
这里,x_t是网络单元提供的输入向量。它乘以其参数权重 ( W_z ) 矩阵。h (t_1)中的t_1表示它保存了前一个单元的信息,并乘以其权重。接下来,将这些参数的值相加并通过 S 型激活函数。这里,S 型函数将生成 0 到 1 之间的值。
重置门
重置门 ( r_t ) 用于从模型中决定需要忽略多少过去信息。其公式与更新门相同。它们的权重和门用法有所不同,这将在下一节中讨论。下图表示重置门。
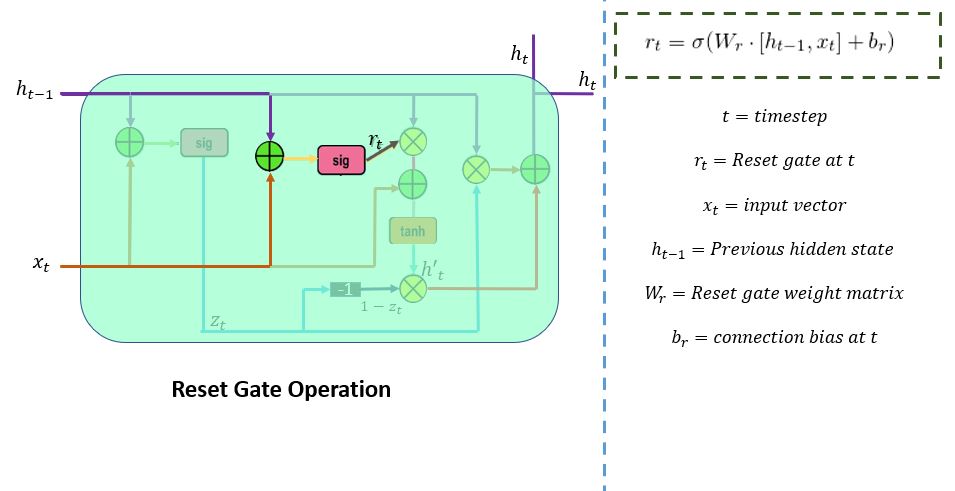
有两个输入,x_t和h_t-1。乘以它们的权重,应用逐点加法,然后将其传递给 sigmoid 函数。
盖茨在行动
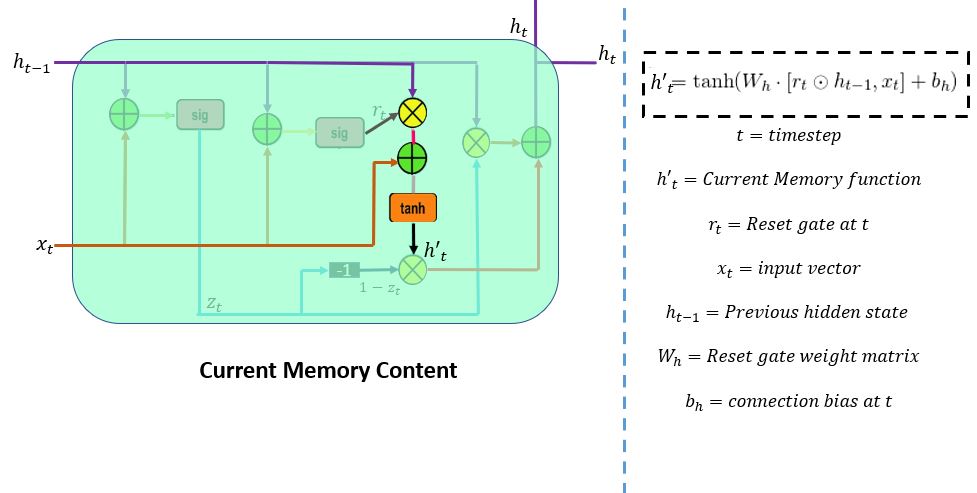
首先,重置门将过去时间步的相关信息存储到新的记忆内容中。然后它将输入向量和隐藏状态与其权重相乘。其次,它计算重置门和先前隐藏状态乘数之间的元素乘法(Hadamard)。总结后,将上述步骤的非线性激活函数应用于结果,并产生h'_t。
考虑这样一个场景:一位客户评论一家度假村:“我来到这里时已经是深夜了。”评论经过几行之后,以“我很享受这次住宿,因为房间很舒适。工作人员很友好。”为确定客户的满意度,您将需要评论的最后两行。模型将扫描整个评论直至最后,并分配一个接近“0”的重置门向量值。
这意味着它将忽略前面的几行而只关注最后一句。
请参阅下图。
这是最后一步。在当前时间步骤的最终内存中,网络需要计算h_t。在这里,更新门将发挥至关重要的作用。这个向量值将保存当前单元的信息并将其传递给网络。它将确定从当前内存内容(h't)和之前的时间步骤h(t-1)中收集哪些信息。元素乘法(Hadamard)应用于更新门和h(t-1) ,并将其与(1-z_t)和h'(t)之间的 Hadamard 乘积运算相加。
回顾度假村评论的示例:这次,预测的相关信息在文本开头提到。该模型会将更新门向量值设置为接近 1。在当前时间步骤中,1-z_t将接近 0,并且它将忽略评论最后一部分的块。请参阅下图。
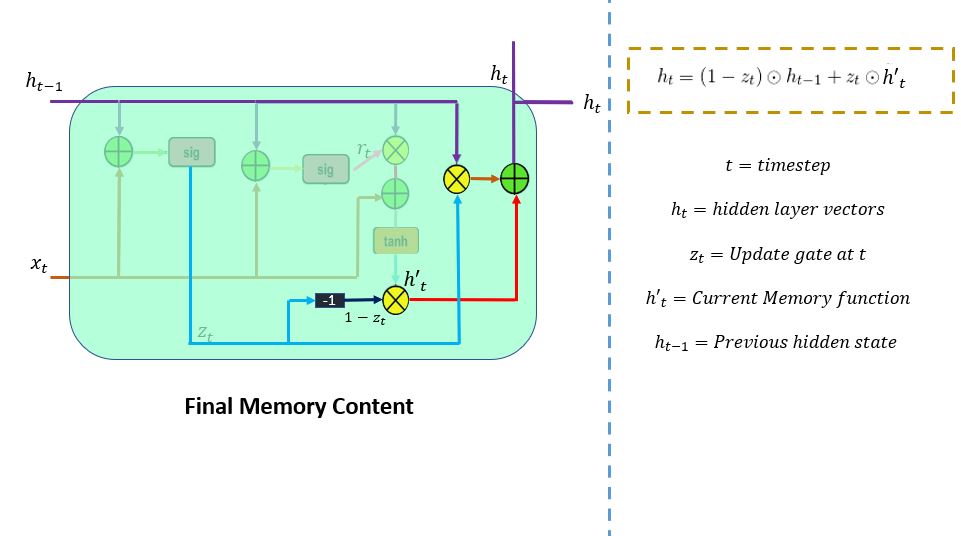
继续往下看,你会发现z_t是用来计算1-z_t的,然后和h't相加得到结果。h (t-1)和z_t之间做Hadamard乘积运算,乘积的输出作为输入,和h't进行逐点加法,得到隐藏状态下的最终结果。
代码实现
注意:在构建 GRU 模型之前,请参考本指南中导入重要库和数据预处理的代码。
从 Keras Layers API 中导入GRU层类、正则化层:dropout和核心层density。
在第一层中,输入为 50 个单位,return_sequence保持为真,因为它返回维度为 50 的向量序列。下一层的return_sequence将给出维度为 100 的单个向量。
from sklearn.metrics import mean_absolute_error
from keras.models import Sequential
from keras.layers import Dense, GRU, Dropout
mode = Sequential()
mode.add(GRU(50, return_sequences=True, input_shape=(x_train.shape[1],1)))
mode.add(Dropout(0.2))
mode.add(GRU(100,return_sequences=False))
mode.add(Dropout(0.2))
mode.add(Dense(1, activation = "linear"))
mode.compile(loss="mean_squared_error",optimizer="rmsprop")
mode.fit(x_train,y_train,epochs= 50,batch_size=64)

现在测试数据已准备好进行预测。
inputs=data[len(data)-len(close_test)-timestep:]
inputs=inputs.values.reshape(-1,1)
inputs=scaler.transform(inputs)
x_test=[]
for i in range(timestep,inputs.shape[0]):
x_test.append(inputs[i-timestep:i,0])
x_test=np.array(x_test)
x_test=x_test.reshape(x_test.shape[0],x_test.shape[1],1)
让我们将模型应用于测试数据。预测时间到了。
plt.figure(figsize=(8,4), dpi=80, facecolor='w', edgecolor='k')
plt.plot(data_test,color="r",label="true-result")
plt.plot(predicted_data,color="g",label="predicted-result")
plt.legend()
plt.title("GRU")
plt.xlabel("Time(60 days)")
plt.ylabel("Close Values")
plt.grid(True)
plt.show()
predicted_data=mode.predict(x_test)
predicted_data=scaler.inverse_transform(predicted_data)
data_test=np.array(close_test)
data_test=data_test.reshape(len(data_test),1)
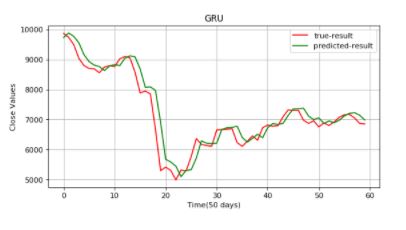
plt.figure(figsize=(8,4), dpi=80, facecolor='w', edgecolor='k')
plt.plot(data_test,color="r",label="true-result")
plt.plot(predicted_data,color="g",label="predicted-result")
plt.legend()
plt.title("GRU")
plt.xlabel("Time(60 days)")
plt.ylabel("Close Values")
plt.grid(True)
plt.show()
结论
总结一下,GRU 的表现优于传统 RNN。如果将结果与 LSTM 进行比较,GRU 使用的张量运算更少。训练所需的时间更少。然而,两者的结果几乎相同。没有明确的答案说哪种变体表现更好。通常,你可以尝试这两种算法,然后得出哪种效果更好。
本指南简要介绍了 GRU 及其用于过滤和存储信息的门控机制。模型不会淡化信息 - 它会保留相关信息并将其传递到下一个时间步骤,从而避免梯度消失的问题。LSTM 和 GRU 是最先进的模型。如果经过精心训练,它们在语音识别和合成、神经语言处理和深度学习等复杂场景中表现非常出色。
为了进一步学习,我建议阅读这篇论文,它清楚地解释了 GRU 和 LSTM 之间的区别。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!


































请先 登录后发表评论 ~