
使用 Google Cloud 训练自定义机器学习模型
介绍
机器学习很难。你必须选择一种算法,设置超参数,训练模型,测试模型等等。大多数机器学习需求都属于一组预定义的类别,例如对象检测和情绪分析。有许多服务可以通过 REST API 以少量费用提供对大型预训练模型的访问,这些服务在许多情况下都足够了。但是,如果你的数据来自那些模型未接受过训练的细分领域,该怎么办?
Google Cloud AutoML
当您需要根据特定业务数据训练模型时,请查看 Google Cloud AutoML。使用 Google Cloud AutoML,您可以向 Google 提供一组训练数据,告诉 Google 您需要解决什么类型的问题(例如对象检测或情绪分析),然后单击按钮来训练模型。除了输入和输出之外,您不需要了解有关对象检测或情绪分析的任何信息。
Google Cloud AutoML 支持许多常用的机器学习场景:
- 自然语言处理——涉及文档分类、实体提取和文本主体的情感分析。
- 计算机视觉——这涉及物体检测和图像分类。
- 视频智能——涉及视频中的分类和对象跟踪。
- 翻译——这涉及将文本从一种语言翻译成另一种语言。
何时使用 Google Cloud AutoML
每当您需要扩展 Google Cloud AI 服务的功能时,Google Cloud AutoML 都非常有用。Google Cloud 已经为计算机视觉提供了 REST API。您可以上传图片,然后 Google 会返回图片中的内容预测,例如泰迪熊或山脉。
有些情况需要更具体的结果。例如,机械车间可能希望实现轮胎检查自动化。员工无需经历漫长而主观的手动检查轮胎磨损和损坏的过程,而是可以用移动设备拍摄轮胎照片,然后让机器学习模型确定轮胎的损坏类型和损坏程度。
如果您拍摄轮胎的照片并将其上传到 Google Cloud Vision API,它很可能会识别出图像中的轮胎。但它能区分好轮胎和损坏的轮胎吗?可能不会。而且它肯定无法预测轮胎损坏的严重程度。
机械师需要的是一个基于完好轮胎和损坏轮胎图片进行训练的机器学习模型。通过向 Google Cloud AutoML 提供一组这些图片,机械师只需告诉 Google 训练一个分类模型即可。Google Cloud AutoML 会尝试不同的算法,找到效果最好的算法,并使用该算法训练模型。模型训练完成后,即可自动部署。
情绪分析
让我们看一下常见的机器学习任务——情感分析,以及如何使用 Google Cloud AutoML 训练自定义模型。
首先,你需要一些数据。Google Cloud AutoML 可能需要很长时间才能训练出一个模型,最多可能需要几个小时。因此,在本指南中,我将使用尽可能小的数据集。用于情绪分析的流行数据集是来自互联网电影数据库 (IMDB) 的一组电影评论。由于获取数据的过程超出了本指南的范围,我将让读者参考这个Github Gist。它将下载数据集的文件并将它们组合成训练数据集和测试数据集。你可以在本地或 Google Colab 中运行它,并将文件下载为 CSV。
接下来,在 Google Cloud Platform 控制台中,向下滚动左侧的侧边栏,直到到达人工智能部分并点击自然语言。在下一页中,您可以选择要训练模型的自然语言问题类型。单击AutoML 情感分析下的开始链接。
点击左侧的数据集链接,弹出导入到自然语言服务的数据集列表,然后点击页面顶部的新建数据集链接。
- 为新数据集命名。我将使用ps-guide-nlp。
- 对于模型目标,选择情感分析。
- 这将显示“情绪量表”部分。它允许您指定情绪分数的上限。最小值始终为 0,即最负值。由于 IMDB 数据集使用 1 作为上限,因此保留默认值。
- 单击创建数据集按钮。
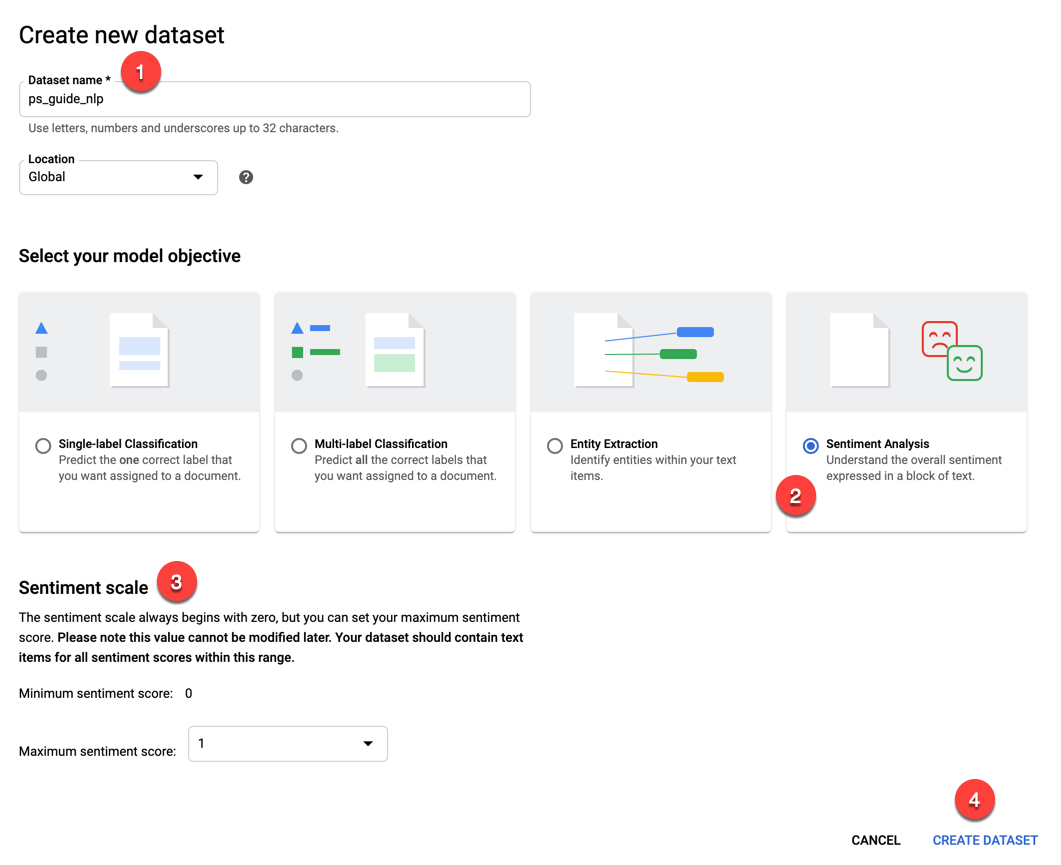
在下一页的“导入”选项卡下,您将选择如何将 Gist 生成的 CSV 文件导入 Google Cloud。您可以上传 ZIP 文件或使用已上传到 Google Cloud Storage 的文件。但在这种情况下,选择第一个选项从本地计算机上传 CSV (1)。单击“选择文件”按钮 (2) 导航到 CSV 文件,然后单击“浏览”按钮 (3) 选择 Google Cloud Storage 中的目标存储桶。单击“导入”按钮 (4) 上传 CSV 文件并将其存储在 Google Cloud Storage 中。

导入过程可能需要一些时间。对我来说,大约需要 15-20 分钟。预计一段时间后才会看到此进度条。
正如消息所述,导入后您将收到一封电子邮件。
导入完成后,您可以在“项目”选项卡下查看导入的项目和一些统计信息。
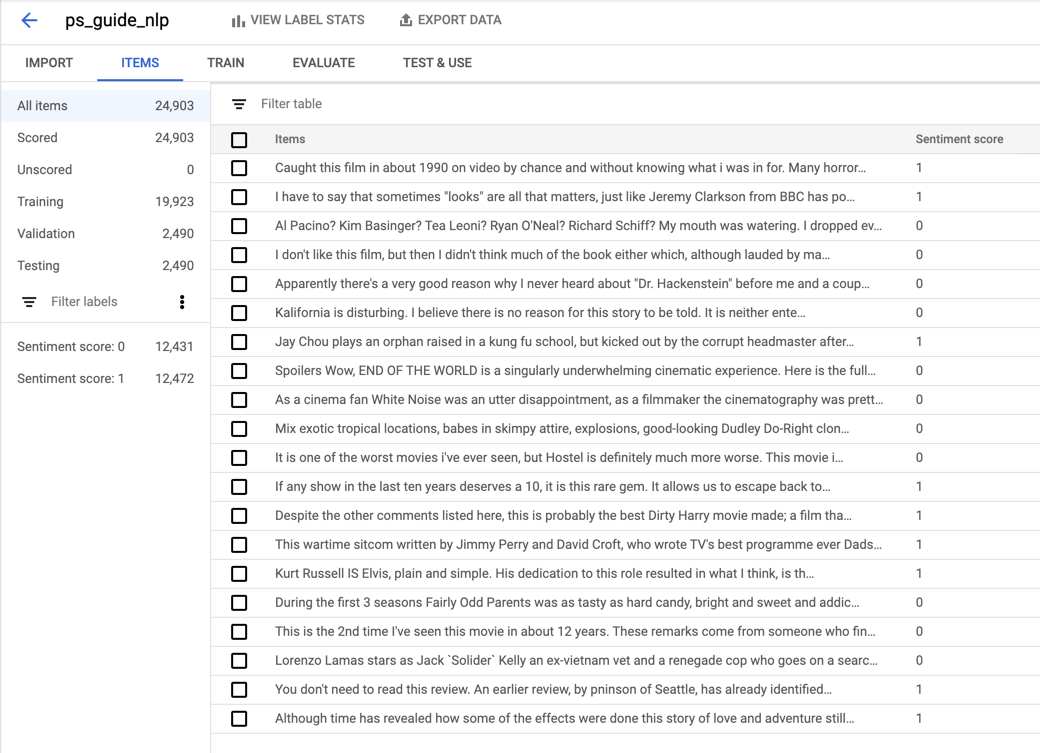
如您所见,每件商品都有评论和情绪分数。情绪分数为 0 或 1,其中 0 表示负面,1 表示正面。导入的数据集包含近 25,000 件商品,情绪分数分布均匀,每件商品约占数据集的一半。
在“训练”选项卡下,单击“开始训练”按钮。
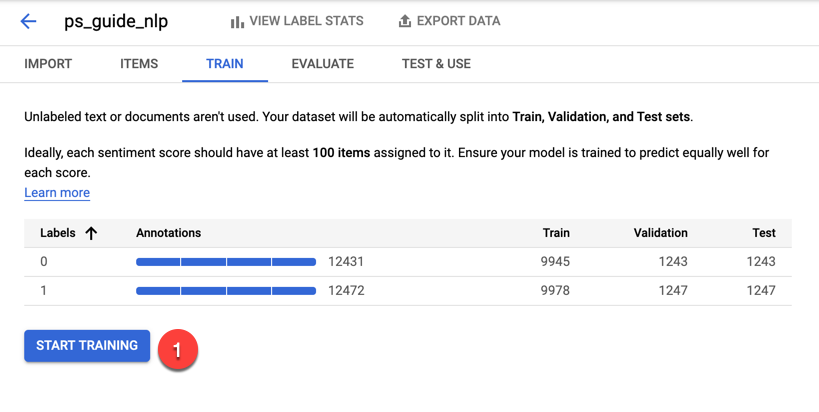
在右侧打开的面板中,取消选中自动部署模型的框,然后单击开始训练按钮。
训练完成后,您可以在“评估”选项卡下查看结果。
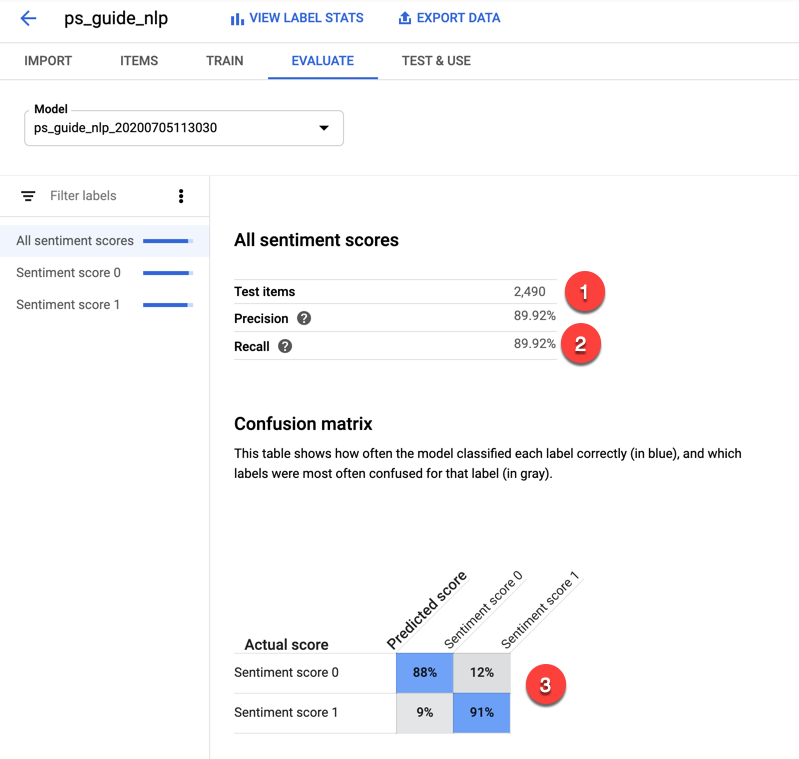
Google Cloud AutoML 使用大约 10% 的数据集进行测试 (1)。本指南不详细讨论准确率和召回率,但该模型在这两个方面的得分相对较高,因此该模型的假阳性和假阴性预测较少 (2)。混淆矩阵 (3) 显示正确预测与错误预测的比率。如果对角线上的百分比较高,则表示模型表现相对较好。
在“测试和使用”选项卡下,您可以部署模型。单击“部署模型”链接,然后再次...等待。(这是最后一次,我保证。)
部署模型后,您可以在文本框中输入文本,并获得预测结果:0 表示负面情绪,1 表示正面情绪。首先,尝试一条负面评论。
“我从来没看过这么垃圾的东西!”
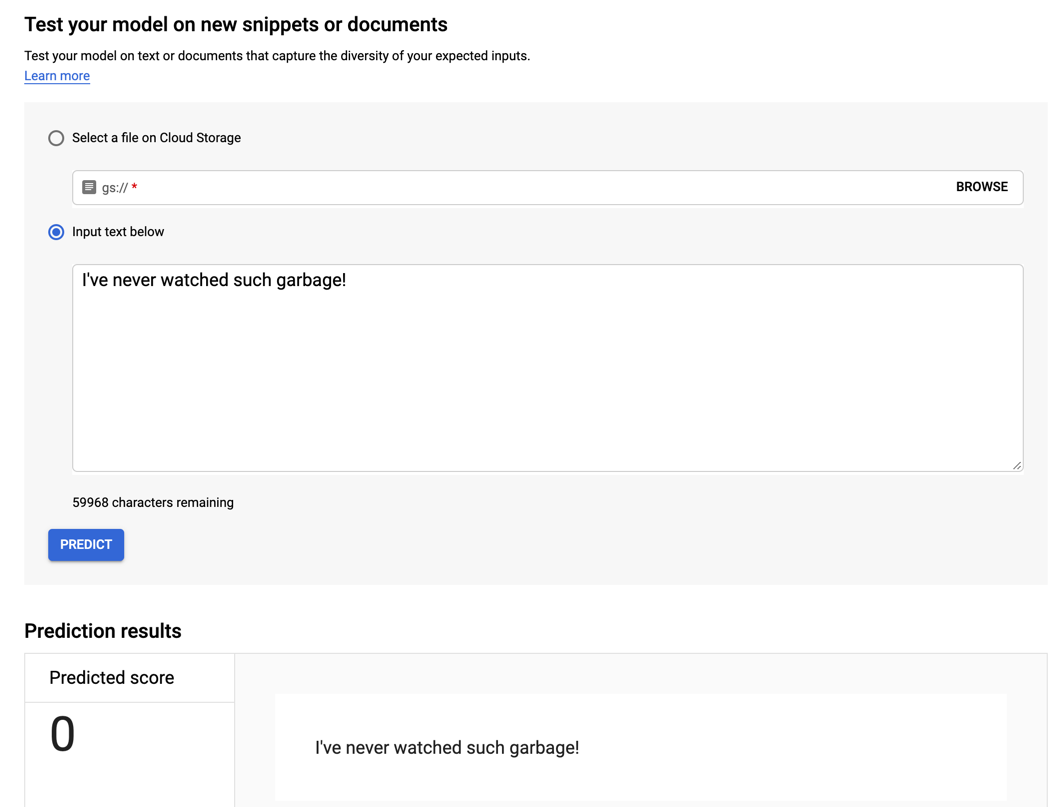
虽然我听过更糟糕的评论,但这绝对是负面的,模型也证实了这一点。
正面评价怎么样?
“这部电影让我感觉很温暖、很温馨!”
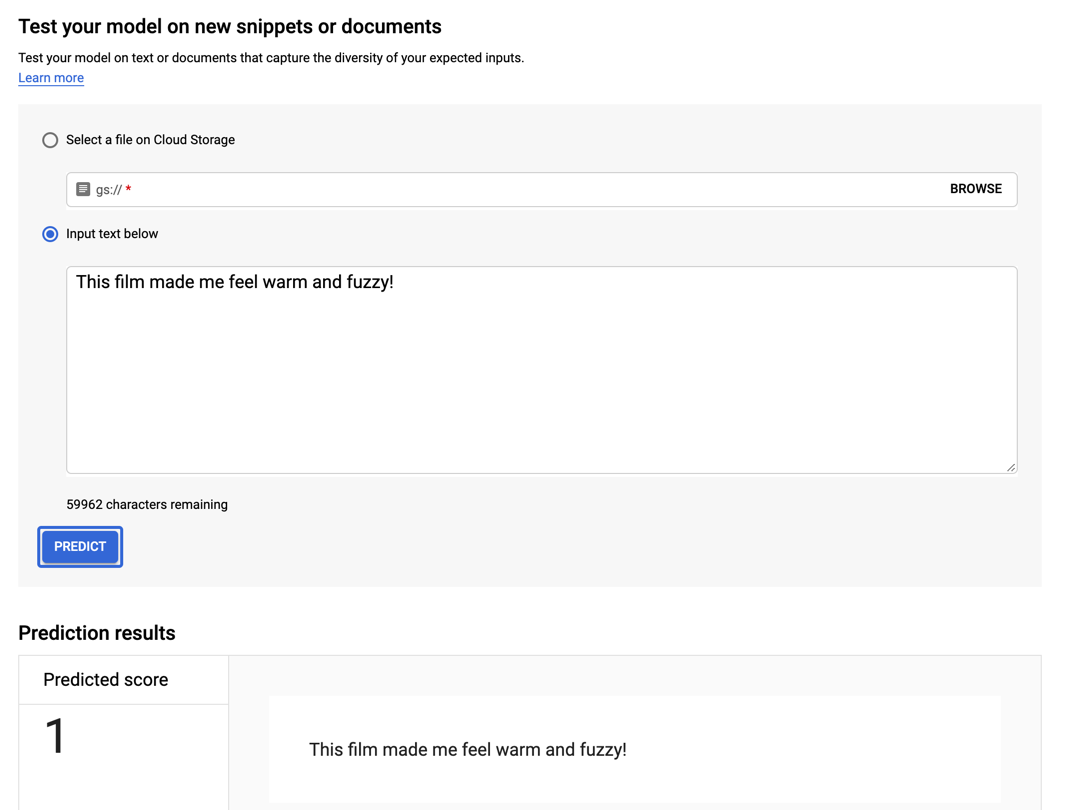
并且该陈述使模型产生了积极的预测。
预测结果下方是通过 REST API 和示例 Python 代码获取预测的说明。此外,完成后请务必删除部署,以免被收费。
结论
显然,使用 Google Cloud AutoML 最困难的部分是等待。但那是你不必花时间尝试、训练和评估的时间。而且你不需要有任何先决条件的机器学习背景就可以做到这一点。它不像 Google Cloud Vision API 这样的服务那么便宜,但它也更专用。你在灵活性方面获得的回报是你需要额外支付的。同时,它是在时间冻结的通用模型和从头开始构建自己的解决方案之间的一个很好的解决方案。感谢阅读!
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~