
数据素养要素:表示、处理和准备数据
介绍
如今,能够很好地理解原始数据是所有数据和业务专业人员的一项关键技能。接下来是选择正确的数据处理工具并处理数据质量问题,以便为商业智能和分析目的准备数据。在本指南中,您将了解不同类型的数据、数据表示类型、数据处理工具和数据准备过程,以使数据适合商业智能或数据分析用例。
数据类型
首先,您应该了解数据集的基本分类类别:
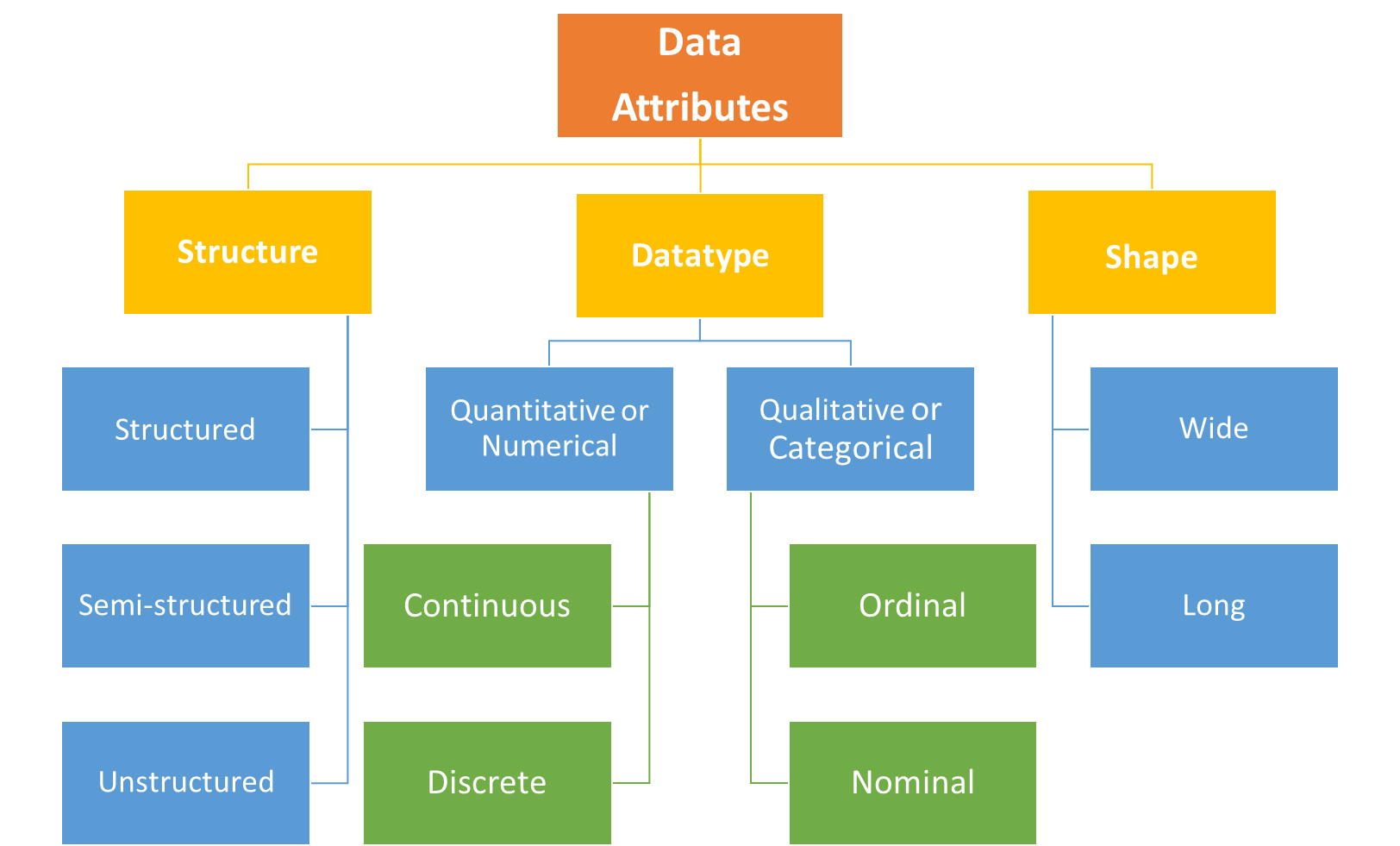
根据数据集的结构,可以将其分类为:
- 结构化数据——CSV 文件、数据库表等。
这种类型的数据是你最常遇到的数据,因为几乎所有交易系统和应用程序都使用关系数据库等结构化数据存储作为后端。由于结构化数据具有整个数据集遵循的架构/数据模型设计,因此处理起来相对容易。CSV 文件(逗号分隔值文件)使用逗号作为分隔符来分隔两个字段,从而分隔值。其他常用的分隔符是制表符、分号、竖线等。
- 半结构化数据 – JSON、XML、HTML
JSON 和 XML 是数据交换格式,主要由 API 生成和使用,用于数据交换或模块/系统间集成。JSON 采用键值对方法,而 XML 采用基于标签的结构。这些格式在数据结构方面更灵活,使用起来有点复杂。用于 Web 开发的 HTML 格式通常在需要抓取 Web 数据时遇到。例如,如果需要从 Wikipedia 网页获取数据表,则会抓取并解析网页的 HTML 代码以获取所需信息。
- 非结构化数据——文本、图像、音频
从各种来源(例如产品的客户评论、社交媒体帖子等)获得的自由格式文本以及音频/视频二进制文件不具有定义的结构。由于机器学习算法基于统计数据,因此非结构化数据需要进一步处理才能转换为数字格式,以便获得诸如主题检测、情绪分析、图像分割、对象检测、音频信号处理等见解。非结构化数据的硬件要求相当高——图像和音频文件的数据大小远大于结构化文本数据集,并且需要更多的处理能力。此类数据集是最复杂的,因为需要进行大量转换和繁重的处理。
根据数据类型,数据可分为:
- 定量或数值——连续、离散
与变量相关的数据(例如商品价格、个人身高/体重、订单数量等)被归类为数值数据。它也被称为因变量,因为数值本身没有意义,除非它们与定性或分类变量相关联以提供上下文。如果数值变量值来自精确的十进制刻度,例如,以厘米为单位的商品长度,则它们被称为连续变量。否则,它们被视为离散变量,例如下达的订单数量。
- 定性或分类——序数、名义
与性别、车辆颜色、国家名称等变量相关的数据被归类为分类数据,也称为独立变量。具有固有顺序的有序(或有序)变量,例如,分为高、中、低组的温度水平,称为分类变量。没有固有顺序的分类变量称为名义变量,例如,物品颜色之类的变量可以具有任何颜色值,而没有固有顺序。
数据集排列成行和列的方式称为数据的形状。
根据数据的形状,数据可以分为:
- 长数据
垂直或长数据集中的每一行代表属于特定类别/实例的一个观察结果。由于其本质上是精细的,因此更容易用于分析目的。每列都被视为具有多个不同值的变量,您可以通过这些变量获得某些见解并从数据集中准备报告。
- 宽数据
通常,报告以数据透视表等宽数据格式创建,其中对选定的分类变量进行统计测量。与长数据相比,聚合数据存储在不同的分类变量中,而不是每行中的单个观察值。它本质上是粗略的,因为通常不存在单位级或粒度数据。
表示数据
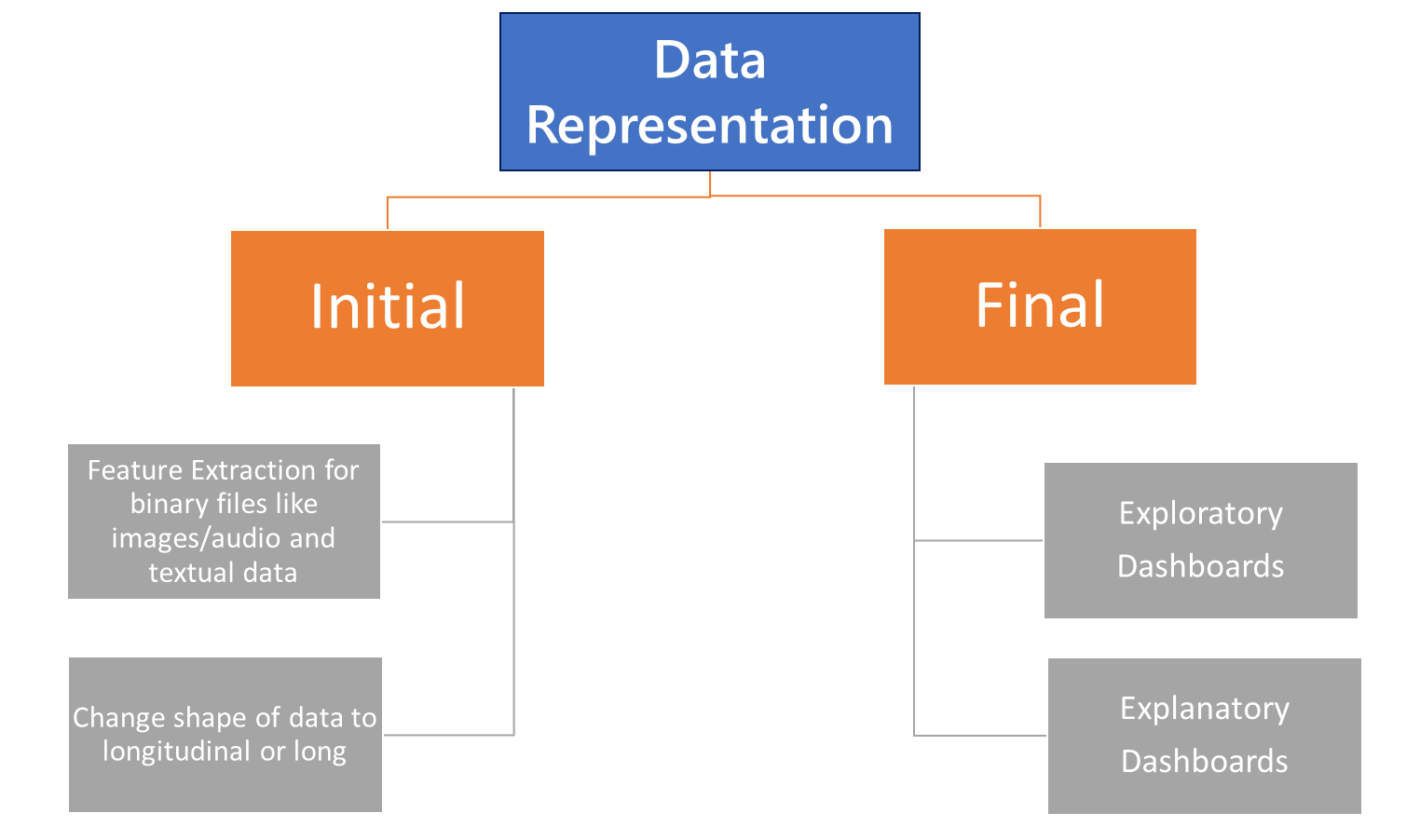
在商业智能或数据分析生命周期中表示数据有两个阶段:
初始表示阶段
原始数据集必须以机器学习算法和/或商业智能工具可以使用的格式表示。例如,在机器学习中的图像处理用例中,图像需要表示为 3D 数字矩阵,因为机器学习算法只能处理数值。另一个挑战来自分类值,使用独热编码、标签编码等编码技术将其转换为数值。对于自由格式的文本数据,使用多种不同的自然语言处理 (NLP) 技术将文本转换为数字向量。这在机器学习中也称为特征工程。
对于 BI 工具,数据最好采用垂直或长表示形式。这些工具还提供了在工具内部取消透视数据的功能。
最终陈述阶段
在最终的表示阶段,洞察力通过可视化以直观的方式呈现。某些类型的洞察力的一些基本视觉表示选项包括:
- 比较 – 条形图、柱状图
- 构成——树状图、饼图
- 分布 – 直方图
- 关系 – 散点图
根据用户级别,仪表板可以:
- 探索性
对于需要对数据进行切片/切块和过滤、执行假设分析等功能的分析师来说,这是首选方法,作为仪表板的一部分来进一步探索数据。
- 解释性
对于需要以直观的方式获得可操作见解以便制定政策或监控业务绩效且交互性最低的高级官员来说,这是一种首选方法。
处理数据
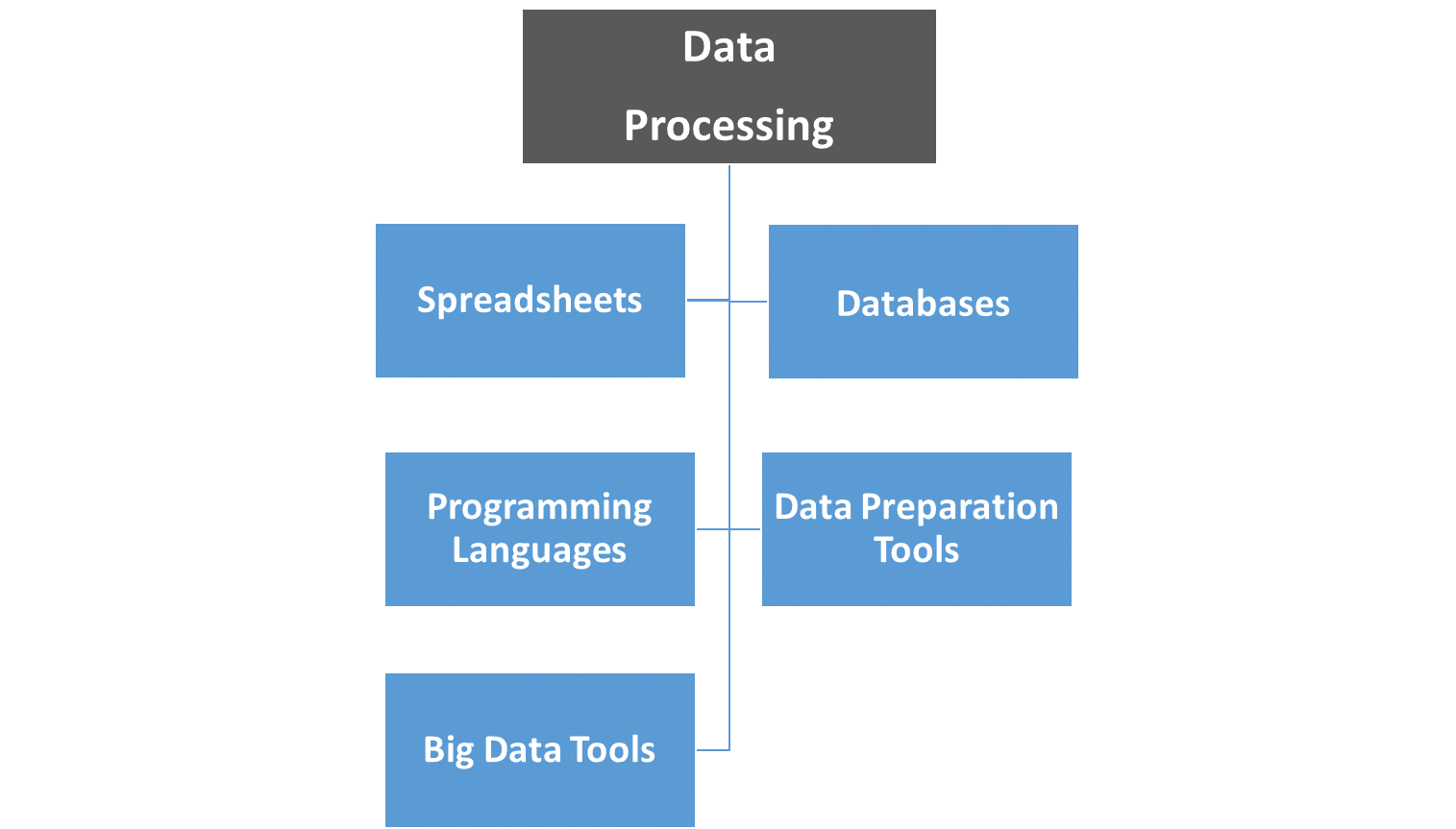
根据数据类型、数据大小、用例和底层硬件/软件的可用性,有多种数据处理技术可供选择。根据需求,可以单独使用其中任何一种,也可以混合使用。
- 电子表格 — Excel、Google Sheets 等。
用例:如果数据量很小(Excel 工作表最多可处理 100 万条记录),则所需的数据转换不会太复杂,并且不必担心数据的安全性/管理。
- 数据库 – SQL、NoSQL 等。
用例:如果数据量较大,需要将数据存储在更可靠的存储中。数据库还提供对数据管理和安全方面的控制。
- 编程语言——Python、R、VBA 等。
用例:自动化转换工作流程、数据工程管道、更好的转换能力、宏、预测分析等。
- 数据准备工具–Alteryx、Tableau Prep等。
用例:企业级数据处理、基于 GUI 的转换工作流开发和自动化、自助服务分析等。
- 大数据工具——Hive、Impala 等。
用例:数据量非常庞大,需要低延迟存储/检索/转换。
准备数据
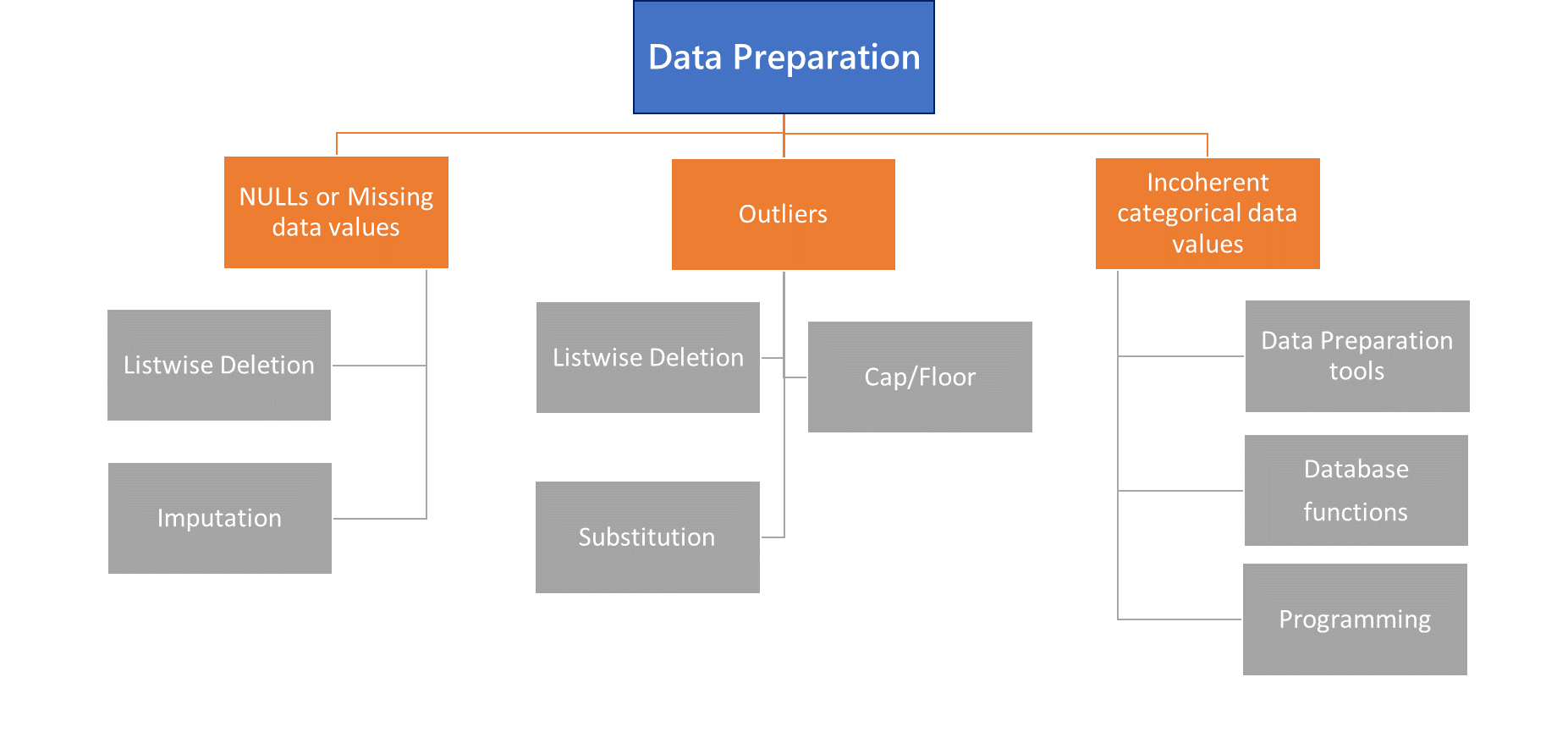
需要进行数据准备,以清理数据并将其转换为适合商业智能或数据分析的格式。通常遇到的数据质量问题包括:
NULL 或缺失数据值
大量缺失数据值或 NULL 会导致歧义并影响机器学习中的模型开发。有两种方法可以处理缺失数值。
- 列表删除
可以删除变量的具有 NULL 值的完整记录/行,但如果数据不是随机缺失的,这可能会导致偏差,并且可能在机器学习用例中显著减少样本量。
- 归责
可以使用均值替换、插值和预测等技术来填充 NULL,但每种技术都有自己的假设和含义。例如,均值替换会削弱变量之间的相关性,而预测值可能会增强相关性。
异常值
偏离平均值一定标准差的数值称为异常值。根据用例,偏离平均值超过 3 个标准差可视为识别异常值的阈值,在某些情况下甚至为 1.5 个标准差。异常值实际上可能是有效值,但也可能是错误输入的结果。要处理异常值,可以使用以下三种技术中的任何一种:如有错误则丢弃、上限/下限设置为上限值或用平均值进行估算。
不一致的分类数据值
分类值遇到的问题包括不规则字母大小写、拼写错误或非标准输入、字符串中使用的数字字符(如 O 为零)、尾随或前面的空格。根据所使用的处理媒介,有多种技术可以解决这些问题。例如,数据库中有“ISALPHA()”、“TRIM()”、“UPPER()”、“LOWER()”等函数可用于处理此类问题。Alteryx 和 Tableau Prep 等工具有多个专门用于清理分类数据的模块。无效的日期和时间值也可以使用此类技术和工具来处理。
结论
在本指南中,您了解了商业智能和数据分析领域中使用的表示、处理和准备数据的基本概念。这些概念将在您的数据素养之旅中发挥重要作用。如需进一步学习,请随时参加这门精彩的课程。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~