
使用 TensorFlow 2.0 进行艺术神经风格迁移,第 1 部分:理论
介绍
每个人都喜欢艺术,但并非每个人都有创造艺术的天赋。但是,如果你了解深度学习,那么你就不需要知道如何画毕加索的画。你可以简单地使用深度学习将任何图像转换为毕加索风格的图像。
本指南系列将使这种可视化成为可能!您将了解 CNN 如何自动将一个图像的风格映射到另一个图像上。您将使用具有特定艺术风格的图像为您选择的照片赋予毕加索风格。
这是两部分系列指南中的第一部分。本指南将介绍图像的预处理,以及 VGG 模型、中间层和成本函数的说明。
第二篇指南将讨论风格损失和内容损失。它还将简要解释变异损失函数和优化如何帮助生成 AI 艺术作品。
让我们首先深入了解一下 VGG 模型到底是什么。
关于 VGG
在涉及数百层的深度神经网络中,您会面临严重的梯度消失问题,即模型的准确性会随着层数的增加而降低。因此,引入了ResNet、DenseNet、VGG-Net等高效网络。为每个问题从头开始构建密集神经网络非常困难且非常耗时,而 ResNet、DenseNet 和 VGG-Net 是一些非常成功的先进网络。
本指南使用预先训练的 VGG-19 模型。预先训练的模型是使用迁移学习技术构建的,其中模型使用知识来解决问题(例如识别船只)并将其应用于相关但相似的问题(识别船舶)。
VGG-Net 模型可以使用浅层(较早的层)识别低级特征,使用较深的层识别高级特征。下图显示了 VGG-19 网络的层结构:
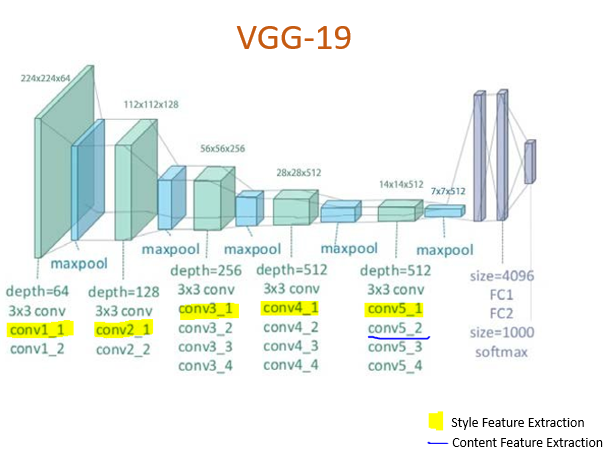
VGG 架构
现在您了解了 VGGNet-19 模型的构建模块。其变体的架构如下图所示。
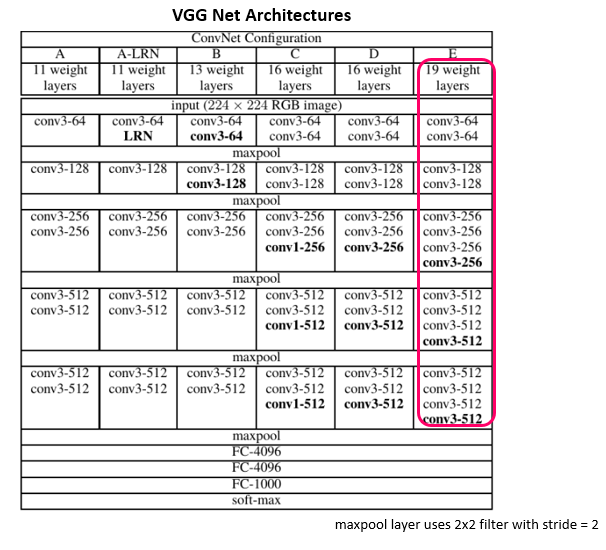
该模型不使用步幅较大的大型滤波器,而是使用较小的滤波器。例如,三个3x3 卷积层将包含三个非线性整流层,而不是一个7x7 卷积层。这将有助于决策函数学习更多特征。此外,3x3 层的堆叠将减小权重的大小,使模型更不容易过度拟合。
代码实现
现在,访问 TensorFlow 2.0。在将图像输入 VGG 模型之前,对其进行预处理非常重要。大多数图像都在 numpy 数组中,模型以张量的形式接受图像。PIL 库将完成这项工作。
import tensorflow as tf
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12,12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tf_input):
tf_input = tf_input*255
tf_input = np.array(tf_input, dtype=np.uint8)
if np.ndim(tf_input)>3:
assert tf_input.shape[0] == 1
tf_input = tf_input[0]
return PIL.Image.fromarray(tf_input)
#input image of your choice
content_path = 'houses.jpg'
style_path = 'Picasso.png'
在艺术神经风格转换中,我们使用三幅图像:
- 内容图片(应用了样式的图片)
- 样式图像(用作样式的图像)
- 生成的图像(原始图像,将包含样式化的内容图像)
请随意在上面的代码片段中提供内容和样式图像的路径。
可视化输入
选择图像后,对其大小、形状和尺寸进行预处理。
def load_img(image_path):
max_dim = 512
img = tf.io.read_file(image_path)
img = tf.image.decode_image(img, channels=3)#Detects the image to perform apropriate opertions
img = tf.image.convert_image_dtype(img, tf.float32)#converts image to tensor dtype
shape = tf.cast(tf.shape(img)[:-1], tf.float32)# Casts a tensor to float32.
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
return img[tf.newaxis, :]
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content-Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style-Image')

现在,在这种情况下,生成的图像将针对内容图像的元素,即,它将具有房屋和湖泊,但以风格参考图像的风格“绘制”。
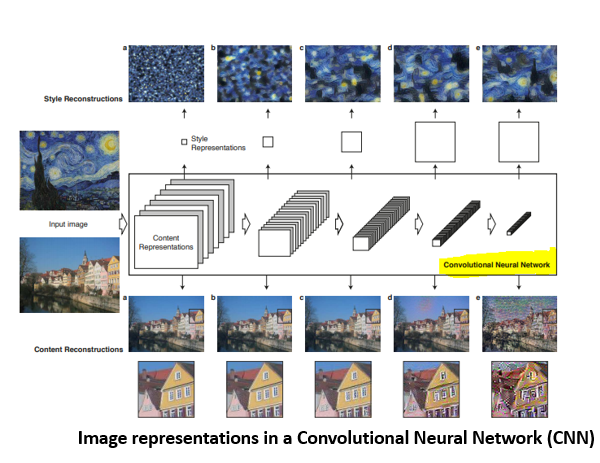
定义内容和样式表现
中间层对于定义图像中内容和风格的表示是必不可少的。对于输入图像,尝试在这些中间层上匹配相应的风格和内容目标表示。
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)

风格和内容的中间层
VGG 中的卷积层负责分离图像的风格和内容。您将使用不同的中间层来提取内容和风格信息。
对于内容层,使用块 5 中的第二个卷积层block5_conv2。考虑到网络中较深的层会捕获输入图像中的对象及其排列,因此这些是提取起来比较复杂的特征。在 CNN 的最后几层附近,可以找到最佳特征。
对于样式层,使用每个层块中的第一个卷积层,即block1_conv1至block5_conv5。CNN不断学习特征。在多个层中,检测到不同的模式。起始层将检测简单的对角线、第一层边缘,然后是某些模式,依此类推。
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
建立模型
加载预先训练的 VGG,在 Imagenet 数据上进行训练。
def vgg_layers(layer_names):
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
tf_outs = [vgg.get_layer(layer).output for layer in layer_names]
model = tf.keras.Model([vgg.input], tf_outs)
return model
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, tf_out in zip(style_layers, style_outputs):
print(name)
print(" shape: ", tf_out.numpy().shape)
print(" min: ", tf_out.numpy().min())
print(" max: ", tf_out.numpy().max())
print(" mean: ", tf_out.numpy().mean())
print()

该模型已准备好将艺术家的绘画笔触(风格)结合到您选择的图像(内容)上。该模型将通过计算成本函数并减少损失来进行优化。
成本函数
在风格迁移中,神经网络无需训练。相反,它的权重和偏差保持不变,并通过更改/修改像素值来更新图像,直到成本函数达到优化(减少损失)。它确保内容图像中的“内容”和风格图像中的“风格”都存在于生成的图像中。

结论
这是第 1 部分的结尾。下一篇指南将深入讨论损失(成本函数的一个组成部分)以及如何使用 NN 创建艺术风格图像。
现在,您已经了解了 VGG-19 网络和用于生成艺术图像的成本函数。您还了解了如何使用中间层从图像中提取内容和风格。
点击此处继续阅读本系列的第 2 部分。
欲了解更多详情,请在这里联系我。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~