
使用 Apache Kafka Streams 进行数据流管理
介绍
Apache Kafka是一个分布式流媒体平台,在处理来自各种来源并输出的大量传入数据时有效且可靠。
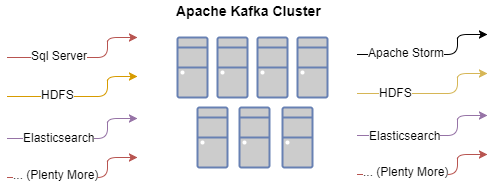
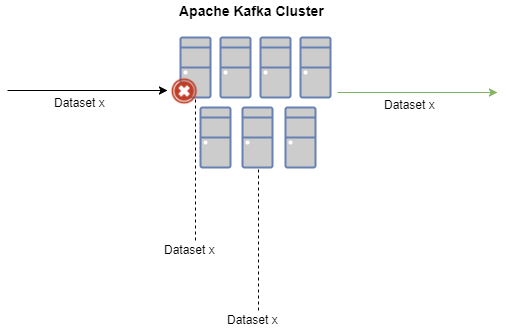
当使用适当的部署和配置方案使用 Kafka 时,我们宝贵的输入数据将在多个节点上复制,确保我们的集群在发生灾难(例如某个节点出现硬件故障)时能够正常运行。
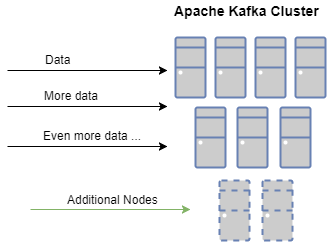
鉴于各种输入率,我们还可以轻松扩展我们的集群以适应我们不断变化的需求。
Apache Kafka(从现在开始我将省略“Apache”,但我始终指的是官方的 Apache Kafka 版本)使所有这些“现实生活”问题变得容易解决,而且它高效而快速地完成。
简而言之,Kafka 能够以容错和可扩展的方式有效管理可变速率的传入数据。
在我看来,这听起来像是工具箱中的一个很棒的工具!
Kafka Streams是一个客户端库,它为底层 Kafka 集群提供抽象,并允许在托管客户端上执行流操作。为我们提供的抽象默认是负载平衡的,这使得它成为几个用例的有趣候选者。
听起来很有趣?那我们开始吧!
批处理?实时处理?有什么新东西吗?
过去十年甚至更久以来,数据世界发生了巨大的变化。
数据曾经只存在于单台机器上;现在它在多台机器、计算机网络甚至网络域(托管在多个数据中心)上共享。
简而言之,数据管理系统已经从集中式变为广泛分布式。
随着分布式架构变得越来越普遍,多个软件领域也不断发展和成熟。这些变化现在使我们能够提供高度可扩展和容错的软件解决方案,同时在解决问题时也考虑了更多方面,例如并发性、分布式事务等。

我刚才提到的用例肯定会受益于使用 Kafka Streams。
在第一个用例中,我们可以使用 Kafka Streams 来使用存储在我们的(例如 HDFS 卷)存储中的数据并将其传递给工作程序,然后工作程序将对其进行计算。
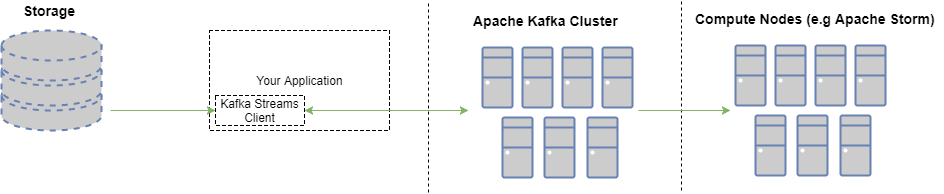
在第二个用例中,我们可以使用 Kafka Streams 为所有传入数据创建丰富机制。例如,向传入事件数据添加唯一的系统 ID 或将上下文对象附加到传入事件数据。
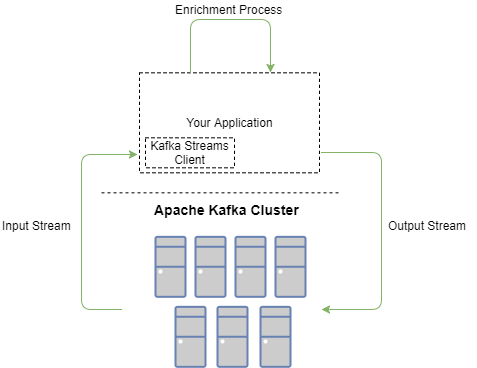
在我们查看其他用例和代码示例之前,让我们首先回顾一下 Kafka Streams API 的功能。
包装内容
好,我们先说盒子。
对于 Kafka Streams 来说,“盒子” 和您已经知道并熟悉的“盒子” 是一样的。Kafka Streams 是 Kafka 中自最近几个版本以来集成的一项功能。无需单独下载。下载即可获得所需的一切。
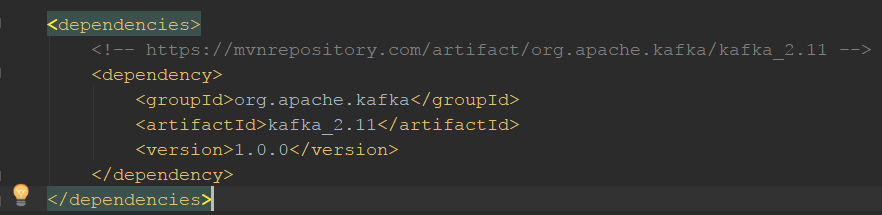
通过任何 Java 应用程序访问 Streams API 非常简单,只需以任何“标准”所需方式添加相关依赖项(例如 maven、gradle 甚至直接 jar 依赖项)。在下面的屏幕截图中,您可以看到一个示例 Maven 依赖项:
现在,它作为一个标准 Java 库实际上意味着您的开发环境以及部署目标仅受目标托管 JVM 的能力的限制。换句话说,您几乎是无限的 :-) 。Windows、Mac 和 Linux 很乐意直接或在容器(如Docker)中托管和运行您的应用程序。
Streams API 客户端将托管在你的应用程序中,但需要注意客户端的另一个方面 - 所有计算都是在客户端托管应用程序内部而不是 Kafka 集群中完成的。记住这一点非常重要,所以我再重复一遍:
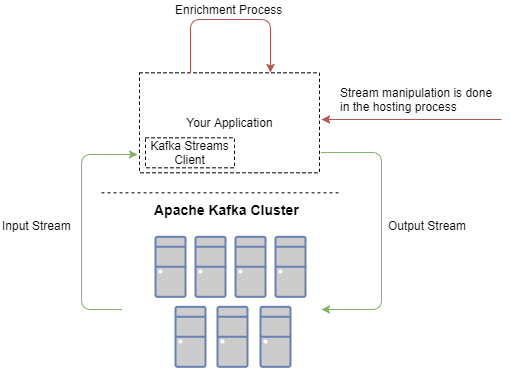
Kafka Streams 客户端在您的应用程序内部而不是 Kafka 集群中执行所有工作。
为什么会这样?很简单,因为你的 Kafka 集群已经够忙了 :-)。
因此您可能会问我,使用 Streams 客户端是否会产生额外的开销。
是的,有开销。
然而,在许多情况下,该开销将取决于您处理数据的具体方式,并且可以保持在最低限度。
除了易于开发和部署之外,正是因为所有计算都在客户端应用程序上执行,所以Kafka Streams 应用程序不需要专用的计算集群(例如Apache Spark)。你所做的只是指向现有的 Kafka 集群并定义你想要执行的(数据)转换和丰富。
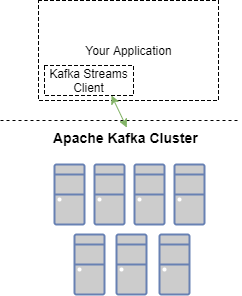
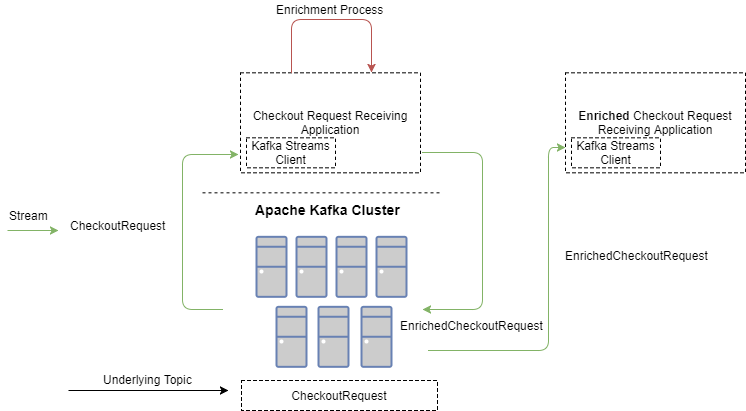
在下面这张图中,你可以看到,客户端应用程序定义了一个来自主题“CheckoutRequest”的消息流。然后,它用附加数据丰富请求,并将其传递到传出流“EnrichedCheckoutRequest”,以便由监听“EnrichedCheckoutRequest”流的进程进行进一步处理。
可扩展、容错、安全
考虑使用 Kafka Streams 时要考虑的另一点是,它符合 Kafka 的可扩展性、容错性和安全性的承诺。
由于所有数据都由相关 Kafka 主题中的 Kafka 集群进行管理,因此我们可以享受 Kafka 在安全管理数据方面的成熟度。
精确一次处理
这些似乎都是使用 Kafka Streams API 的很好的理由。不过,我把最好的留到了最后。
使用Kafka Streams的最新版本,您将享受一次性处理语义系统。
分布式消息传递系统有多种语义。我将列举最常见的几种:
- 至少一次
- 最多一次
- 恰好一次
我现在要解释的是,假设我们集群中的所有 Kafka 主题,即使处于故障状态,最终都将变得可用。

通过至少一次处理,我们可以确保任何给定的消息至少会到达消费者一次(顾名思义)。消息到达消费者不止一次可能是由于生产者重试创建未确认的消息,尽管其他情况也可能有效。

使用最多一次,我们基本上是发送一条消息,并且可能(由于集群问题)认为它已被发送,即使它还没有安全到达目的地。

但只有使用“恰好一次”才能确保消息到达消费者并被消费者确认一次,且每个流消息仅确认一次。
这是分布式消息系统中最强大的功能。它让开发人员可以自由思考任务,并简单地假设传输的流消息将到达流消费者。
如此强大的一次性处理语义为 Kafka 提供了更多的用例 - 在 Kafka 之前,这些情况会迫使我们“保护”我们的条目以防止重复的消息处理,或者额外的重试机制以确保所有消息都已成功传递。
有关 Apache Kafka 的更多概述(包括生产者和消费者)以及示例代码,请查看我的 Pluralsight课程。
让我们来讨论一下这样的用例。
您的软件平台的进程间通信基础设施
我想到第一个用例(对我来说)是为您的软件平台服务提供可扩展且可靠的进程间通信机制。
首先想到的进程间范例是最流行的发布者/订阅者机制。
这种模式允许我们让一个或多个微服务将消息生成到 Kafka Stream 中(例如“PrintRequest”)。然后,其他微服务将使用该 Stream。
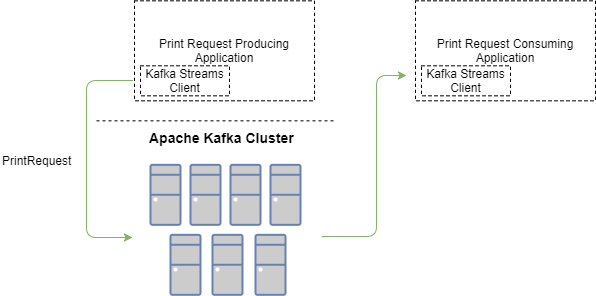
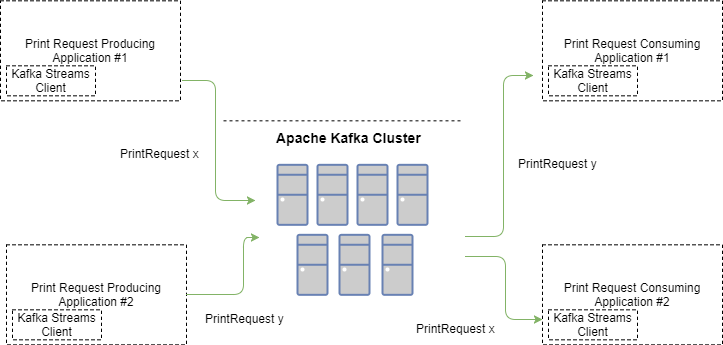
这样,Kafka Stream“PrintRequest”就可以拥有多个生产者和多个消费者。利用“恰好一次”语义,我们可以确保任何“PrintRequest”消息只会向正确的消费者传递一次。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~